 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Scalar Scores: Reinforcement Learning for Error-Aware Quality Estimation of Machine Translation
Feb 09, 2026Quality Estimation (QE) aims to assess the quality of machine translation (MT) outputs without relying on reference translations, making it essential for real-world, large-scale MT evaluation. Large Language Models (LLMs) have shown significant promise in advancing the field of quality estimation of machine translation. However, most of the QE approaches solely rely on scalar quality scores, offering no explicit information about the translation errors that should drive these judgments. Moreover, for low-resource languages where annotated QE data is limited, existing approaches struggle to achieve reliable performance. To address these challenges, we introduce the first segment-level QE dataset for English to Malayalam, a severely resource-scarce language pair in the QE domain, comprising human-annotated Direct Assessment (DA) scores and Translation Quality Remarks (TQR), which are short, contextual, free-form annotator comments that describe translation errors. We further introduce ALOPE-RL, a policy-based reinforcement learning framework that trains efficient adapters based on policy rewards derived from DA score and TQR. Integrating error-aware rewards with ALOPE-RL, enables LLMs to reason about translation quality beyond numeric scores. Despite being trained on a small-scale QE dataset, ALOPE-RL achieves state-of-the-art performance on English to Malayalam QE using compact LLMs (<=4B parameters}) fine-tuned with LoRA and 4-bit quantization, outperforming both larger LLM-based baselines and leading encoder-based QE models. Our results demonstrate that error-aware, policy-based learning can deliver strong QE performance under limited data and compute budgets. We release our dataset, code, and trained models to support future research.
Automatically Generating Chinese Homophone Words to Probe Machine Translation Estimation Systems
Mar 20, 2025



Evaluating machine translation (MT) of user-generated content (UGC) involves unique challenges such as checking whether the nuance of emotions from the source are preserved in the target text. Recent studies have proposed emotion-related datasets, frameworks and models to automatically evaluate MT quality of Chinese UGC, without relying on reference translations. However, whether these models are robust to the challenge of preserving emotional nuances has been left largely unexplored. To address this gap, we introduce a novel method inspired by information theory which generates challenging Chinese homophone words related to emotions, by leveraging the concept of self-information. Our approach generates homophones that were observed to cause translation errors in emotion preservation, and exposes vulnerabilities in MT systems and their evaluation methods when tackling emotional UGC. We evaluate the efficacy of our method using human evaluation for the quality of these generated homophones, and compare it with an existing one, showing that our method achieves higher correlation with human judgments. The generated Chinese homophones, along with their manual translations, are utilized to generate perturbations and to probe the robustness of existing quality evaluation models, including models trained using multi-task learning, fine-tuned variants of multilingual language models, as well as large language models (LLMs). Our results indicate that LLMs with larger size exhibit higher stability and robustness to such perturbations. We release our data and code for reproducibility and further research.
Integrating automatic speech recognition into remote healthcare interpreting: A pilot study of its impact on interpreting quality
Feb 05, 2025This paper reports on the results from a pilot study investigating the impact of automatic speech recognition (ASR) technology on interpreting quality in remote healthcare interpreting settings. Employing a within-subjects experiment design with four randomised conditions, this study utilises scripted medical consultations to simulate dialogue interpreting tasks. It involves four trainee interpreters with a language combination of Chinese and English. It also gathers participants' experience and perceptions of ASR support through cued retrospective reports and semi-structured interviews. Preliminary data suggest that the availability of ASR, specifically the access to full ASR transcripts and to ChatGPT-generated summaries based on ASR, effectively improved interpreting quality. Varying types of ASR output had different impacts on the distribution of interpreting error types. Participants reported similar interactive experiences with the technology, expressing their preference for full ASR transcripts. This pilot study shows encouraging results of applying ASR to dialogue-based healthcare interpreting and offers insights into the optimal ways to present ASR output to enhance interpreter experience and performance. However, it should be emphasised that the main purpose of this study was to validate the methodology and that further research with a larger sample size is necessary to confirm these findings.
Are Large Language Models State-of-the-art Quality Estimators for Machine Translation of User-generated Content?
Oct 08, 2024This paper investigates whether large language models (LLMs) are state-of-the-art quality estimators for machine translation of user-generated content (UGC) that contains emotional expressions, without the use of reference translations. To achieve this, we employ an existing emotion-related dataset with human-annotated errors and calculate quality evaluation scores based on the Multi-dimensional Quality Metrics. We compare the accuracy of several LLMs with that of our fine-tuned baseline models, under in-context learning and parameter-efficient fine-tuning (PEFT) scenarios. We find that PEFT of LLMs leads to better performance in score prediction with human interpretable explanations than fine-tuned models. However, a manual analysis of LLM outputs reveals that they still have problems such as refusal to reply to a prompt and unstable output while evaluating machine translation of UGC.
What do Large Language Models Need for Machine Translation Evaluation?
Oct 04, 2024



Leveraging large language models (LLMs) for various natural language processing tasks has led to superlative claims about their performance. For the evaluation of machine translation (MT), existing research shows that LLMs are able to achieve results comparable to fine-tuned multilingual pre-trained language models. In this paper, we explore what translation information, such as the source, reference, translation errors and annotation guidelines, is needed for LLMs to evaluate MT quality. In addition, we investigate prompting techniques such as zero-shot, Chain of Thought (CoT) and few-shot prompting for eight language pairs covering high-, medium- and low-resource languages, leveraging varying LLM variants. Our findings indicate the importance of reference translations for an LLM-based evaluation. While larger models do not necessarily fare better, they tend to benefit more from CoT prompting, than smaller models. We also observe that LLMs do not always provide a numerical score when generating evaluations, which poses a question on their reliability for the task. Our work presents a comprehensive analysis for resource-constrained and training-less LLM-based evaluation of machine translation. We release the accrued prompt templates, code and data publicly for reproducibility.
Better Transcription of UK Supreme Court Hearings
Dec 22, 2022Transcription of legal proceedings is very important to enable access to justice. However, speech transcription is an expensive and slow process. In this paper we describe part of a combined research and industrial project for building an automated transcription tool designed specifically for the Justice sector in the UK. We explain the challenges involved in transcribing court room hearings and the Natural Language Processing (NLP) techniques we employ to tackle these challenges. We will show that fine-tuning a generic off-the-shelf pre-trained Automatic Speech Recognition (ASR) system with an in-domain language model as well as infusing common phrases extracted with a collocation detection model can improve not only the Word Error Rate (WER) of the transcribed hearings but avoid critical errors that are specific of the legal jargon and terminology commonly used in British courts.
PLOD: An Abbreviation Detection Dataset for Scientific Documents
Apr 28, 2022
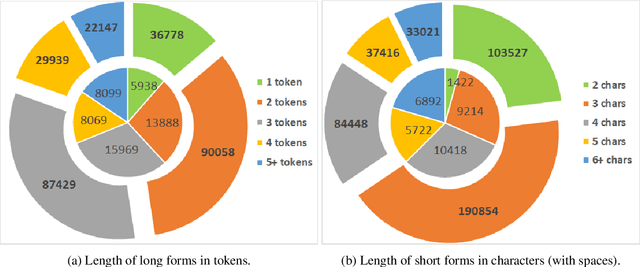
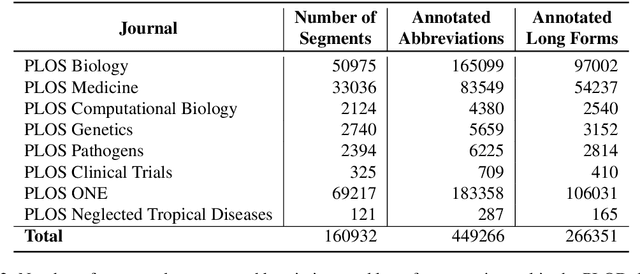
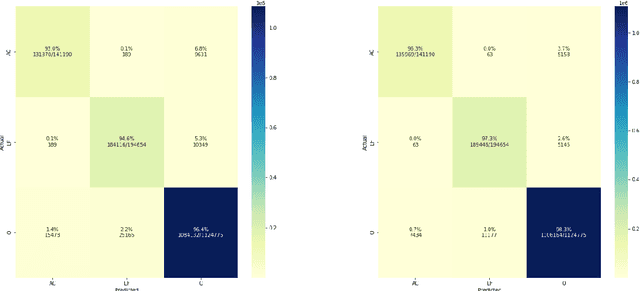
The detection and extraction of abbreviations from unstructured texts can help to improve the performance of Natural Language Processing tasks, such as machine translation and information retrieval. However, in terms of publicly available datasets, there is not enough data for training deep-neural-networks-based models to the point of generalising well over data. This paper presents PLOD, a large-scale dataset for abbreviation detection and extraction that contains 160k+ segments automatically annotated with abbreviations and their long forms. We performed manual validation over a set of instances and a complete automatic validation for this dataset. We then used it to generate several baseline models for detecting abbreviations and long forms. The best models achieved an F1-score of 0.92 for abbreviations and 0.89 for detecting their corresponding long forms. We release this dataset along with our code and all the models publicly in https://github.com/surrey-nlp/PLOD-AbbreviationDetection
An Ensemble Approach to Acronym Extraction using Transformers
Jan 09, 2022
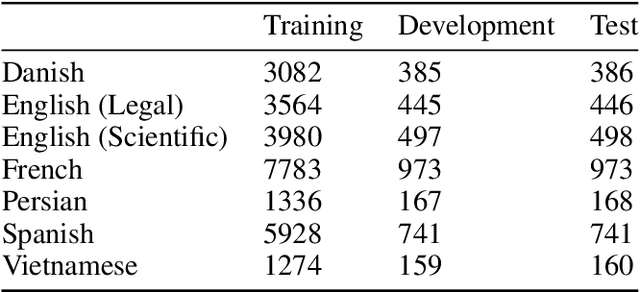
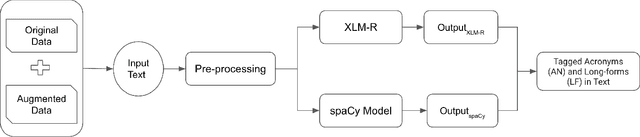
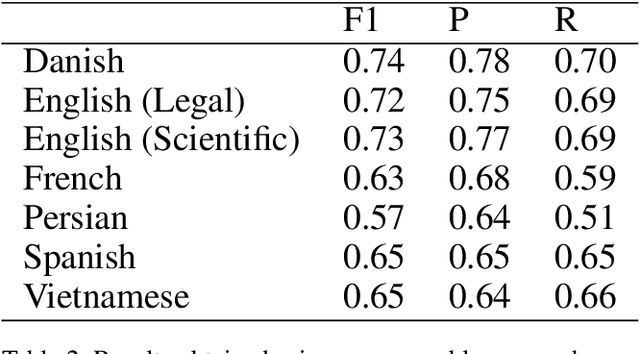
Acronyms are abbreviated units of a phrase constructed by using initial components of the phrase in a text. Automatic extraction of acronyms from a text can help various Natural Language Processing tasks like machine translation, information retrieval, and text summarisation. This paper discusses an ensemble approach for the task of Acronym Extraction, which utilises two different methods to extract acronyms and their corresponding long forms. The first method utilises a multilingual contextual language model and fine-tunes the model to perform the task. The second method relies on a convolutional neural network architecture to extract acronyms and append them to the output of the previous method. We also augment the official training dataset with additional training samples extracted from several open-access journals to help improve the task performance. Our dataset analysis also highlights the noise within the current task dataset. Our approach achieves the following macro-F1 scores on test data released with the task: Danish (0.74), English-Legal (0.72), English-Scientific (0.73), French (0.63), Persian (0.57), Spanish (0.65), Vietnamese (0.65). We release our code and models publicly.
Pushing the Right Buttons: Adversarial Evaluation of Quality Estimation
Sep 22, 2021
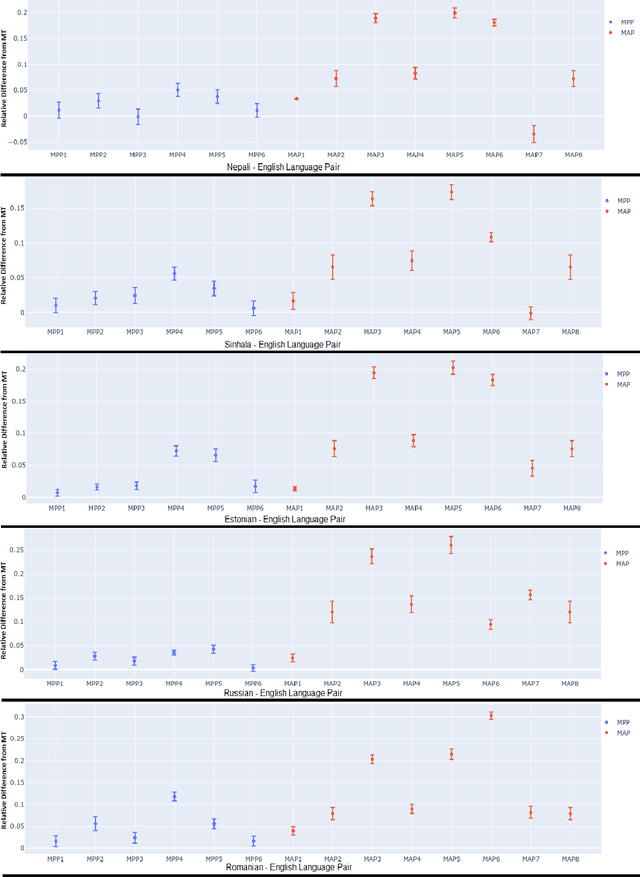

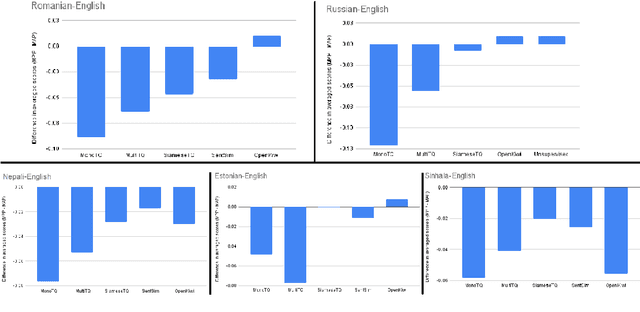
Current Machine Translation (MT) systems achieve very good results on a growing variety of language pairs and datasets. However, they are known to produce fluent translation outputs that can contain important meaning errors, thus undermining their reliability in practice. Quality Estimation (QE) is the task of automatically assessing the performance of MT systems at test time. Thus, in order to be useful, QE systems should be able to detect such errors. However, this ability is yet to be tested in the current evaluation practices, where QE systems are assessed only in terms of their correlation with human judgements. In this work, we bridge this gap by proposing a general methodology for adversarial testing of QE for MT. First, we show that despite a high correlation with human judgements achieved by the recent SOTA, certain types of meaning errors are still problematic for QE to detect. Second, we show that on average, the ability of a given model to discriminate between meaning-preserving and meaning-altering perturbations is predictive of its overall performance, thus potentially allowing for comparing QE systems without relying on manual quality annotation.