 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTF-GCN: A Multi-Domain Graph Convolution Network Method for Automatic Modulation Recognition via Adaptive Correlation
Apr 11, 2025



Automatic Modulation Recognition (AMR) is an essential part of Intelligent Transportation System (ITS) dynamic spectrum allocation. However, current deep learning-based AMR (DL-AMR) methods are challenged to extract discriminative and robust features at low signal-to-noise ratios (SNRs), where the representation of modulation symbols is highly interfered by noise. Furthermore, current research on GNN methods for AMR tasks generally suffers from issues related to graph structure construction and computational complexity. In this paper, we propose a Spatial-Temporal-Frequency Graph Convolution Network (STF-GCN) framework, with the temporal domain as the anchor point, to fuse spatial and frequency domain features embedded in the graph structure nodes. On this basis, an adaptive correlation-based adjacency matrix construction method is proposed, which significantly enhances the graph structure's capacity to aggregate local information into individual nodes. In addition, a PoolGAT layer is proposed to coarsen and compress the global key features of the graph, significantly reducing the computational complexity. The results of the experiments confirm that STF-GCN is able to achieve recognition performance far beyond the state-of-the-art DL-AMR algorithms, with overall accuracies of 64.35%, 66.04% and 70.95% on the RML2016.10a, RML2016.10b and RML22 datasets, respectively. Furthermore, the average recognition accuracies under low SNR conditions from -14dB to 0dB outperform the state-of-the-art (SOTA) models by 1.20%, 1.95% and 1.83%, respectively.
Opt2Skill: Imitating Dynamically-feasible Whole-Body Trajectories for Versatile Humanoid Loco-Manipulation
Sep 30, 2024



Humanoid robots are designed to perform diverse loco-manipulation tasks. However, they face challenges due to their high-dimensional and unstable dynamics, as well as the complex contact-rich nature of the tasks. Model-based optimal control methods offer precise and systematic control but are limited by high computational complexity and accurate contact sensing. On the other hand, reinforcement learning (RL) provides robustness and handles high-dimensional spaces but suffers from inefficient learning, unnatural motion, and sim-to-real gaps. To address these challenges, we introduce Opt2Skill, an end-to-end pipeline that combines model-based trajectory optimization with RL to achieve robust whole-body loco-manipulation. We generate reference motions for the Digit humanoid robot using differential dynamic programming (DDP) and train RL policies to track these trajectories. Our results demonstrate that Opt2Skill outperforms pure RL methods in both training efficiency and task performance, with optimal trajectories that account for torque limits enhancing trajectory tracking. We successfully transfer our approach to real-world applications.
PWTO: A Heuristic Approach for Trajectory Optimization in Complex Terrains
Jul 03, 2024



This paper considers a trajectory planning problem for a robot navigating complex terrains, which arises in applications ranging from autonomous mining vehicles to planetary rovers. The problem seeks to find a low-cost dynamically feasible trajectory for the robot. The problem is challenging as it requires solving a non-linear optimization problem that often has many local minima due to the complex terrain. To address the challenge, we propose a method called Pareto-optimal Warm-started Trajectory Optimization (PWTO) that attempts to combine the benefits of graph search and trajectory optimization, two very different approaches to planning. PWTO first creates a state lattice using simplified dynamics of the robot and leverages a multi-objective graph search method to obtain a set of paths. Each of the paths is then used to warm-start a local trajectory optimization process, so that different local minima are explored to find a globally low-cost solution. In our tests, the solution cost computed by PWTO is often less than half of the costs computed by the baselines. In addition, we verify the trajectories generated by PWTO in Gazebo simulation in complex terrains with both wheeled and quadruped robots. The code of this paper is open sourced and can be found at https://github.com/rap-lab-org/public_pwto.
Propagative Distance Optimization for Constrained Inverse Kinematics
Jun 17, 2024This paper investigates a constrained inverse kinematic (IK) problem that seeks a feasible configuration of an articulated robot under various constraints such as joint limits and obstacle collision avoidance. Due to the high-dimensionality and complex constraints, this problem is often solved numerically via iterative local optimization. Classic local optimization methods take joint angles as the decision variable, which suffers from non-linearity caused by the trigonometric constraints. Recently, distance-based IK methods have been developed as an alternative approach that formulates IK as an optimization over the distances among points attached to the robot and the obstacles. Although distance-based methods have demonstrated unique advantages, they still suffer from low computational efficiency, since these approaches usually ignore the chain structure in the kinematics of serial robots. This paper proposes a new method called propagative distance optimization for constrained inverse kinematics (PDO-IK), which captures and leverages the chain structure in the distance-based formulation and expedites the optimization by computing forward kinematics and the Jacobian propagatively along the kinematic chain. Test results show that PDO-IK runs up to two orders of magnitude faster than the existing distance-based methods under joint limits constraints and obstacle avoidance constraints. It also achieves up to three times higher success rates than the conventional joint-angle-based optimization methods for IK problems. The high runtime efficiency of PDO-IK allows the real-time computation (10$-$1500 Hz) and enables a simulated humanoid robot with 19 degrees of freedom (DoFs) to avoid moving obstacles, which is otherwise hard to achieve with the baselines.
DytanVO: Joint Refinement of Visual Odometry and Motion Segmentation in Dynamic Environments
Sep 24, 2022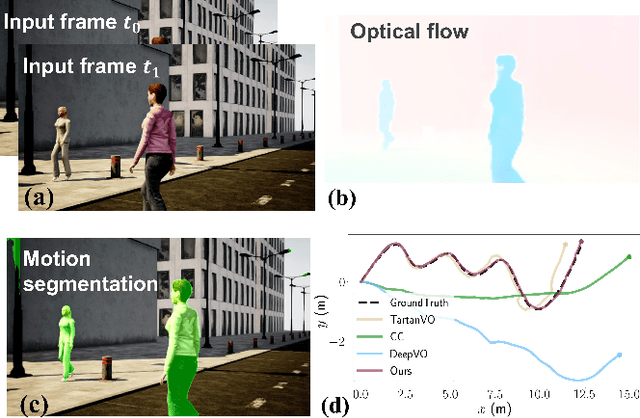
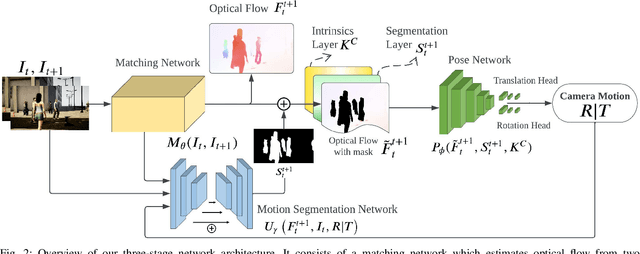
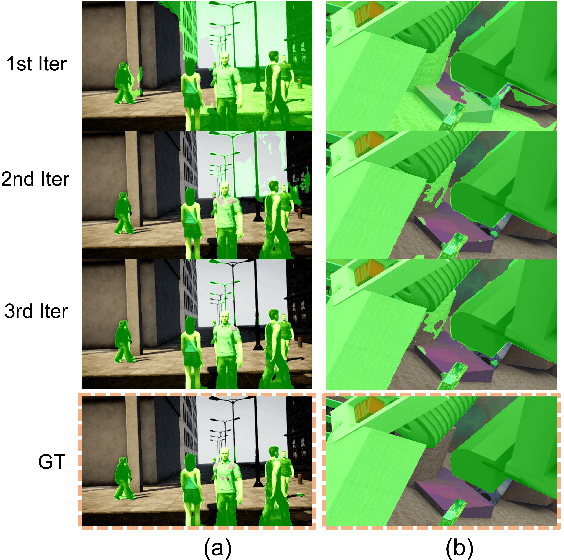
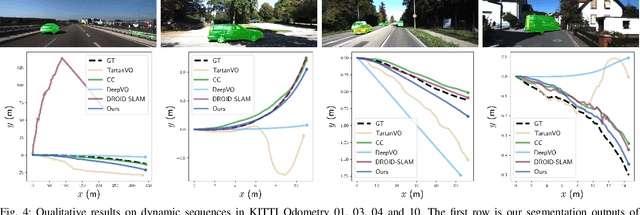
Learning-based visual odometry (VO) algorithms achieve remarkable performance on common static scenes, benefiting from high-capacity models and massive annotated data, but tend to fail in dynamic, populated environments. Semantic segmentation is largely used to discard dynamic associations before estimating camera motions but at the cost of discarding static features and is hard to scale up to unseen categories. In this paper, we leverage the mutual dependence between camera ego-motion and motion segmentation and show that both can be jointly refined in a single learning-based framework. In particular, we present DytanVO, the first supervised learning-based VO method that deals with dynamic environments. It takes two consecutive monocular frames in real-time and predicts camera ego-motion in an iterative fashion. Our method achieves an average improvement of 27.7% in ATE over state-of-the-art VO solutions in real-world dynamic environments, and even performs competitively among dynamic visual SLAM systems which optimize the trajectory on the backend. Experiments on plentiful unseen environments also demonstrate our method's generalizability.
Dynamic Dense RGB-D SLAM using Learning-based Visual Odometry
May 12, 2022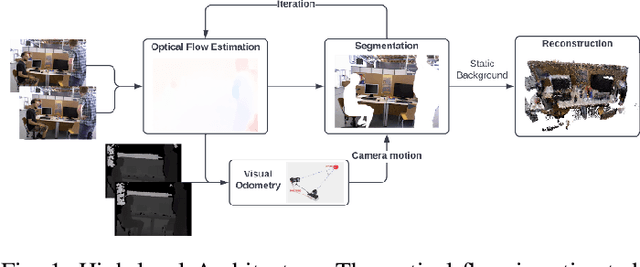
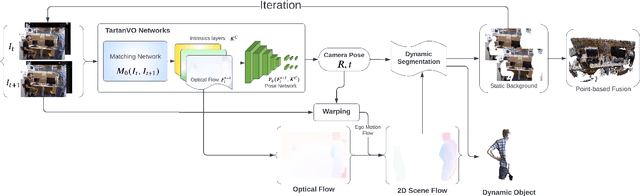
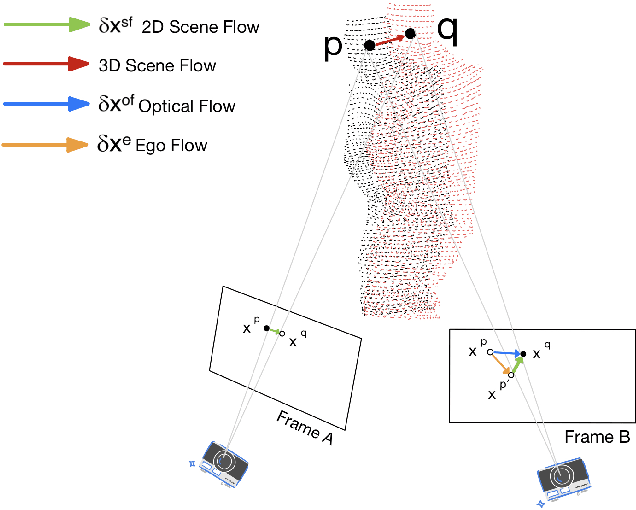
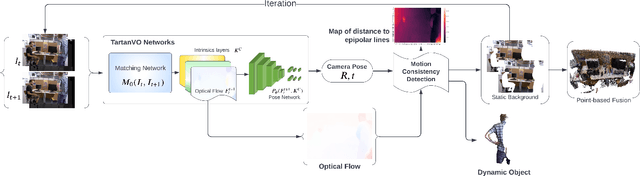
We propose a dense dynamic RGB-D SLAM pipeline based on a learning-based visual odometry, TartanVO. TartanVO, like other direct methods rather than feature-based, estimates camera pose through dense optical flow, which only applies to static scenes and disregards dynamic objects. Due to the color constancy assumption, optical flow is not able to differentiate between dynamic and static pixels. Therefore, to reconstruct a static map through such direct methods, our pipeline resolves dynamic/static segmentation by leveraging the optical flow output, and only fuse static points into the map. Moreover, we rerender the input frames such that the dynamic pixels are removed and iteratively pass them back into the visual odometry to refine the pose estimate.