 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantized Evolution Strategies: High-precision Fine-tuning of Quantized LLMs at Low-precision Cost
Feb 03, 2026Post-Training Quantization (PTQ) is essential for deploying Large Language Models (LLMs) on memory-constrained devices, yet it renders models static and difficult to fine-tune. Standard fine-tuning paradigms, including Reinforcement Learning (RL), fundamentally rely on backpropagation and high-precision weights to compute gradients. Thus they cannot be used on quantized models, where the parameter space is discrete and non-differentiable. While Evolution Strategies (ES) offer a backpropagation-free alternative, optimization of the quantized parameters can still fail due to vanishing or inaccurate gradient. This paper introduces Quantized Evolution Strategies (QES), an optimization paradigm that performs full-parameter fine-tuning directly in the quantized space. QES is based on two innovations: (1) it integrates accumulated error feedback to preserve high-precision gradient signals, and (2) it utilizes a stateless seed replay to reduce memory usage to low-precision inference levels. QES significantly outperforms the state-of-the-art zeroth-order fine-tuning method on arithmetic reasoning tasks, making direct fine-tuning for quantized models possible. It therefore opens up the possibility for scaling up LLMs entirely in the quantized space. The source code is available at https://github.com/dibbla/Quantized-Evolution-Strategies .
PhySense: Principle-Based Physics Reasoning Benchmarking for Large Language Models
May 30, 2025



Large language models (LLMs) have rapidly advanced and are increasingly capable of tackling complex scientific problems, including those in physics. Despite this progress, current LLMs often fail to emulate the concise, principle-based reasoning characteristic of human experts, instead generating lengthy and opaque solutions. This discrepancy highlights a crucial gap in their ability to apply core physical principles for efficient and interpretable problem solving. To systematically investigate this limitation, we introduce PhySense, a novel principle-based physics reasoning benchmark designed to be easily solvable by experts using guiding principles, yet deceptively difficult for LLMs without principle-first reasoning. Our evaluation across multiple state-of-the-art LLMs and prompt types reveals a consistent failure to align with expert-like reasoning paths, providing insights for developing AI systems with efficient, robust and interpretable principle-based scientific reasoning.
Advancing AI-Scientist Understanding: Making LLM Think Like a Physicist with Interpretable Reasoning
Apr 02, 2025



Large Language Models (LLMs) are playing an expanding role in physics research by enhancing reasoning, symbolic manipulation, and numerical computation. However, ensuring the reliability and interpretability of their outputs remains a significant challenge. In our framework, we conceptualize the collaboration between AI and human scientists as a dynamic interplay among three modules: the reasoning module, the interpretation module, and the AI-scientist interaction module. Recognizing that effective physics reasoning demands rigorous logical consistency, quantitative precision, and deep integration with established theoretical models, we introduce the interpretation module to improve the understanding of AI-generated outputs, which is not previously explored in the literature. This module comprises multiple specialized agents, including summarizers, model builders, UI builders, and testers, which collaboratively structure LLM outputs within a physically grounded framework, by constructing a more interpretable science model. A case study demonstrates that our approach enhances transparency, facilitates validation, and strengthens AI-augmented reasoning in scientific discovery.
Provably Efficient Convergence of Primal-Dual Actor-Critic with Nonlinear Function Approximation
Feb 28, 2022
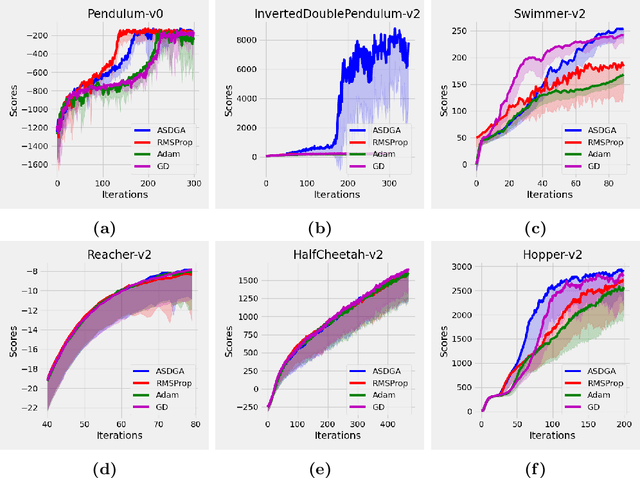
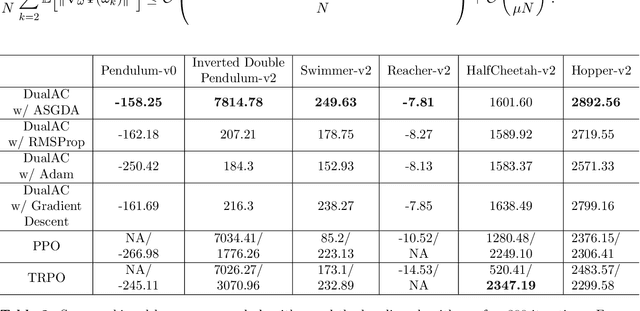
We study the convergence of the actor-critic algorithm with nonlinear function approximation under a nonconvex-nonconcave primal-dual formulation. Stochastic gradient descent ascent is applied with an adaptive proximal term for robust learning rates. We show the first efficient convergence result with primal-dual actor-critic with a convergence rate of $\mathcal{O}\left(\sqrt{\frac{\ln \left(N d G^2 \right)}{N}}\right)$ under Markovian sampling, where $G$ is the element-wise maximum of the gradient, $N$ is the number of iterations, and $d$ is the dimension of the gradient. Our result is presented with only the Polyak-\L{}ojasiewicz condition for the dual variables, which is easy to verify and applicable to a wide range of reinforcement learning (RL) scenarios. The algorithm and analysis are general enough to be applied to other RL settings, like multi-agent RL. Empirical results on OpenAI Gym continuous control tasks corroborate our theoretical findings.