 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemusic generation
Music generation is the task of generating music or music-like sounds from a model or algorithm.
Papers and Code
PhyAVBench: A Challenging Audio Physics-Sensitivity Benchmark for Physically Grounded Text-to-Audio-Video Generation
Dec 30, 2025Text-to-audio-video (T2AV) generation underpins a wide range of applications demanding realistic audio-visual content, including virtual reality, world modeling, gaming, and filmmaking. However, existing T2AV models remain incapable of generating physically plausible sounds, primarily due to their limited understanding of physical principles. To situate current research progress, we present PhyAVBench, a challenging audio physics-sensitivity benchmark designed to systematically evaluate the audio physics grounding capabilities of existing T2AV models. PhyAVBench comprises 1,000 groups of paired text prompts with controlled physical variables that implicitly induce sound variations, enabling a fine-grained assessment of models' sensitivity to changes in underlying acoustic conditions. We term this evaluation paradigm the Audio-Physics Sensitivity Test (APST). Unlike prior benchmarks that primarily focus on audio-video synchronization, PhyAVBench explicitly evaluates models' understanding of the physical mechanisms underlying sound generation, covering 6 major audio physics dimensions, 4 daily scenarios (music, sound effects, speech, and their mix), and 50 fine-grained test points, ranging from fundamental aspects such as sound diffraction to more complex phenomena, e.g., Helmholtz resonance. Each test point consists of multiple groups of paired prompts, where each prompt is grounded by at least 20 newly recorded or collected real-world videos, thereby minimizing the risk of data leakage during model pre-training. Both prompts and videos are iteratively refined through rigorous human-involved error correction and quality control to ensure high quality. We argue that only models with a genuine grasp of audio-related physical principles can generate physically consistent audio-visual content. We hope PhyAVBench will stimulate future progress in this critical yet largely unexplored domain.
Discriminating real and synthetic super-resolved audio samples using embedding-based classifiers
Jan 06, 2026Generative adversarial networks (GANs) and diffusion models have recently achieved state-of-the-art performance in audio super-resolution (ADSR), producing perceptually convincing wideband audio from narrowband inputs. However, existing evaluations primarily rely on signal-level or perceptual metrics, leaving open the question of how closely the distributions of synthetic super-resolved and real wideband audio match. Here we address this problem by analyzing the separability of real and super-resolved audio in various embedding spaces. We consider both middle-band ($4\to 16$~kHz) and full-band ($16\to 48$~kHz) upsampling tasks for speech and music, training linear classifiers to distinguish real from synthetic samples based on multiple types of audio embeddings. Comparisons with objective metrics and subjective listening tests reveal that embedding-based classifiers achieve near-perfect separation, even when the generated audio attains high perceptual quality and state-of-the-art metric scores. This behavior is consistent across datasets and models, including recent diffusion-based approaches, highlighting a persistent gap between perceptual quality and true distributional fidelity in ADSR models.
Emovectors: assessing emotional content in jazz improvisations for creativity evaluation
Dec 09, 2025Music improvisation is fascinating to study, being essentially a live demonstration of a creative process. In jazz, musicians often improvise across predefined chord progressions (leadsheets). How do we assess the creativity of jazz improvisations? And can we capture this in automated metrics for creativity for current LLM-based generative systems? Demonstration of emotional involvement is closely linked with creativity in improvisation. Analysing musical audio, can we detect emotional involvement? This study hypothesises that if an improvisation contains more evidence of emotion-laden content, it is more likely to be recognised as creative. An embeddings-based method is proposed for capturing the emotional content in musical improvisations, using a psychologically-grounded classification of musical characteristics associated with emotions. Resulting 'emovectors' are analysed to test the above hypothesis, comparing across multiple improvisations. Capturing emotional content in this quantifiable way can contribute towards new metrics for creativity evaluation that can be applied at scale.
UniAct: Unified Motion Generation and Action Streaming for Humanoid Robots
Dec 30, 2025A long-standing objective in humanoid robotics is the realization of versatile agents capable of following diverse multimodal instructions with human-level flexibility. Despite advances in humanoid control, bridging high-level multimodal perception with whole-body execution remains a significant bottleneck. Existing methods often struggle to translate heterogeneous instructions -- such as language, music, and trajectories -- into stable, real-time actions. Here we show that UniAct, a two-stage framework integrating a fine-tuned MLLM with a causal streaming pipeline, enables humanoid robots to execute multimodal instructions with sub-500 ms latency. By unifying inputs through a shared discrete codebook via FSQ, UniAct ensures cross-modal alignment while constraining motions to a physically grounded manifold. This approach yields a 19% improvement in the success rate of zero-shot tracking of imperfect reference motions. We validate UniAct on UniMoCap, our 20-hour humanoid motion benchmark, demonstrating robust generalization across diverse real-world scenarios. Our results mark a critical step toward responsive, general-purpose humanoid assistants capable of seamless interaction through unified perception and control.
Aliasing-Free Neural Audio Synthesis
Dec 23, 2025



Neural vocoders and codecs reconstruct waveforms from acoustic representations, which directly impact the audio quality. Among existing methods, upsampling-based time-domain models are superior in both inference speed and synthesis quality, achieving state-of-the-art performance. Still, despite their success in producing perceptually natural sound, their synthesis fidelity remains limited due to the aliasing artifacts brought by the inadequately designed model architectures. In particular, the unconstrained nonlinear activation generates an infinite number of harmonics that exceed the Nyquist frequency, resulting in ``folded-back'' aliasing artifacts. The widely used upsampling layer, ConvTranspose, copies the mirrored low-frequency parts to fill the empty high-frequency region, resulting in ``mirrored'' aliasing artifacts. Meanwhile, the combination of its inherent periodicity and the mirrored DC bias also brings ``tonal artifact,'' resulting in constant-frequency ringing. This paper aims to solve these issues from a signal processing perspective. Specifically, we apply oversampling and anti-derivative anti-aliasing to the activation function to obtain its anti-aliased form, and replace the problematic ConvTranspose layer with resampling to avoid the ``tonal artifact'' and eliminate aliased components. Based on our proposed anti-aliased modules, we introduce Pupu-Vocoder and Pupu-Codec, and release high-quality pre-trained checkpoints to facilitate audio generation research. We build a test signal benchmark to illustrate the effectiveness of the anti-aliased modules, and conduct experiments on speech, singing voice, music, and audio to validate our proposed models. Experimental results confirm that our lightweight Pupu-Vocoder and Pupu-Codec models can easily outperform existing systems on singing voice, music, and audio, while achieving comparable performance on speech.
Bridging the Copyright Gap: Do Large Vision-Language Models Recognize and Respect Copyrighted Content?
Dec 26, 2025Large vision-language models (LVLMs) have achieved remarkable advancements in multimodal reasoning tasks. However, their widespread accessibility raises critical concerns about potential copyright infringement. Will LVLMs accurately recognize and comply with copyright regulations when encountering copyrighted content (i.e., user input, retrieved documents) in the context? Failure to comply with copyright regulations may lead to serious legal and ethical consequences, particularly when LVLMs generate responses based on copyrighted materials (e.g., retrieved book experts, news reports). In this paper, we present a comprehensive evaluation of various LVLMs, examining how they handle copyrighted content -- such as book excerpts, news articles, music lyrics, and code documentation when they are presented as visual inputs. To systematically measure copyright compliance, we introduce a large-scale benchmark dataset comprising 50,000 multimodal query-content pairs designed to evaluate how effectively LVLMs handle queries that could lead to copyright infringement. Given that real-world copyrighted content may or may not include a copyright notice, the dataset includes query-content pairs in two distinct scenarios: with and without a copyright notice. For the former, we extensively cover four types of copyright notices to account for different cases. Our evaluation reveals that even state-of-the-art closed-source LVLMs exhibit significant deficiencies in recognizing and respecting the copyrighted content, even when presented with the copyright notice. To solve this limitation, we introduce a novel tool-augmented defense framework for copyright compliance, which reduces infringement risks in all scenarios. Our findings underscore the importance of developing copyright-aware LVLMs to ensure the responsible and lawful use of copyrighted content.
Efficient Optimization of Hierarchical Identifiers for Generative Recommendation
Dec 20, 2025SEATER is a generative retrieval model that improves recommendation inference efficiency and retrieval quality by utilizing balanced tree-structured item identifiers and contrastive training objectives. We reproduce and validate SEATER's reported improvements in retrieval quality over strong baselines across all datasets from the original work, and extend the evaluation to Yambda, a large-scale music recommendation dataset. Our experiments verify SEATER's strong performance, but show that its tree construction step during training becomes a major bottleneck as the number of items grows. To address this, we implement and evaluate two alternative construction algorithms: a greedy method optimized for minimal build time, and a hybrid method that combines greedy clustering at high levels with more precise grouping at lower levels. The greedy method reduces tree construction time to less than 2% of the original with only a minor drop in quality on the dataset with the largest item collection. The hybrid method achieves retrieval quality on par with the original, and even improves on the largest dataset, while cutting construction time to just 5-8%. All data and code are publicly available for full reproducibility at https://github.com/joshrosie/re-seater.
VABench: A Comprehensive Benchmark for Audio-Video Generation
Dec 10, 2025Recent advances in video generation have been remarkable, enabling models to produce visually compelling videos with synchronized audio. While existing video generation benchmarks provide comprehensive metrics for visual quality, they lack convincing evaluations for audio-video generation, especially for models aiming to generate synchronized audio-video outputs. To address this gap, we introduce VABench, a comprehensive and multi-dimensional benchmark framework designed to systematically evaluate the capabilities of synchronous audio-video generation. VABench encompasses three primary task types: text-to-audio-video (T2AV), image-to-audio-video (I2AV), and stereo audio-video generation. It further establishes two major evaluation modules covering 15 dimensions. These dimensions specifically assess pairwise similarities (text-video, text-audio, video-audio), audio-video synchronization, lip-speech consistency, and carefully curated audio and video question-answering (QA) pairs, among others. Furthermore, VABench covers seven major content categories: animals, human sounds, music, environmental sounds, synchronous physical sounds, complex scenes, and virtual worlds. We provide a systematic analysis and visualization of the evaluation results, aiming to establish a new standard for assessing video generation models with synchronous audio capabilities and to promote the comprehensive advancement of the field.
Memo2496: Expert-Annotated Dataset and Dual-View Adaptive Framework for Music Emotion Recognition
Dec 17, 2025
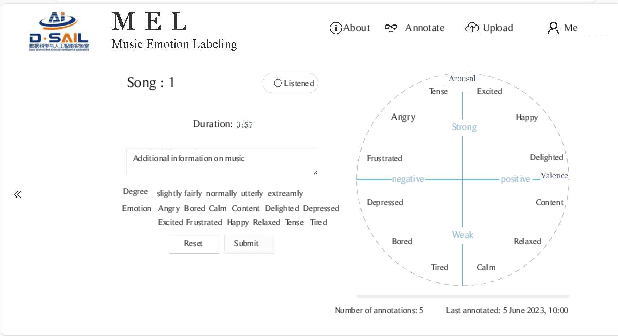
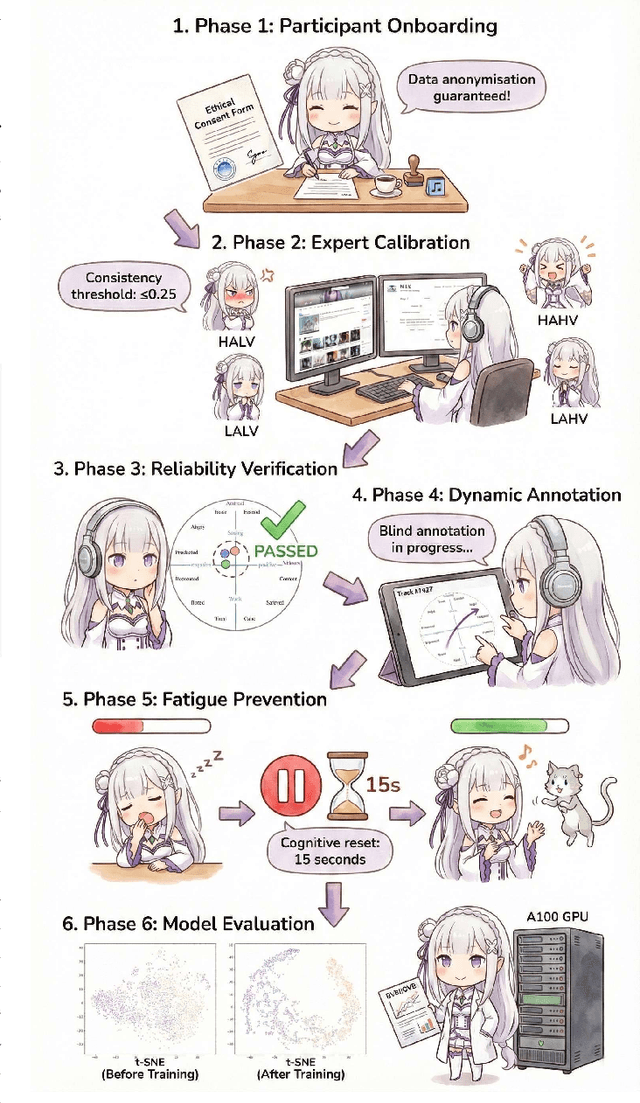
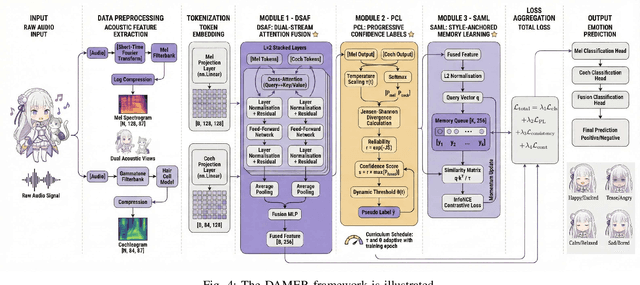
Music Emotion Recogniser (MER) research faces challenges due to limited high-quality annotated datasets and difficulties in addressing cross-track feature drift. This work presents two primary contributions to address these issues. Memo2496, a large-scale dataset, offers 2496 instrumental music tracks with continuous valence arousal labels, annotated by 30 certified music specialists. Annotation quality is ensured through calibration with extreme emotion exemplars and a consistency threshold of 0.25, measured by Euclidean distance in the valence arousal space. Furthermore, the Dual-view Adaptive Music Emotion Recogniser (DAMER) is introduced. DAMER integrates three synergistic modules: Dual Stream Attention Fusion (DSAF) facilitates token-level bidirectional interaction between Mel spectrograms and cochleagrams via cross attention mechanisms; Progressive Confidence Labelling (PCL) generates reliable pseudo labels employing curriculum-based temperature scheduling and consistency quantification using Jensen Shannon divergence; and Style Anchored Memory Learning (SAML) maintains a contrastive memory queue to mitigate cross-track feature drift. Extensive experiments on the Memo2496, 1000songs, and PMEmo datasets demonstrate DAMER's state-of-the-art performance, improving arousal dimension accuracy by 3.43%, 2.25%, and 0.17%, respectively. Ablation studies and visualisation analyses validate each module's contribution. Both the dataset and source code are publicly available.
Learning Robot Manipulation from Audio World Models
Dec 09, 2025

World models have demonstrated impressive performance on robotic learning tasks. Many such tasks inherently demand multimodal reasoning; for example, filling a bottle with water will lead to visual information alone being ambiguous or incomplete, thereby requiring reasoning over the temporal evolution of audio, accounting for its underlying physical properties and pitch patterns. In this paper, we propose a generative latent flow matching model to anticipate future audio observations, enabling the system to reason about long-term consequences when integrated into a robot policy. We demonstrate the superior capabilities of our system through two manipulation tasks that require perceiving in-the-wild audio or music signals, compared to methods without future lookahead. We further emphasize that successful robot action learning for these tasks relies not merely on multi-modal input, but critically on the accurate prediction of future audio states that embody intrinsic rhythmic patterns.