 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Attribution in Large Language Models via Bidirectional Gradient Optimization
Jun 03, 2026Large Language Models (LLMs) are increasingly deployed across diverse applications, raising critical questions for governance, accountability, and data provenance. Understanding which training data most influenced a model's output remains a fundamental open problem. We address this challenge through training data attribution (TDA) for auto-regressive LLMs by expanding upon the inverse formulation: How would training data be affected if the model had seen the generated output during training? Our method perturbs the base model using bidirectional gradient optimization (gradient ascent and descent) on a generated text sample and measures the resulting change in loss across training samples. Our framework supports attribution at arbitrary data granularity, enabling both factual and stylistic attribution. We evaluate our method against baselines on pretrained models with known datasets, and show that it outperforms previous work on influence metrics, thereby enhancing model interpretability, an essential requirement for accountable AI systems.
Reasoning Structure of Large Language Models
Jun 02, 2026Large reasoning models (LRMs) are often evaluated using metrics such as final-answer accuracy or token count. However, identical scores on these metrics can hide fundamentally different reasoning structures. To address this limitation, we introduce a scalable LRM benchmark of logic puzzles and a pipeline that converts unstructured traces into verifiable reasoning graphs of claims and dependencies. This turns reasoning into a structured, measurable object whose topology can be quantitatively analyzed. Building on this, we define a reasoning efficiency metric that quantifies how concentrated the model's logical flow is. Our analysis on open-source reasoning models shows that structural measurements separate behaviors that token count and accuracy conflate, providing a practical tool for diagnosing failure modes and comparing how reasoning scales with puzzle difficulty.
WorldSpeech: A Multilingual Speech Corpus from Around the World
May 09, 2026Automatic speech recognition (ASR) performs well for high-resource languages with abundant paired audio-transcript data, but its accuracy degrades sharply for most languages due to limited publicly available aligned data. To this end, we introduce WorldSpeech, a 24 kHz multilingual speech corpus comprising 65k hours of aligned audio-transcript data across 76 languages, collected from diverse public sources including parliamentary proceedings, international broadcasts, and public-domain audiobooks. For 37 languages, WorldSpeech provides more than 200 hours of aligned speech, with 28 exceeding 500 hours and 24 surpassing 1k hours. Fine-tuning existing ASR models on WorldSpeech results in an average relative Word-Error-Rate reduction of 63.5% across 11 typologically diverse languages.
Inductive Transfer Learning for Graph-Based Recommenders
Oct 26, 2025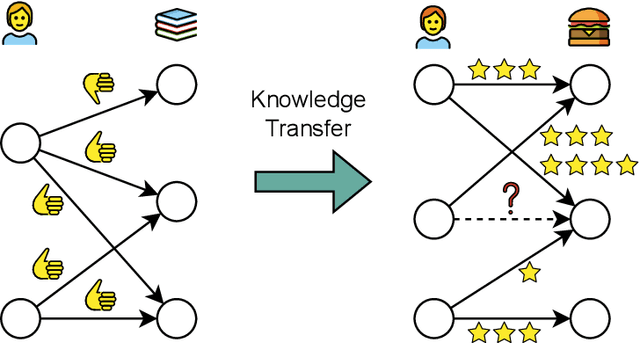
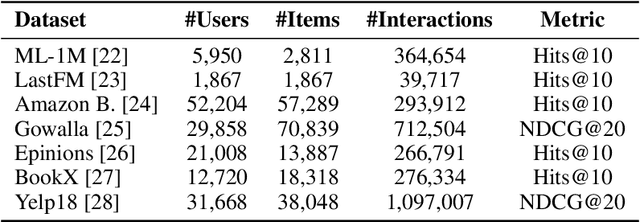
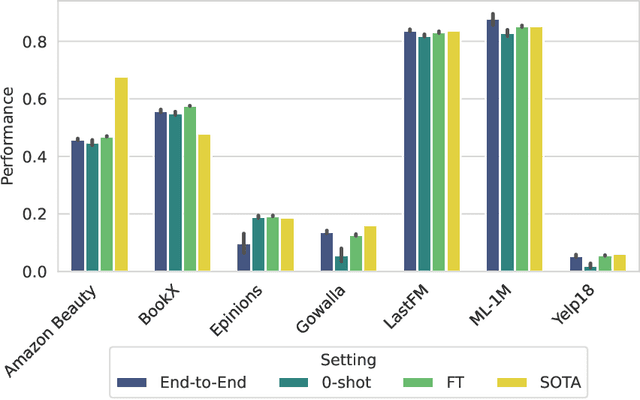
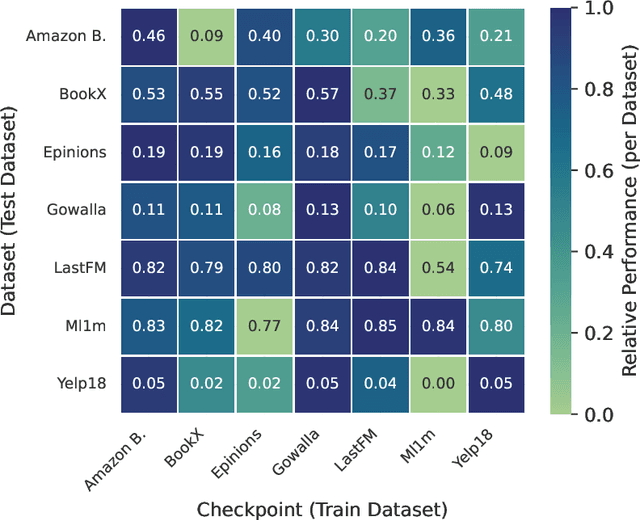
Graph-based recommender systems are commonly trained in transductive settings, which limits their applicability to new users, items, or datasets. We propose NBF-Rec, a graph-based recommendation model that supports inductive transfer learning across datasets with disjoint user and item sets. Unlike conventional embedding-based methods that require retraining for each domain, NBF-Rec computes node embeddings dynamically at inference time. We evaluate the method on seven real-world datasets spanning movies, music, e-commerce, and location check-ins. NBF-Rec achieves competitive performance in zero-shot settings, where no target domain data is used for training, and demonstrates further improvements through lightweight fine-tuning. These results show that inductive transfer is feasible in graph-based recommendation and that interaction-level message passing supports generalization across datasets without requiring aligned users or items.
SAO-Instruct: Free-form Audio Editing using Natural Language Instructions
Oct 26, 2025Generative models have made significant progress in synthesizing high-fidelity audio from short textual descriptions. However, editing existing audio using natural language has remained largely underexplored. Current approaches either require the complete description of the edited audio or are constrained to predefined edit instructions that lack flexibility. In this work, we introduce SAO-Instruct, a model based on Stable Audio Open capable of editing audio clips using any free-form natural language instruction. To train our model, we create a dataset of audio editing triplets (input audio, edit instruction, output audio) using Prompt-to-Prompt, DDPM inversion, and a manual editing pipeline. Although partially trained on synthetic data, our model generalizes well to real in-the-wild audio clips and unseen edit instructions. We demonstrate that SAO-Instruct achieves competitive performance on objective metrics and outperforms other audio editing approaches in a subjective listening study. To encourage future research, we release our code and model weights.
Bias beyond Borders: Global Inequalities in AI-Generated Music
Oct 02, 2025While recent years have seen remarkable progress in music generation models, research on their biases across countries, languages, cultures, and musical genres remains underexplored. This gap is compounded by the lack of datasets and benchmarks that capture the global diversity of music. To address these challenges, we introduce GlobalDISCO, a large-scale dataset consisting of 73k music tracks generated by state-of-the-art commercial generative music models, along with paired links to 93k reference tracks in LAION-DISCO-12M. The dataset spans 147 languages and includes musical style prompts extracted from MusicBrainz and Wikipedia. The dataset is globally balanced, representing musical styles from artists across 79 countries and five continents. Our evaluation reveals large disparities in music quality and alignment with reference music between high-resource and low-resource regions. Furthermore, we find marked differences in model performance between mainstream and geographically niche genres, including cases where models generate music for regional genres that more closely align with the distribution of mainstream styles.
High-Fidelity Speech Enhancement via Discrete Audio Tokens
Oct 02, 2025


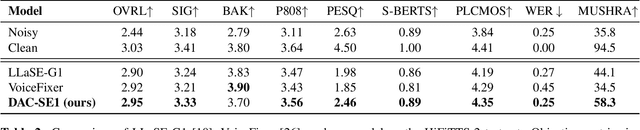
Recent autoregressive transformer-based speech enhancement (SE) methods have shown promising results by leveraging advanced semantic understanding and contextual modeling of speech. However, these approaches often rely on complex multi-stage pipelines and low sampling rate codecs, limiting them to narrow and task-specific speech enhancement. In this work, we introduce DAC-SE1, a simplified language model-based SE framework leveraging discrete high-resolution audio representations; DAC-SE1 preserves fine-grained acoustic details while maintaining semantic coherence. Our experiments show that DAC-SE1 surpasses state-of-the-art autoregressive SE methods on both objective perceptual metrics and in a MUSHRA human evaluation. We release our codebase and model checkpoints to support further research in scalable, unified, and high-quality speech enhancement.
Multi-bit Audio Watermarking
Oct 02, 2025



We present Timbru, a post-hoc audio watermarking model that achieves state-of-the-art robustness and imperceptibility trade-offs without training an embedder-detector model. Given any 44.1 kHz stereo music snippet, our method performs per-audio gradient optimization to add imperceptible perturbations in the latent space of a pretrained audio VAE, guided by a combined message and perceptual loss. The watermark can then be extracted using a pretrained CLAP model. We evaluate 16-bit watermarking on MUSDB18-HQ against AudioSeal, WavMark, and SilentCipher across common filtering, noise, compression, resampling, cropping, and regeneration attacks. Our approach attains the best average bit error rates, while preserving perceptual quality, demonstrating an efficient, dataset-free path to imperceptible audio watermarking.
Virtual Fashion Photo-Shoots: Building a Large-Scale Garment-Lookbook Dataset
Oct 01, 2025Fashion image generation has so far focused on narrow tasks such as virtual try-on, where garments appear in clean studio environments. In contrast, editorial fashion presents garments through dynamic poses, diverse locations, and carefully crafted visual narratives. We introduce the task of virtual fashion photo-shoot, which seeks to capture this richness by transforming standardized garment images into contextually grounded editorial imagery. To enable this new direction, we construct the first large-scale dataset of garment-lookbook pairs, bridging the gap between e-commerce and fashion media. Because such pairs are not readily available, we design an automated retrieval pipeline that aligns garments across domains, combining visual-language reasoning with object-level localization. We construct a dataset with three garment-lookbook pair accuracy levels: high quality (10,000 pairs), medium quality (50,000 pairs), and low quality (300,000 pairs). This dataset offers a foundation for models that move beyond catalog-style generation and toward fashion imagery that reflects creativity, atmosphere, and storytelling.
EuroSpeech: A Multilingual Speech Corpus
Oct 01, 2025Recent progress in speech processing has highlighted that high-quality performance across languages requires substantial training data for each individual language. While existing multilingual datasets cover many languages, they often contain insufficient data for most languages. Thus, trained models perform poorly on the majority of the supported languages. Our work addresses this challenge by introducing a scalable pipeline for constructing speech datasets from parliamentary recordings. The proposed pipeline includes robust components for media retrieval and a two-stage alignment algorithm designed to handle non-verbatim transcripts and long-form audio. Applying this pipeline to recordings from 22 European parliaments, we extract over 61k hours of aligned speech segments, achieving substantial per-language coverage with 19 languages exceeding 1k hours and 22 languages exceeding 500 hours of high-quality speech data. We obtain an average 41.8\% reduction in word error rates over baselines when finetuning an existing ASR model on our dataset, demonstrating the usefulness of our approach.