 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio Inpainting in Time-Frequency Domain with Phase-Aware Prior
Jan 26, 2026The so-called audio inpainting problem in the time domain refers to estimating missing segments of samples within a signal. Over the years, several methods have been developed for such type of audio inpainting. In contrast to this case, a time-frequency variant of inpainting appeared in the literature, where the challenge is to reconstruct missing spectrogram columns with reliable information. We propose a method to address this time-frequency audio inpainting problem. Our approach is based on the recently introduced phase-aware signal prior that exploits an estimate of the instantaneous frequency. An optimization problem is formulated and solved using the generalized Chambolle-Pock algorithm. The proposed method is evaluated both objectively and subjectively against other time-frequency inpainting methods, specifically a deep-prior neural network and the autoregression-based approach known as Janssen-TF. Our proposed approach surpassed these methods in the objective evaluation as well as in the conducted listening test. Moreover, this outcome is achieved with a substantially reduced computational requirement compared to alternative methods.
Unsupervised Estimation of Nonlinear Audio Effects: Comparing Diffusion-Based and Adversarial approaches
Apr 07, 2025Accurately estimating nonlinear audio effects without access to paired input-output signals remains a challenging problem.This work studies unsupervised probabilistic approaches for solving this task. We introduce a method, novel for this application, based on diffusion generative models for blind system identification, enabling the estimation of unknown nonlinear effects using black- and gray-box models. This study compares this method with a previously proposed adversarial approach, analyzing the performance of both methods under different parameterizations of the effect operator and varying lengths of available effected recordings.Through experiments on guitar distortion effects, we show that the diffusion-based approach provides more stable results and is less sensitive to data availability, while the adversarial approach is superior at estimating more pronounced distortion effects. Our findings contribute to the robust unsupervised blind estimation of audio effects, demonstrating the potential of diffusion models for system identification in music technology.
Regularized autoregressive modeling and its application to audio signal declipping
Oct 23, 2024Autoregressive (AR) modeling is invaluable in signal processing, in particular in speech and audio fields. Attempts in the literature can be found that regularize or constrain either the time-domain signal values or the AR coefficients, which is done for various reasons, including the incorporation of prior information or numerical stabilization. Although these attempts are appealing, an encompassing and generic modeling framework is still missing. We propose such a framework and the related optimization problem and algorithm. We discuss the computational demands of the algorithm and explore the effects of various improvements on its convergence speed. In the experimental part, we demonstrate the usefulness of our approach on the audio declipping problem. We compare its performance against the state-of-the-art methods and demonstrate the competitiveness of the proposed method, especially for mildly clipped signals. The evaluation is extended by considering a heuristic algorithm of generalized linear prediction (GLP), a strong competitor which has only been presented as a patent and is new in the scientific community.
Dequantization of a signal from two parallel quantized observations
Sep 12, 2024We propose a technique of signal acquisition using a combination of two devices with different sampling rates and quantization accuracies. Subsequent processing involving sparsity regularization enables us to reconstruct the signal at such a sampling frequency and with such a bit depth that was not possible using the two devices independently. Objective and subjective tests show the superiority of the proposed method in comparison with alternatives.
Janssen 2.0: Audio Inpainting in the Time-frequency Domain
Sep 10, 2024The paper focuses on inpainting missing parts of an audio signal spectrogram. First, a recent successful approach based on an untrained neural network is revised and its several modifications are proposed, improving the signal-to-noise ratio of the restored audio. Second, the Janssen algorithm, the autoregression-based state-of-the-art for time-domain audio inpainting, is adapted for the time-frequency setting. This novel method, coined Janssen-TF, is compared to the neural network approach using both objective metrics and a subjective listening test, proving Janssen-TF to be superior in all the considered measures.
On the Use of Autoregressive Methods for Audio Inpainting
Mar 07, 2024The paper presents an evaluation of popular audio inpainting methods based on autoregressive modelling, namely, extrapolation-based and Janssen methods. A novel variant of the Janssen method suitable for gap inpainting is also proposed. The main differences between the particular popular approaches are pointed out, and a mid-scale computational experiment is presented. The results demonstrate the importance of the choice of the AR model estimator and the suitability of the new gap-wise Janssen method.
Improving DCE-MRI through unfolded low-rank + sparse optimisation
Dec 12, 2023A method for perfusion imaging with DCE-MRI is developed based on two popular paradigms: the low-rank + sparse model for optimisation-based reconstruction, and the deep unfolding. A learnable algorithm derived from a proximal algorithm is designed with emphasis on simplicity and interpretability. The resulting deep network is trained and evaluated using a simulated measurement of a rat with a brain tumor, showing large performance gain over the classical low-rank + sparse baseline. Moreover, quantitative perfusion analysis is performed based on the reconstructed sequence, proving that even training based on a simple pixel-wise error can lead to significant improvement of the quality of the perfusion maps.
Multiple Hankel matrix rank minimization for audio inpainting
Mar 31, 2023Sasaki et al. (2018) presented an efficient audio declipping algorithm, based on the properties of Hankel-structured matrices constructed from time-domain signal blocks. We adapt their approach to solve the audio inpainting problem, where samples are missing in the signal. We analyze the algorithm and provide modifications, some of them leading to an improved performance. Overall, it turns out that the new algorithms perform reasonably well for speech signals but they are not competitive in the case of music signals.
Analysis Social Sparsity Audio Declipper
May 20, 2022
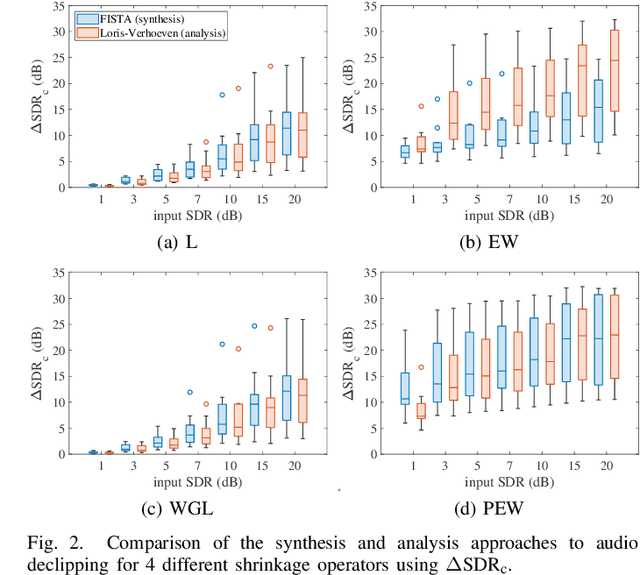
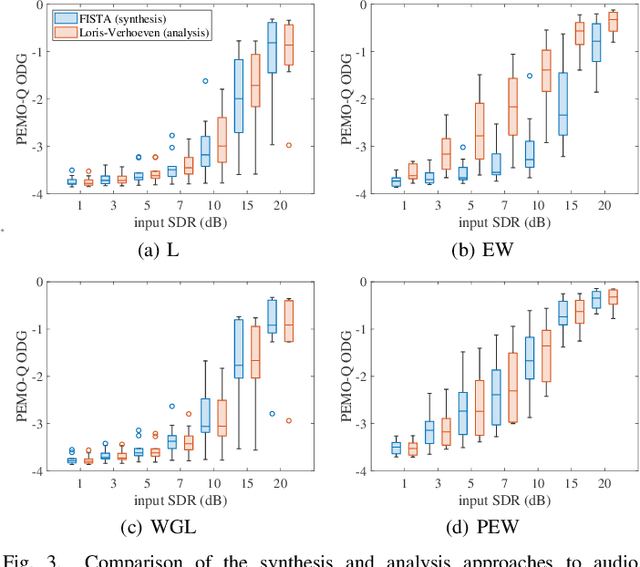
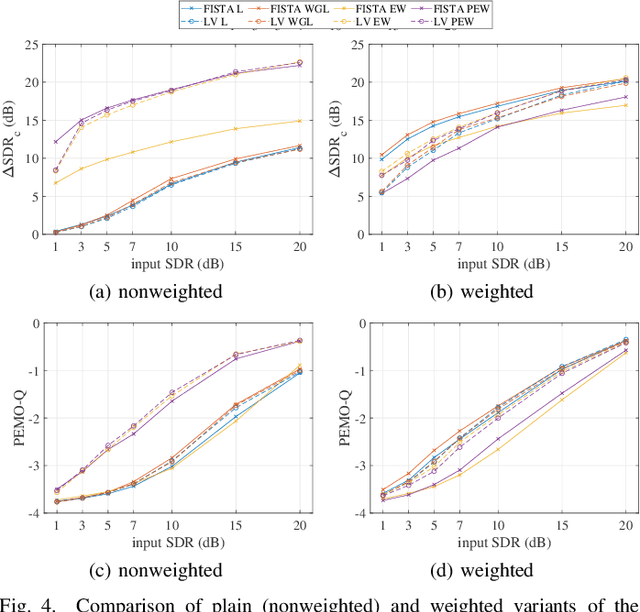
We develop the analysis (cosparse) variant of the popular audio declipping algorithm of Siedenburg et al. Furthermore, we extend it by the possibility of weighting the time-frequency coefficients. We examine the audio reconstruction performance of several combinations of weights and shrinkage operators. We show that weights improve the reconstruction quality in some cases; however, the overall scores achieved by the non-weighted are not surpassed. Yet, the analysis Empirical Wiener (EW) shrinkage was able to reach the quality of a computationally more expensive competitor, the Persistent Empirical Wiener (PEW). Moreover, the proposed analysis variant using PEW slightly outperforms the synthesis counterpart in terms of an auditory-motivated metric.
Audio declipping performance enhancement via crossfading
Apr 07, 2021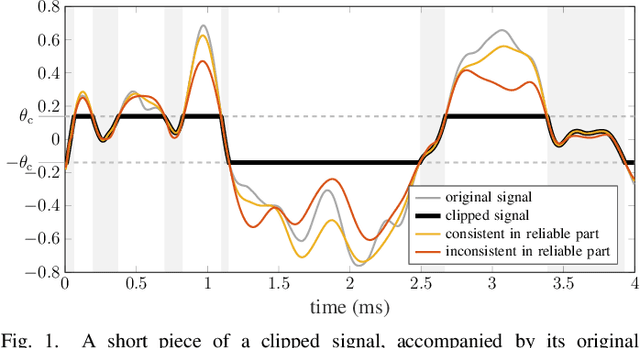
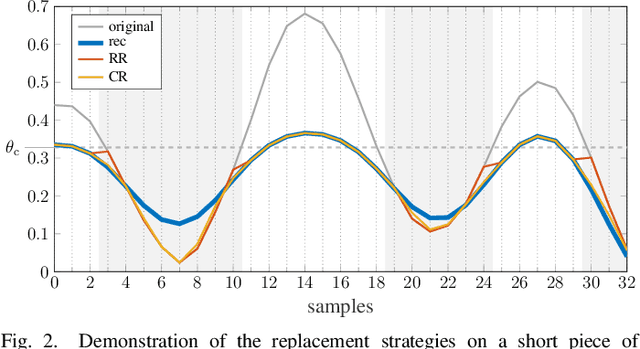
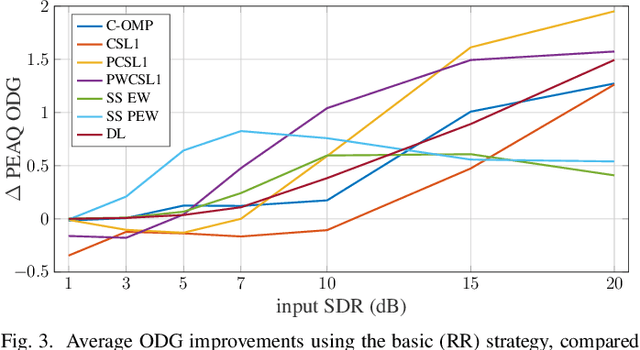
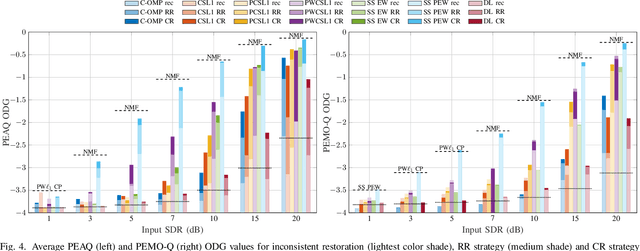
Some audio declipping methods produce waveforms that do not fully respect the physical process of clipping, which is why we refer to them as inconsistent. This letter reports what effect on perception it has if the solution by inconsistent methods is forced consistent by postprocessing. We first propose a simple sample replacement method, then we identify its main weaknesses and propose an improved variant. The experiments show that the vast majority of inconsistent declipping methods significantly benefit from the proposed approach in terms of objective perceptual metrics. In particular, we show that the SS PEW method based on social sparsity combined with the proposed method performs comparable to top methods from the consistent class, but at a computational cost of one order of magnitude lower.