 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Nested Named Entity Recognition from Flat Annotations
Feb 28, 2026Nested named entity recognition identifies entities contained within other entities, but requires expensive multi-level annotation. While flat NER corpora exist abundantly, nested resources remain scarce. We investigate whether models can learn nested structure from flat annotations alone, evaluating four approaches: string inclusions (substring matching), entity corruption (pseudo-nested data), flat neutralization (reducing false negative signal), and a hybrid fine-tuned + LLM pipeline. On NEREL, a Russian benchmark with 29 entity types where 21% of entities are nested, our best combined method achieves 26.37% inner F1, closing 40% of the gap to full nested supervision. Code is available at https://github.com/fulstock/Learning-from-Flat-Annotations.
Methods for Recognizing Nested Terms
Apr 22, 2025In this paper, we describe our participation in the RuTermEval competition devoted to extracting nested terms. We apply the Binder model, which was previously successfully applied to the recognition of nested named entities, to extract nested terms. We obtained the best results of term recognition in all three tracks of the RuTermEval competition. In addition, we study the new task of recognition of nested terms from flat training data annotated with terms without nestedness. We can conclude that several approaches we proposed in this work are viable enough to retrieve nested terms effectively without nested labeling of them.
RuNNE-2022 Shared Task: Recognizing Nested Named Entities
May 23, 2022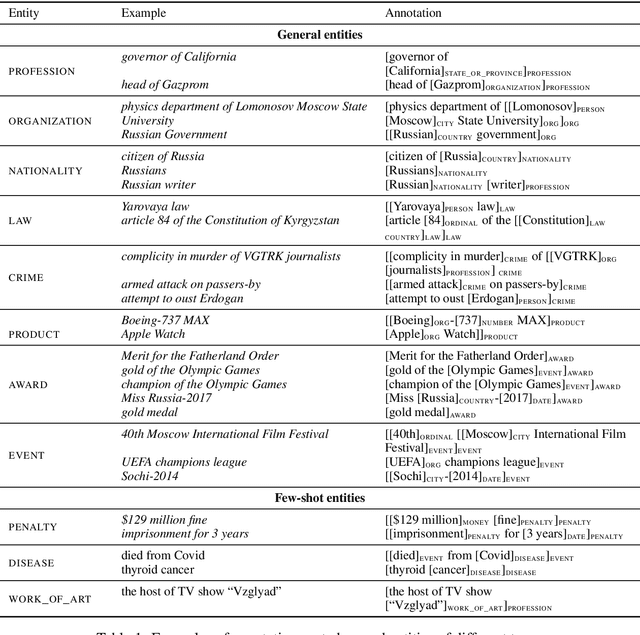
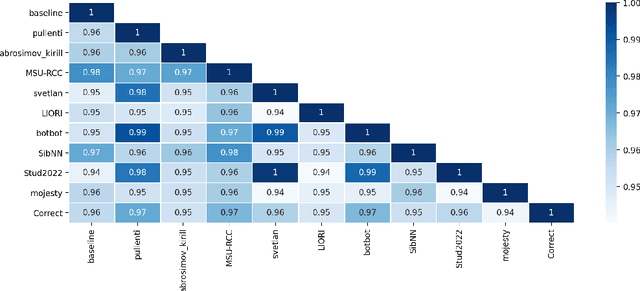
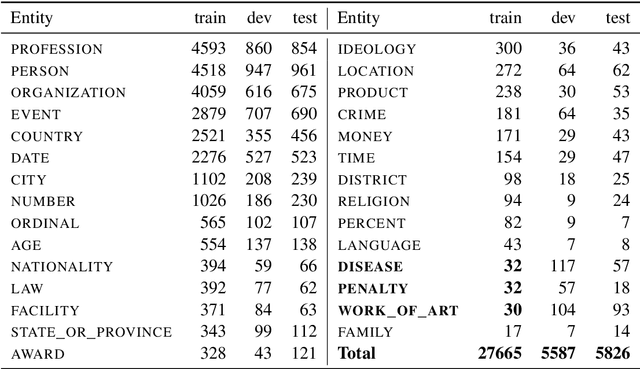
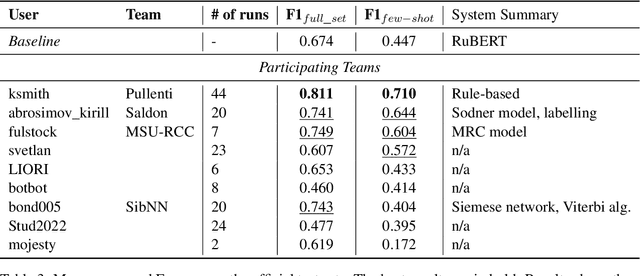
The RuNNE Shared Task approaches the problem of nested named entity recognition. The annotation schema is designed in such a way, that an entity may partially overlap or even be nested into another entity. This way, the named entity "The Yermolova Theatre" of type "organization" houses another entity "Yermolova" of type "person". We adopt the Russian NEREL dataset for the RuNNE Shared Task. NEREL comprises news texts written in the Russian language and collected from the Wikinews portal. The annotation schema includes 29 entity types. The nestedness of named entities in NEREL reaches up to six levels. The RuNNE Shared Task explores two setups. (i) In the general setup all entities occur more or less with the same frequency. (ii) In the few-shot setup the majority of entity types occur often in the training set. However, some of the entity types are have lower frequency, being thus challenging to recognize. In the test set the frequency of all entity types is even. This paper reports on the results of the RuNNE Shared Task. Overall the shared task has received 156 submissions from nine teams. Half of the submissions outperform a straightforward BERT-based baseline in both setups. This paper overviews the shared task setup and discusses the submitted systems, discovering meaning insights for the problem of nested NER. The links to the evaluation platform and the data from the shared task are available in our github repository: https://github.com/dialogue-evaluation/RuNNE.