 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Effective Demonstration Annotation for In-Context Learning via Language Model-Based Determinantal Point Process
Aug 04, 2024



In-context learning (ICL) is a few-shot learning paradigm that involves learning mappings through input-output pairs and appropriately applying them to new instances. Despite the remarkable ICL capabilities demonstrated by Large Language Models (LLMs), existing works are highly dependent on large-scale labeled support sets, not always feasible in practical scenarios. To refine this approach, we focus primarily on an innovative selective annotation mechanism, which precedes the standard demonstration retrieval. We introduce the Language Model-based Determinant Point Process (LM-DPP) that simultaneously considers the uncertainty and diversity of unlabeled instances for optimal selection. Consequently, this yields a subset for annotation that strikes a trade-off between the two factors. We apply LM-DPP to various language models, including GPT-J, LlaMA, and GPT-3. Experimental results on 9 NLU and 2 Generation datasets demonstrate that LM-DPP can effectively select canonical examples. Further analysis reveals that LLMs benefit most significantly from subsets that are both low uncertainty and high diversity.
Dependency Transformer Grammars: Integrating Dependency Structures into Transformer Language Models
Jul 24, 2024Syntactic Transformer language models aim to achieve better generalization through simultaneously modeling syntax trees and sentences. While prior work has been focusing on adding constituency-based structures to Transformers, we introduce Dependency Transformer Grammars (DTGs), a new class of Transformer language model with explicit dependency-based inductive bias. DTGs simulate dependency transition systems with constrained attention patterns by modifying attention masks, incorporate the stack information through relative positional encoding, and augment dependency arc representation with a combination of token embeddings and operation embeddings. When trained on a dataset of sentences annotated with dependency trees, DTGs achieve better generalization while maintaining comparable perplexity with Transformer language model baselines. DTGs also outperform recent constituency-based models, showing that dependency can better guide Transformer language models. Our code is released at https://github.com/zhaoyd1/Dep_Transformer_Grammars.
Sparser is Faster and Less is More: Efficient Sparse Attention for Long-Range Transformers
Jun 24, 2024



Accommodating long sequences efficiently in autoregressive Transformers, especially within an extended context window, poses significant challenges due to the quadratic computational complexity and substantial KV memory requirements inherent in self-attention mechanisms. In this work, we introduce SPARSEK Attention, a novel sparse attention mechanism designed to overcome these computational and memory obstacles while maintaining performance. Our approach integrates a scoring network and a differentiable top-k mask operator, SPARSEK, to select a constant number of KV pairs for each query, thereby enabling gradient-based optimization. As a result, SPARSEK Attention offers linear time complexity and constant memory footprint during generation. Experimental results reveal that SPARSEK Attention outperforms previous sparse attention methods and provides significant speed improvements during both training and inference, particularly in language modeling and downstream tasks. Furthermore, our method can be seamlessly integrated into pre-trained Large Language Models (LLMs) with minimal fine-tuning, offering a practical solution for effectively managing long-range dependencies in diverse applications.
AMR Parsing with Causal Hierarchical Attention and Pointers
Oct 18, 2023



Translation-based AMR parsers have recently gained popularity due to their simplicity and effectiveness. They predict linearized graphs as free texts, avoiding explicit structure modeling. However, this simplicity neglects structural locality in AMR graphs and introduces unnecessary tokens to represent coreferences. In this paper, we introduce new target forms of AMR parsing and a novel model, CHAP, which is equipped with causal hierarchical attention and the pointer mechanism, enabling the integration of structures into the Transformer decoder. We empirically explore various alternative modeling options. Experiments show that our model outperforms baseline models on four out of five benchmarks in the setting of no additional data.
SeqGPT: An Out-of-the-box Large Language Model for Open Domain Sequence Understanding
Aug 21, 2023



Large language models (LLMs) have shown impressive ability for open-domain NLP tasks. However, LLMs are sometimes too footloose for natural language understanding (NLU) tasks which always have restricted output and input format. Their performances on NLU tasks are highly related to prompts or demonstrations and are shown to be poor at performing several representative NLU tasks, such as event extraction and entity typing. To this end, we present SeqGPT, a bilingual (i.e., English and Chinese) open-source autoregressive model specially enhanced for open-domain natural language understanding. We express all NLU tasks with two atomic tasks, which define fixed instructions to restrict the input and output format but still ``open'' for arbitrarily varied label sets. The model is first instruction-tuned with extremely fine-grained labeled data synthesized by ChatGPT and then further fine-tuned by 233 different atomic tasks from 152 datasets across various domains. The experimental results show that SeqGPT has decent classification and extraction ability, and is capable of performing language understanding tasks on unseen domains. We also conduct empirical studies on the scaling of data and model size as well as on the transfer across tasks. Our model is accessible at https://github.com/Alibaba-NLP/SeqGPT.
Improving Grammar-based Sequence-to-Sequence Modeling with Decomposition and Constraints
Jun 05, 2023



Neural QCFG is a grammar-based sequence-tosequence (seq2seq) model with strong inductive biases on hierarchical structures. It excels in interpretability and generalization but suffers from expensive inference. In this paper, we study two low-rank variants of Neural QCFG for faster inference with different trade-offs between efficiency and expressiveness. Furthermore, utilizing the symbolic interface provided by the grammar, we introduce two soft constraints over tree hierarchy and source coverage. We experiment with various datasets and find that our models outperform vanilla Neural QCFG in most settings.
Unsupervised Vision-Language Parsing: Seamlessly Bridging Visual Scene Graphs with Language Structures via Dependency Relationships
Mar 27, 2022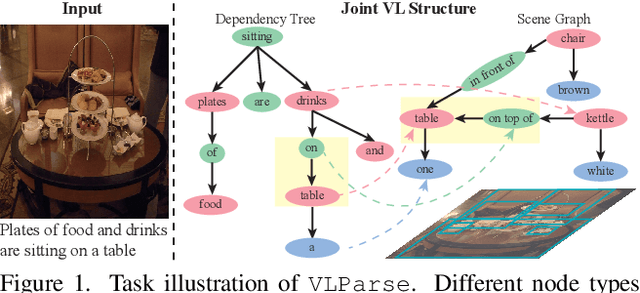
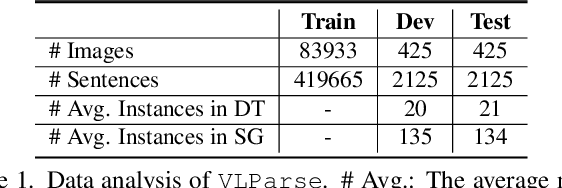
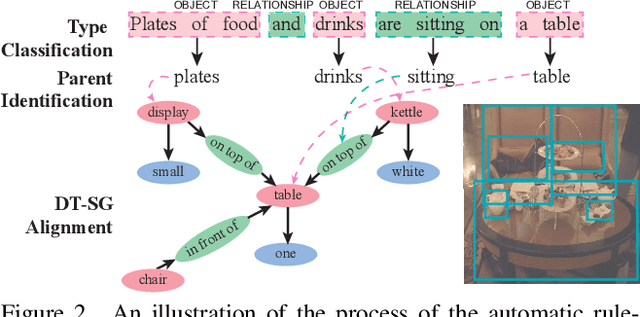
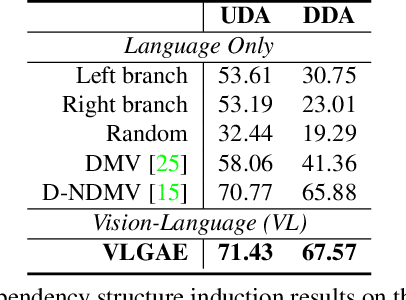
Understanding realistic visual scene images together with language descriptions is a fundamental task towards generic visual understanding. Previous works have shown compelling comprehensive results by building hierarchical structures for visual scenes (e.g., scene graphs) and natural languages (e.g., dependency trees), individually. However, how to construct a joint vision-language (VL) structure has barely been investigated. More challenging but worthwhile, we introduce a new task that targets on inducing such a joint VL structure in an unsupervised manner. Our goal is to bridge the visual scene graphs and linguistic dependency trees seamlessly. Due to the lack of VL structural data, we start by building a new dataset VLParse. Rather than using labor-intensive labeling from scratch, we propose an automatic alignment procedure to produce coarse structures followed by human refinement to produce high-quality ones. Moreover, we benchmark our dataset by proposing a contrastive learning (CL)-based framework VLGAE, short for Vision-Language Graph Autoencoder. Our model obtains superior performance on two derived tasks, i.e., language grammar induction and VL phrase grounding. Ablations show the effectiveness of both visual cues and dependency relationships on fine-grained VL structure construction.
Nested Named Entity Recognition as Latent Lexicalized Constituency Parsing
Mar 09, 2022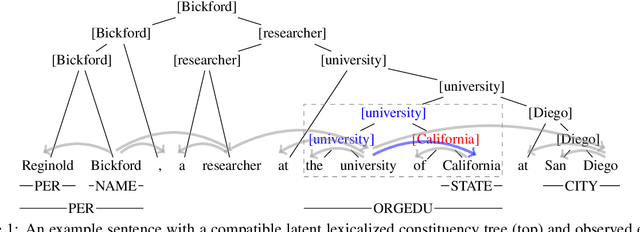
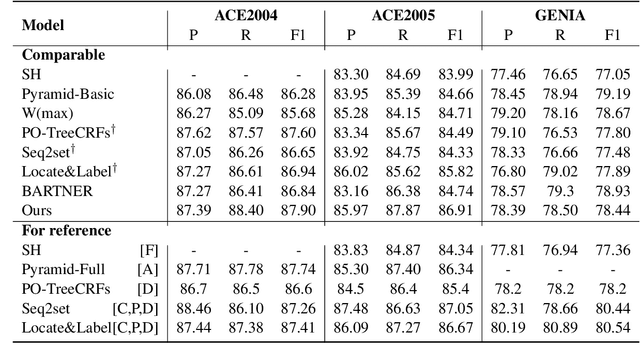
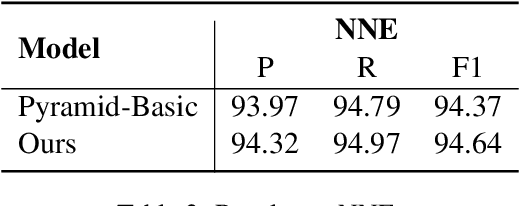

Nested named entity recognition (NER) has been receiving increasing attention. Recently, (Fu et al, 2021) adapt a span-based constituency parser to tackle nested NER. They treat nested entities as partially-observed constituency trees and propose the masked inside algorithm for partial marginalization. However, their method cannot leverage entity heads, which have been shown useful in entity mention detection and entity typing. In this work, we resort to more expressive structures, lexicalized constituency trees in which constituents are annotated by headwords, to model nested entities. We leverage the Eisner-Satta algorithm to perform partial marginalization and inference efficiently. In addition, we propose to use (1) a two-stage strategy (2) a head regularization loss and (3) a head-aware labeling loss in order to enhance the performance. We make a thorough ablation study to investigate the functionality of each component. Experimentally, our method achieves the state-of-the-art performance on ACE2004, ACE2005 and NNE, and competitive performance on GENIA, and meanwhile has a fast inference speed.