 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSigma-MoE-Tiny Technical Report
Dec 19, 2025



Mixture-of-Experts (MoE) has emerged as a promising paradigm for foundation models due to its efficient and powerful scalability. In this work, we present Sigma-MoE-Tiny, an MoE language model that achieves the highest sparsity compared to existing open-source models. Sigma-MoE-Tiny employs fine-grained expert segmentation with up to 96 experts per layer, while activating only one expert for each token, resulting in 20B total parameters with just 0.5B activated. The major challenge introduced by such extreme sparsity lies in expert load balancing. We find that the widely-used load balancing loss tends to become ineffective in the lower layers under this setting. To address this issue, we propose a progressive sparsification schedule aiming to balance expert utilization and training stability. Sigma-MoE-Tiny is pre-trained on a diverse and high-quality corpus, followed by post-training to further unlock its capabilities. The entire training process remains remarkably stable, with no occurrence of irrecoverable loss spikes. Comprehensive evaluations reveal that, despite activating only 0.5B parameters, Sigma-MoE-Tiny achieves top-tier performance among counterparts of comparable or significantly larger scale. In addition, we provide an in-depth discussion of load balancing in highly sparse MoE models, offering insights for advancing sparsity in future MoE architectures. Project page: https://qghuxmu.github.io/Sigma-MoE-Tiny Code: https://github.com/microsoft/ltp-megatron-lm
SIGMA: An AI-Empowered Training Stack on Early-Life Hardware
Dec 15, 2025



An increasing variety of AI accelerators is being considered for large-scale training. However, enabling large-scale training on early-life AI accelerators faces three core challenges: frequent system disruptions and undefined failure modes that undermine reliability; numerical errors and training instabilities that threaten correctness and convergence; and the complexity of parallelism optimization combined with unpredictable local noise that degrades efficiency. To address these challenges, SIGMA is an open-source training stack designed to improve the reliability, stability, and efficiency of large-scale distributed training on early-life AI hardware. The core of this initiative is the LUCIA TRAINING PLATFORM (LTP), the system optimized for clusters with early-life AI accelerators. Since its launch in March 2025, LTP has significantly enhanced training reliability and operational productivity. Over the past five months, it has achieved an impressive 94.45% effective cluster accelerator utilization, while also substantially reducing node recycling and job-recovery times. Building on the foundation of LTP, the LUCIA TRAINING FRAMEWORK (LTF) successfully trained SIGMA-MOE, a 200B MoE model, using 2,048 AI accelerators. This effort delivered remarkable stability and efficiency outcomes, achieving 21.08% MFU, state-of-the-art downstream accuracy, and encountering only one stability incident over a 75-day period. Together, these advances establish SIGMA, which not only tackles the critical challenges of large-scale training but also establishes a new benchmark for AI infrastructure and platform innovation, offering a robust, cost-effective alternative to prevailing established accelerator stacks and significantly advancing AI capabilities and scalability. The source code of SIGMA is available at https://github.com/microsoft/LuciaTrainingPlatform.
Sigma: Differential Rescaling of Query, Key and Value for Efficient Language Models
Jan 23, 2025



We introduce Sigma, an efficient large language model specialized for the system domain, empowered by a novel architecture including DiffQKV attention, and pre-trained on our meticulously collected system domain data. DiffQKV attention significantly enhances the inference efficiency of Sigma by optimizing the Query (Q), Key (K), and Value (V) components in the attention mechanism differentially, based on their varying impacts on the model performance and efficiency indicators. Specifically, we (1) conduct extensive experiments that demonstrate the model's varying sensitivity to the compression of K and V components, leading to the development of differentially compressed KV, and (2) propose augmented Q to expand the Q head dimension, which enhances the model's representation capacity with minimal impacts on the inference speed. Rigorous theoretical and empirical analyses reveal that DiffQKV attention significantly enhances efficiency, achieving up to a 33.36% improvement in inference speed over the conventional grouped-query attention (GQA) in long-context scenarios. We pre-train Sigma on 6T tokens from various sources, including 19.5B system domain data that we carefully collect and 1T tokens of synthesized and rewritten data. In general domains, Sigma achieves comparable performance to other state-of-arts models. In the system domain, we introduce the first comprehensive benchmark AIMicius, where Sigma demonstrates remarkable performance across all tasks, significantly outperforming GPT-4 with an absolute improvement up to 52.5%.
ERCache: An Efficient and Reliable Caching Framework for Large-Scale User Representations in Meta's Ads System
Oct 09, 2024



The increasing complexity of deep learning models used for calculating user representations presents significant challenges, particularly with limited computational resources and strict service-level agreements (SLAs). Previous research efforts have focused on optimizing model inference but have overlooked a critical question: is it necessary to perform user model inference for every ad request in large-scale social networks? To address this question and these challenges, we first analyze user access patterns at Meta and find that most user model inferences occur within a short timeframe. T his observation reveals a triangular relationship among model complexity, embedding freshness, and service SLAs. Building on this insight, we designed, implemented, and evaluated ERCache, an efficient and robust caching framework for large-scale user representations in ads recommendation systems on social networks. ERCache categorizes cache into direct and failover types and applies customized settings and eviction policies for each model, effectively balancing model complexity, embedding freshness, and service SLAs, even considering the staleness introduced by caching. ERCache has been deployed at Meta for over six months, supporting more than 30 ranking models while efficiently conserving computational resources and complying with service SLA requirements.
CrossoverScheduler: Overlapping Multiple Distributed Training Applications in a Crossover Manner
Mar 14, 2021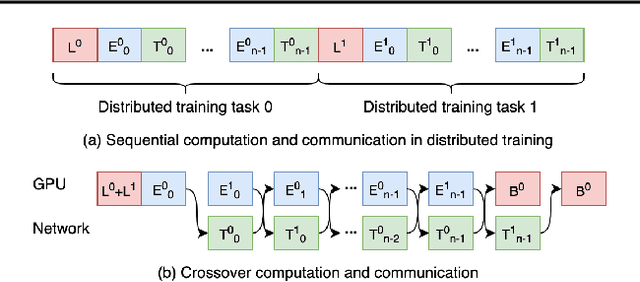
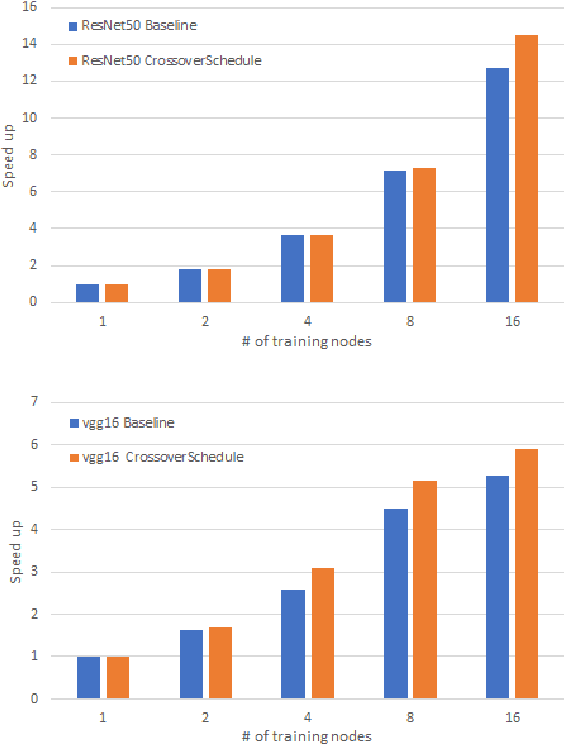
Distributed deep learning workloads include throughput-intensive training tasks on the GPU clusters, where the Distributed Stochastic Gradient Descent (SGD) incurs significant communication delays after backward propagation, forces workers to wait for the gradient synchronization via a centralized parameter server or directly in decentralized workers. We present CrossoverScheduler, an algorithm that enables communication cycles of a distributed training application to be filled by other applications through pipelining communication and computation. With CrossoverScheduler, the running performance of distributed training can be significantly improved without sacrificing convergence rate and network accuracy. We achieve so by introducing Crossover Synchronization which allows multiple distributed deep learning applications to time-share the same GPU alternately. The prototype of CrossoverScheduler is built and integrated with Horovod. Experiments on a variety of distributed tasks show that CrossoverScheduler achieves 20% \times speedup for image classification tasks on ImageNet dataset.
3D Dense Separated Convolution Module for Volumetric Image Analysis
May 14, 2019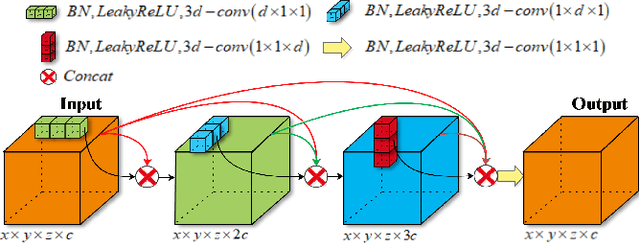
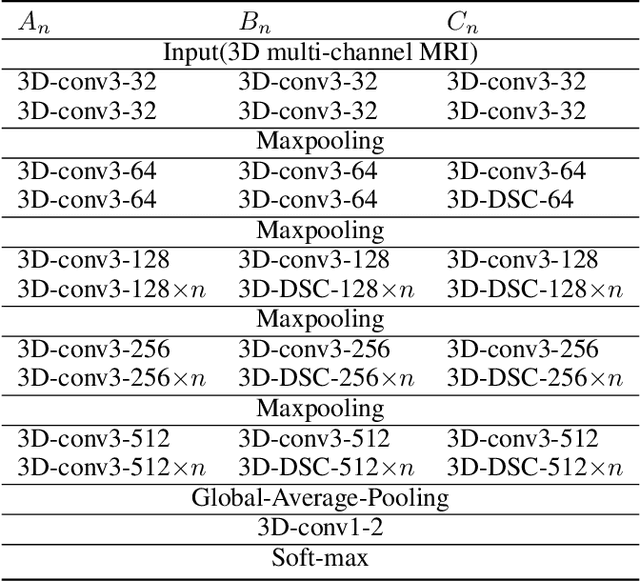
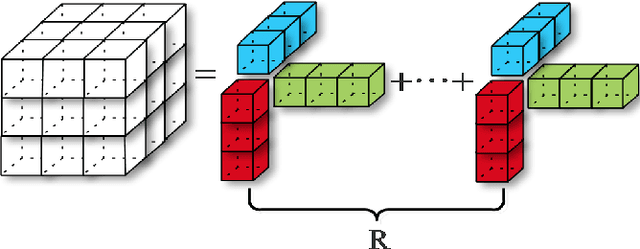
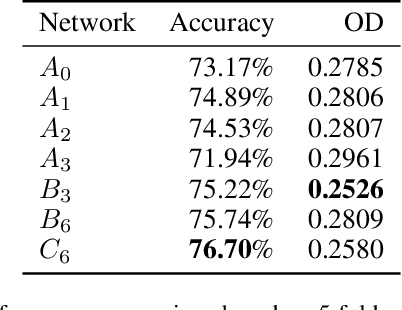
With the thriving of deep learning, 3D Convolutional Neural Networks have become a popular choice in volumetric image analysis due to their impressive 3D contexts mining ability. However, the 3D convolutional kernels will introduce a significant increase in the amount of trainable parameters. Considering the training data is often limited in biomedical tasks, a tradeoff has to be made between model size and its representational power. To address this concern, in this paper, we propose a novel 3D Dense Separated Convolution (3D-DSC) module to replace the original 3D convolutional kernels. The 3D-DSC module is constructed by a series of densely connected 1D filters. The decomposition of 3D kernel into 1D filters reduces the risk of over-fitting by removing the redundancy of 3D kernels in a topologically constrained manner, while providing the infrastructure for deepening the network. By further introducing nonlinear layers and dense connections between 1D filters, the network's representational power can be significantly improved while maintaining a compact architecture. We demonstrate the superiority of 3D-DSC on volumetric image classification and segmentation, which are two challenging tasks often encountered in biomedical image computing.
Non-flat Ground Detection Based on A Local Descriptor
Jun 06, 2018
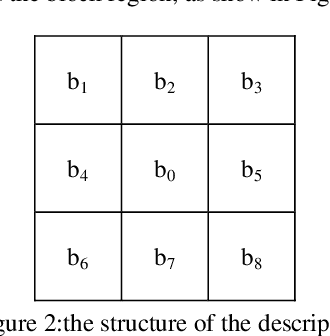

The detection of road and free space remains challenging for non-flat plane, especially with the varying latitudinal and longitudinal slope or in the case of multi-ground plane. In this paper, we propose a framework of the ground plane detection with stereo vision. The main contribution of this paper is a newly proposed descriptor which is implemented in the disparity image to obtain a disparity texture image. The ground plane regions can be distinguished from their surroundings effectively in the disparity texture image. Because the descriptor is implemented in the local area of the image, it can address well the problem of non-flat plane. And we also present a complete framework to detect the ground plane regions base on the disparity texture image with convolutional neural network architecture.