 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Art Of Scaling Reinforcement Learning Compute For Llms
Papers and Code
WebGen-R1: Incentivizing Large Language Models to Generate Functional and Aesthetic Websites with Reinforcement Learning
Apr 22, 2026While Large Language Models (LLMs) excel at function-level code generation, project-level tasks such as generating functional and visually aesthetic multi-page websites remain highly challenging. Existing works are often limited to single-page static websites, while agentic frameworks typically rely on multi-turn execution with proprietary models, leading to substantial token costs, high latency, and brittle integration. Training a small LLM end-to-end with reinforcement learning (RL) is a promising alternative, yet it faces a critical bottleneck in designing reliable and computationally feasible rewards for website generation. Unlike single-file coding tasks that can be verified by unit tests, website generation requires evaluating inherently subjective aesthetics, cross-page interactions, and functional correctness. To this end, we propose WebGen-R1, an end-to-end RL framework tailored for project-level website generation. We first introduce a scaffold-driven structured generation paradigm that constrains the large open-ended action space and preserves architectural integrity. We then design a novel cascaded multimodal reward that seamlessly couples structural guarantees with execution-grounded functional feedback and vision-based aesthetic supervision. Extensive experiments demonstrate that our WebGen-R1 substantially transforms a 7B base model from generating nearly nonfunctional websites into producing deployable, aesthetically aligned multi-page websites. Remarkably, our WebGen-R1 not only consistently outperforms heavily scaled open-source models (up to 72B), but also rivals the state-of-the-art DeepSeek-R1 (671B) in functional success, while substantially exceeding it in valid rendering and aesthetic alignment. These results position WebGen-R1 as a viable path for scaling small open models from function-level code generation to project-level web application generation.
InfoDensity: Rewarding Information-Dense Traces for Efficient Reasoning
Mar 18, 2026Large Language Models (LLMs) with extended reasoning capabilities often generate verbose and redundant reasoning traces, incurring unnecessary computational cost. While existing reinforcement learning approaches address this by optimizing final response length, they neglect the quality of intermediate reasoning steps, leaving models vulnerable to reward hacking. We argue that verbosity is not merely a length problem, but a symptom of poor intermediate reasoning quality. To investigate this, we conduct an empirical study tracking the conditional entropy of the answer distribution across reasoning steps. We find that high-quality reasoning traces exhibit two consistent properties: low uncertainty convergence and monotonic progress. These findings suggest that high-quality reasoning traces are informationally dense, that is, each step contributes meaningful entropy reduction relative to the total reasoning length. Motivated by this, we propose InfoDensity, a reward framework for RL training that combines an AUC-based reward and a monotonicity reward as a unified measure of reasoning quality, weighted by a length scaling term that favors achieving equivalent quality more concisely. Experiments on mathematical reasoning benchmarks demonstrate that InfoDensity matches or surpasses state-of-the-art baselines in accuracy while significantly reducing token usage, achieving a strong accuracy-efficiency trade-off.
The Art of Efficient Reasoning: Data, Reward, and Optimization
Feb 25, 2026Large Language Models (LLMs) consistently benefit from scaled Chain-of-Thought (CoT) reasoning, but also suffer from heavy computational overhead. To address this issue, efficient reasoning aims to incentivize short yet accurate thinking trajectories, typically through reward shaping with Reinforcement Learning (RL). In this paper, we systematically investigate the mechanics of efficient reasoning for LLMs. For comprehensive evaluation, we advocate for more fine-grained metrics, including length distribution conditioned on correctness and performance across a wide spectrum of token budgets ranging from 2k to 32k. First, we reveal that the training process follows a two-stage paradigm: length adaptation and reasoning refinement. After that, we conduct extensive experiments (about 0.2 million GPU hours) in a unified protocol, deconstructing training prompts and rollouts, reward shaping, and optimization strategies. In particular, a key finding is to train on relatively easier prompts, ensuring the density of positive reward signals and thus avoiding the length collapse. Meanwhile, the learned length bias can be generalized across domains. We distill all findings into valuable insights and practical guidelines, and further validate them across the Qwen3 series, ranging from 0.6B to 30B, demonstrating the robustness and generalization.
MemSifter: Offloading LLM Memory Retrieval via Outcome-Driven Proxy Reasoning
Mar 03, 2026As Large Language Models (LLMs) are increasingly used for long-duration tasks, maintaining effective long-term memory has become a critical challenge. Current methods often face a trade-off between cost and accuracy. Simple storage methods often fail to retrieve relevant information, while complex indexing methods (such as memory graphs) require heavy computation and can cause information loss. Furthermore, relying on the working LLM to process all memories is computationally expensive and slow. To address these limitations, we propose MemSifter, a novel framework that offloads the memory retrieval process to a small-scale proxy model. Instead of increasing the burden on the primary working LLM, MemSifter uses a smaller model to reason about the task before retrieving the necessary information. This approach requires no heavy computation during the indexing phase and adds minimal overhead during inference. To optimize the proxy model, we introduce a memory-specific Reinforcement Learning (RL) training paradigm. We design a task-outcome-oriented reward based on the working LLM's actual performance in completing the task. The reward measures the actual contribution of retrieved memories by mutiple interactions with the working LLM, and discriminates retrieved rankings by stepped decreasing contributions. Additionally, we employ training techniques such as Curriculum Learning and Model Merging to improve performance. We evaluated MemSifter on eight LLM memory benchmarks, including Deep Research tasks. The results demonstrate that our method meets or exceeds the performance of existing state-of-the-art approaches in both retrieval accuracy and final task completion. MemSifter offers an efficient and scalable solution for long-term LLM memory. We have open-sourced the model weights, code, and training data to support further research.
Where Relevance Emerges: A Layer-Wise Study of Internal Attention for Zero-Shot Re-Ranking
Feb 26, 2026Zero-shot document re-ranking with Large Language Models (LLMs) has evolved from Pointwise methods to Listwise and Setwise approaches that optimize computational efficiency. Despite their success, these methods predominantly rely on generative scoring or output logits, which face bottlenecks in inference latency and result consistency. In-Context Re-ranking (ICR) has recently been proposed as an $O(1)$ alternative method. ICR extracts internal attention signals directly, avoiding the overhead of text generation. However, existing ICR methods simply aggregate signals across all layers; layer-wise contributions and their consistency across architectures have been left unexplored. Furthermore, no unified study has compared internal attention with traditional generative and likelihood-based mechanisms across diverse ranking frameworks under consistent conditions. In this paper, we conduct an orthogonal evaluation of generation, likelihood, and internal attention mechanisms across multiple ranking frameworks. We further identify a universal "bell-curve" distribution of relevance signals across transformer layers, which motivates the proposed Selective-ICR strategy that reduces inference latency by 30%-50% without compromising effectiveness. Finally, evaluation on the reasoning-intensive BRIGHT benchmark shows that precisely capturing high-quality in-context attention signals fundamentally reduces the need for model scaling and reinforcement learning: a zero-shot 8B model matches the performance of 14B reinforcement-learned re-rankers, while even a 0.6B model outperforms state-of-the-art generation-based approaches. These findings redefine the efficiency-effectiveness frontier for LLM-based re-ranking and highlight the latent potential of internal signals for complex reasoning ranking tasks. Our code and results are publicly available at https://github.com/ielab/Selective-ICR.
Beyond Scalar Scores: Reinforcement Learning for Error-Aware Quality Estimation of Machine Translation
Feb 09, 2026Quality Estimation (QE) aims to assess the quality of machine translation (MT) outputs without relying on reference translations, making it essential for real-world, large-scale MT evaluation. Large Language Models (LLMs) have shown significant promise in advancing the field of quality estimation of machine translation. However, most of the QE approaches solely rely on scalar quality scores, offering no explicit information about the translation errors that should drive these judgments. Moreover, for low-resource languages where annotated QE data is limited, existing approaches struggle to achieve reliable performance. To address these challenges, we introduce the first segment-level QE dataset for English to Malayalam, a severely resource-scarce language pair in the QE domain, comprising human-annotated Direct Assessment (DA) scores and Translation Quality Remarks (TQR), which are short, contextual, free-form annotator comments that describe translation errors. We further introduce ALOPE-RL, a policy-based reinforcement learning framework that trains efficient adapters based on policy rewards derived from DA score and TQR. Integrating error-aware rewards with ALOPE-RL, enables LLMs to reason about translation quality beyond numeric scores. Despite being trained on a small-scale QE dataset, ALOPE-RL achieves state-of-the-art performance on English to Malayalam QE using compact LLMs (<=4B parameters}) fine-tuned with LoRA and 4-bit quantization, outperforming both larger LLM-based baselines and leading encoder-based QE models. Our results demonstrate that error-aware, policy-based learning can deliver strong QE performance under limited data and compute budgets. We release our dataset, code, and trained models to support future research.
Quantized Evolution Strategies: High-precision Fine-tuning of Quantized LLMs at Low-precision Cost
Feb 03, 2026Post-Training Quantization (PTQ) is essential for deploying Large Language Models (LLMs) on memory-constrained devices, yet it renders models static and difficult to fine-tune. Standard fine-tuning paradigms, including Reinforcement Learning (RL), fundamentally rely on backpropagation and high-precision weights to compute gradients. Thus they cannot be used on quantized models, where the parameter space is discrete and non-differentiable. While Evolution Strategies (ES) offer a backpropagation-free alternative, optimization of the quantized parameters can still fail due to vanishing or inaccurate gradient. This paper introduces Quantized Evolution Strategies (QES), an optimization paradigm that performs full-parameter fine-tuning directly in the quantized space. QES is based on two innovations: (1) it integrates accumulated error feedback to preserve high-precision gradient signals, and (2) it utilizes a stateless seed replay to reduce memory usage to low-precision inference levels. QES significantly outperforms the state-of-the-art zeroth-order fine-tuning method on arithmetic reasoning tasks, making direct fine-tuning for quantized models possible. It therefore opens up the possibility for scaling up LLMs entirely in the quantized space. The source code is available at https://github.com/dibbla/Quantized-Evolution-Strategies .
TACLer: Tailored Curriculum Reinforcement Learning for Efficient Reasoning
Jan 29, 2026Large Language Models (LLMs) have shown remarkable performance on complex reasoning tasks, especially when equipped with long chain-of-thought (CoT) reasoning. However, eliciting long CoT typically requires large-scale reinforcement learning (RL) training, while often leading to overthinking with redundant intermediate steps. To improve learning and reasoning efficiency, while preserving or even enhancing performance, we propose TACLer, a model-tailored curriculum reinforcement learning framework that gradually increases the complexity of the data based on the model's proficiency in multi-stage RL training. TACLer features two core components: (i) tailored curriculum learning that determines what knowledge the model lacks and needs to learn in progressive stages; (ii) a hybrid Thinking/NoThinking reasoning paradigm that balances accuracy and efficiency by enabling or disabling the Thinking mode. Our experiments show that TACLer yields a twofold advantage in learning and reasoning: (i) it reduces computational cost, cutting training compute by over 50% compared to long thinking models and reducing inference token usage by over 42% relative to the base model; and (ii) it improves accuracy by over 9% on the base model, consistently outperforming state-of-the-art Nothinking and Thinking baselines across four math datasets with complex problems.
Knowledge is Not Enough: Injecting RL Skills for Continual Adaptation
Jan 16, 2026Large Language Models (LLMs) face the "knowledge cutoff" challenge, where their frozen parametric memory prevents direct internalization of new information. While Supervised Fine-Tuning (SFT) is commonly used to update model knowledge, it often updates factual content without reliably improving the model's ability to use the newly incorporated information for question answering or decision-making. Reinforcement Learning (RL) is essential for acquiring reasoning skills; however, its high computational cost makes it impractical for efficient online adaptation. We empirically observe that the parameter updates induced by SFT and RL are nearly orthogonal. Based on this observation, we propose Parametric Skill Transfer (PaST), a framework that supports modular skill transfer for efficient and effective knowledge adaptation. By extracting a domain-agnostic Skill Vector from a source domain, we can linearly inject knowledge manipulation skills into a target model after it has undergone lightweight SFT on new data. Experiments on knowledge-incorporation QA (SQuAD, LooGLE) and agentic tool-use benchmarks (ToolBench) demonstrate the effectiveness of our method. On SQuAD, PaST outperforms the state-of-the-art self-editing SFT baseline by up to 9.9 points. PaST further scales to long-context QA on LooGLE with an 8.0-point absolute accuracy gain, and improves zero-shot ToolBench success rates by +10.3 points on average with consistent gains across tool categories, indicating strong scalability and cross-domain transferability of the Skill Vector.
Seed-Prover 1.5: Mastering Undergraduate-Level Theorem Proving via Learning from Experience
Dec 19, 2025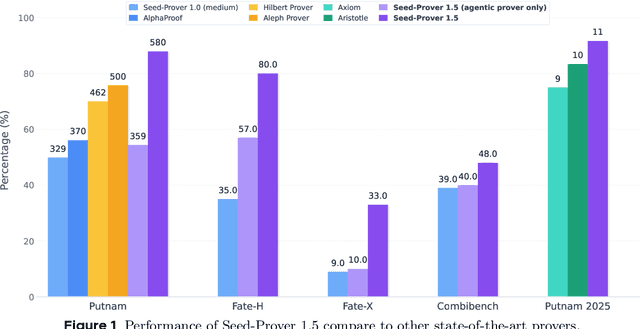

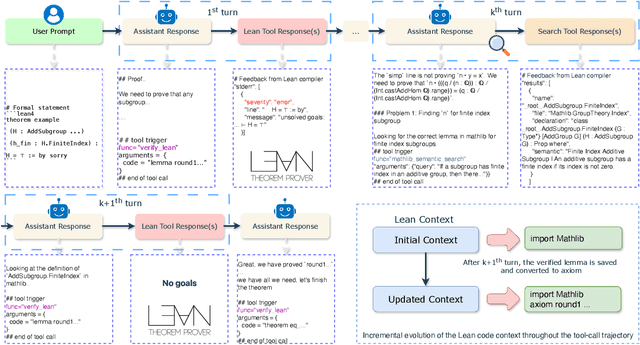

Large language models have recently made significant progress to generate rigorous mathematical proofs. In contrast, utilizing LLMs for theorem proving in formal languages (such as Lean) remains challenging and computationally expensive, particularly when addressing problems at the undergraduate level and beyond. In this work, we present \textbf{Seed-Prover 1.5}, a formal theorem-proving model trained via large-scale agentic reinforcement learning, alongside an efficient test-time scaling (TTS) workflow. Through extensive interactions with Lean and other tools, the model continuously accumulates experience during the RL process, substantially enhancing the capability and efficiency of formal theorem proving. Furthermore, leveraging recent advancements in natural language proving, our TTS workflow efficiently bridges the gap between natural and formal languages. Compared to state-of-the-art methods, Seed-Prover 1.5 achieves superior performance with a smaller compute budget. It solves \textbf{88\% of PutnamBench} (undergraduate-level), \textbf{80\% of Fate-H} (graduate-level), and \textbf{33\% of Fate-X} (PhD-level) problems. Notably, using our system, we solved \textbf{11 out of 12 problems} from Putnam 2025 within 9 hours. Our findings suggest that scaling learning from experience, driven by high-quality formal feedback, holds immense potential for the future of formal mathematical reasoning.