 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResilient AI Supercomputer Networking using MRC and SRv6
May 05, 2026Tail latency dominates the performance of synchronous pretraining jobs when running at very large scales. We describe a three-pronged approach: (1) a new RDMA-based transport protocol, MRC, sprays across many paths and actively load-balances between them, eliminating the issue of flow collisions (2) the use of multi-plane Clos topologies to get the benefits of high switch radix and redundancy, allowing training clusters well over 100K GPUs to be built as two-tier topologies while increasing physical redundancy, and (3) the use of static source-routing using SRv6 to allow MRC the freedom to bypass failures by itself. We describe our experiences running MRC and static SRv6 routing in production in OpenAI and Microsoft's largest training clusters, where it has been used to train the latest frontier models. We demonstrate how MRC allows AI training jobs to ride out many network failures that previously would have interrupted training.
MSCCL++: Rethinking GPU Communication Abstractions for Cutting-edge AI Applications
Apr 11, 2025

Modern cutting-edge AI applications are being developed over fast-evolving, heterogeneous, nascent hardware devices. This requires frequent reworking of the AI software stack to adopt bottom-up changes from new hardware, which takes time for general-purpose software libraries. Consequently, real applications often develop custom software stacks optimized for their specific workloads and hardware. Custom stacks help quick development and optimization, but incur a lot of redundant efforts across applications in writing non-portable code. This paper discusses an alternative communication library interface for AI applications that offers both portability and performance by reducing redundant efforts while maintaining flexibility for customization. We present MSCCL++, a novel abstraction of GPU communication based on separation of concerns: (1) a primitive interface provides a minimal hardware abstraction as a common ground for software and hardware developers to write custom communication, and (2) higher-level portable interfaces and specialized implementations enable optimization for different hardware environments. This approach makes the primitive interface reusable across applications while enabling highly flexible optimization. Compared to state-of-the-art baselines (NCCL, RCCL, and MSCCL), MSCCL++ achieves speedups of up to 3.8$\times$ for collective communication and up to 15\% for real-world AI inference workloads. MSCCL++ is in production of multiple AI services provided by Microsoft Azure, and is also adopted by RCCL, the GPU collective communication library maintained by AMD. MSCCL++ is open-source and available at https://github.com/microsoft/mscclpp.
Tutel: Adaptive Mixture-of-Experts at Scale
Jun 07, 2022
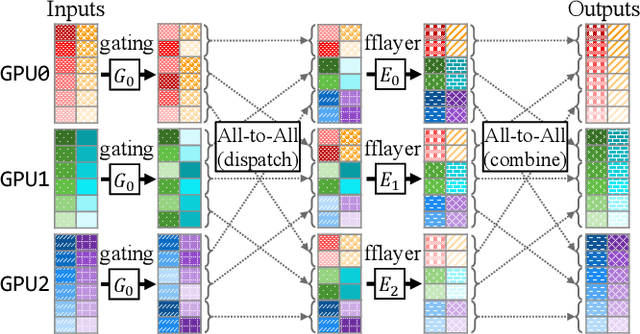

In recent years, Mixture-of-Experts (MoE) has emerged as a promising technique for deep learning that can scale the model capacity to trillion-plus parameters while reducing the computing cost via sparse computation. While MoE opens a new frontier of exceedingly large models, its implementation over thousands of GPUs has been limited due to mismatch between the dynamic nature of MoE and static parallelism/pipelining of the system. We present Tutel, a highly scalable stack design and implementation for MoE with dynamically adaptive parallelism and pipelining. Tutel delivers adaptive parallelism switching and adaptive pipelining at runtime, which achieves up to 1.74x and 2.00x single MoE layer speedup, respectively. We also propose a novel two-dimensional hierarchical algorithm for MoE communication speedup that outperforms the previous state-of-the-art up to 20.7x over 2,048 GPUs. Aggregating all techniques, Tutel finally delivers 4.96x and 5.75x speedup of a single MoE layer on 16 GPUs and 2,048 GPUs, respectively, over Fairseq: Meta's Facebook AI Research Sequence-to-Sequence Toolkit (Tutel is now partially adopted by Fairseq). Tutel source code is available in public: https://github.com/microsoft/tutel . Our evaluation shows that Tutel efficiently and effectively runs a real-world MoE-based model named SwinV2-MoE, built upon Swin Transformer V2, a state-of-the-art computer vision architecture. On efficiency, Tutel accelerates SwinV2-MoE, achieving up to 1.55x and 2.11x speedup in training and inference over Fairseq, respectively. On effectiveness, the SwinV2-MoE model achieves superior accuracy in both pre-training and down-stream computer vision tasks such as COCO object detection than the counterpart dense model, indicating the readiness of Tutel for end-to-end real-world model training and inference. SwinV2-MoE is open sourced in https://github.com/microsoft/Swin-Transformer .