 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Concept-to-Appearance Guidance for Multi-Subject Image Generation
Feb 03, 2026Multi-subject image generation aims to synthesize images that faithfully preserve the identities of multiple reference subjects while following textual instructions. However, existing methods often suffer from identity inconsistency and limited compositional control, as they rely on diffusion models to implicitly associate text prompts with reference images. In this work, we propose Hierarchical Concept-to-Appearance Guidance (CAG), a framework that provides explicit, structured supervision from high-level concepts to fine-grained appearances. At the conceptual level, we introduce a VAE dropout training strategy that randomly omits reference VAE features, encouraging the model to rely more on robust semantic signals from a Visual Language Model (VLM) and thereby promoting consistent concept-level generation in the absence of complete appearance cues. At the appearance level, we integrate the VLM-derived correspondences into a correspondence-aware masked attention module within the Diffusion Transformer (DiT). This module restricts each text token to attend only to its matched reference regions, ensuring precise attribute binding and reliable multi-subject composition. Extensive experiments demonstrate that our method achieves state-of-the-art performance on the multi-subject image generation, substantially improving prompt following and subject consistency.
Phase Transitions for Feature Learning in Neural Networks
Feb 01, 2026According to a popular viewpoint, neural networks learn from data by first identifying low-dimensional representations, and subsequently fitting the best model in this space. Recent works provide a formalization of this phenomenon when learning multi-index models. In this setting, we are given $n$ i.i.d. pairs $({\boldsymbol x}_i,y_i)$, where the covariate vectors ${\boldsymbol x}_i\in\mathbb{R}^d$ are isotropic, and responses $y_i$ only depend on ${\boldsymbol x}_i$ through a $k$-dimensional projection ${\boldsymbol Θ}_*^{\sf T}{\boldsymbol x}_i$. Feature learning amounts to learning the latent space spanned by ${\boldsymbol Θ}_*$. In this context, we study the gradient descent dynamics of two-layer neural networks under the proportional asymptotics $n,d\to\infty$, $n/d\toδ$, while the dimension of the latent space $k$ and the number of hidden neurons $m$ are kept fixed. Earlier work establishes that feature learning via polynomial-time algorithms is possible if $δ> δ_{\text{alg}}$, for $δ_{\text{alg}}$ a threshold depending on the data distribution, and is impossible (within a certain class of algorithms) below $δ_{\text{alg}}$. Here we derive an analogous threshold $δ_{\text{NN}}$ for two-layer networks. Our characterization of $δ_{\text{NN}}$ opens the way to study the dependence of learning dynamics on the network architecture and training algorithm. The threshold $δ_{\text{NN}}$ is determined by the following scenario. Training first visits points for which the gradient of the empirical risk is large and learns the directions spanned by these gradients. Then the gradient becomes smaller and the dynamics becomes dominated by negative directions of the Hessian. The threshold $δ_{\text{NN}}$ corresponds to a phase transition in the spectrum of the Hessian in this second phase.
$\mathbb{R}^{2k}$ is Theoretically Large Enough for Embedding-based Top-$k$ Retrieval
Jan 29, 2026This paper studies the minimal dimension required to embed subset memberships ($m$ elements and ${m\choose k}$ subsets of at most $k$ elements) into vector spaces, denoted as Minimal Embeddable Dimension (MED). The tight bounds of MED are derived theoretically and supported empirically for various notions of "distances" or "similarities," including the $\ell_2$ metric, inner product, and cosine similarity. In addition, we conduct numerical simulation in a more achievable setting, where the ${m\choose k}$ subset embeddings are chosen as the centroid of the embeddings of the contained elements. Our simulation easily realizes a logarithmic dependency between the MED and the number of elements to embed. These findings imply that embedding-based retrieval limitations stem primarily from learnability challenges, not geometric constraints, guiding future algorithm design.
Do Reasoning Models Enhance Embedding Models?
Jan 29, 2026State-of-the-art embedding models are increasingly derived from decoder-only Large Language Model (LLM) backbones adapted via contrastive learning. Given the emergence of reasoning models trained via Reinforcement Learning with Verifiable Rewards (RLVR), a natural question arises: do enhanced reasoning translate to superior semantic representations when these models serve as embedding initializations? Contrary to expectation, our evaluation on MTEB and BRIGHT reveals a **null effect**: embedding models initialized from RLVR-tuned backbones yield no consistent performance advantage over their base counterparts when subjected to identical training recipes. To unpack this paradox, we introduce **H**ierarchical **R**epresentation **S**imilarity **A**nalysis (HRSA), a framework that decomposes similarity across representation, geometry, and function levels. HRSA reveals that while RLVR induces irreversible latent manifold's local geometry reorganization and reversible coordinate basis drift, it preserves the global manifold geometry and linear readout. Consequently, subsequent contrastive learning drives strong alignment between base- and reasoning-initialized models, a phenomenon we term **Manifold Realignment**. Empirically, our findings suggest that unlike Supervised Fine-Tuning (SFT), RLVR optimizes trajectories within an existing semantic landscape rather than fundamentally restructuring the landscape itself.
Structure-constrained Language-informed Diffusion Model for Unpaired Low-dose Computed Tomography Angiography Reconstruction
Jan 28, 2026The application of iodinated contrast media (ICM) improves the sensitivity and specificity of computed tomography (CT) for a wide range of clinical indications. However, overdose of ICM can cause problems such as kidney damage and life-threatening allergic reactions. Deep learning methods can generate CT images of normal-dose ICM from low-dose ICM, reducing the required dose while maintaining diagnostic power. However, existing methods are difficult to realize accurate enhancement with incompletely paired images, mainly because of the limited ability of the model to recognize specific structures. To overcome this limitation, we propose a Structure-constrained Language-informed Diffusion Model (SLDM), a unified medical generation model that integrates structural synergy and spatial intelligence. First, the structural prior information of the image is effectively extracted to constrain the model inference process, thus ensuring structural consistency in the enhancement process. Subsequently, semantic supervision strategy with spatial intelligence is introduced, which integrates the functions of visual perception and spatial reasoning, thus prompting the model to achieve accurate enhancement. Finally, the subtraction angiography enhancement module is applied, which serves to improve the contrast of the ICM agent region to suitable interval for observation. Qualitative analysis of visual comparison and quantitative results of several metrics demonstrate the effectiveness of our method in angiographic reconstruction for low-dose contrast medium CT angiography.
Adaptive Domain Shift in Diffusion Models for Cross-Modality Image Translation
Jan 26, 2026Cross-modal image translation remains brittle and inefficient. Standard diffusion approaches often rely on a single, global linear transfer between domains. We find that this shortcut forces the sampler to traverse off-manifold, high-cost regions, inflating the correction burden and inviting semantic drift. We refer to this shared failure mode as fixed-schedule domain transfer. In this paper, we embed domain-shift dynamics directly into the generative process. Our model predicts a spatially varying mixing field at every reverse step and injects an explicit, target-consistent restoration term into the drift. This in-step guidance keeps large updates on-manifold and shifts the model's role from global alignment to local residual correction. We provide a continuous-time formulation with an exact solution form and derive a practical first-order sampler that preserves marginal consistency. Empirically, across translation tasks in medical imaging, remote sensing, and electroluminescence semantic mapping, our framework improves structural fidelity and semantic consistency while converging in fewer denoising steps.
LifeAgentBench: A Multi-dimensional Benchmark and Agent for Personal Health Assistants in Digital Health
Jan 20, 2026Personalized digital health support requires long-horizon, cross-dimensional reasoning over heterogeneous lifestyle signals, and recent advances in mobile sensing and large language models (LLMs) make such support increasingly feasible. However, the capabilities of current LLMs in this setting remain unclear due to the lack of systematic benchmarks. In this paper, we introduce LifeAgentBench, a large-scale QA benchmark for long-horizon, cross-dimensional, and multi-user lifestyle health reasoning, containing 22,573 questions spanning from basic retrieval to complex reasoning. We release an extensible benchmark construction pipeline and a standardized evaluation protocol to enable reliable and scalable assessment of LLM-based health assistants. We then systematically evaluate 11 leading LLMs on LifeAgentBench and identify key bottlenecks in long-horizon aggregation and cross-dimensional reasoning. Motivated by these findings, we propose LifeAgent as a strong baseline agent for health assistant that integrates multi-step evidence retrieval with deterministic aggregation, achieving significant improvements compared with two widely used baselines. Case studies further demonstrate its potential in realistic daily-life scenarios. The benchmark is publicly available at https://anonymous.4open.science/r/LifeAgentBench-CE7B.
Dynamic Large Concept Models: Latent Reasoning in an Adaptive Semantic Space
Dec 31, 2025Large Language Models (LLMs) apply uniform computation to all tokens, despite language exhibiting highly non-uniform information density. This token-uniform regime wastes capacity on locally predictable spans while under-allocating computation to semantically critical transitions. We propose $\textbf{Dynamic Large Concept Models (DLCM)}$, a hierarchical language modeling framework that learns semantic boundaries from latent representations and shifts computation from tokens to a compressed concept space where reasoning is more efficient. DLCM discovers variable-length concepts end-to-end without relying on predefined linguistic units. Hierarchical compression fundamentally changes scaling behavior. We introduce the first $\textbf{compression-aware scaling law}$, which disentangles token-level capacity, concept-level reasoning capacity, and compression ratio, enabling principled compute allocation under fixed FLOPs. To stably train this heterogeneous architecture, we further develop a $\textbf{decoupled $μ$P parametrization}$ that supports zero-shot hyperparameter transfer across widths and compression regimes. At a practical setting ($R=4$, corresponding to an average of four tokens per concept), DLCM reallocates roughly one-third of inference compute into a higher-capacity reasoning backbone, achieving a $\textbf{+2.69$\%$ average improvement}$ across 12 zero-shot benchmarks under matched inference FLOPs.
SceneMaker: Open-set 3D Scene Generation with Decoupled De-occlusion and Pose Estimation Model
Dec 11, 2025We propose a decoupled 3D scene generation framework called SceneMaker in this work. Due to the lack of sufficient open-set de-occlusion and pose estimation priors, existing methods struggle to simultaneously produce high-quality geometry and accurate poses under severe occlusion and open-set settings. To address these issues, we first decouple the de-occlusion model from 3D object generation, and enhance it by leveraging image datasets and collected de-occlusion datasets for much more diverse open-set occlusion patterns. Then, we propose a unified pose estimation model that integrates global and local mechanisms for both self-attention and cross-attention to improve accuracy. Besides, we construct an open-set 3D scene dataset to further extend the generalization of the pose estimation model. Comprehensive experiments demonstrate the superiority of our decoupled framework on both indoor and open-set scenes. Our codes and datasets is released at https://idea-research.github.io/SceneMaker/.
TAO-Net: Two-stage Adaptive OOD Classification Network for Fine-grained Encrypted Traffic Classification
Dec 11, 2025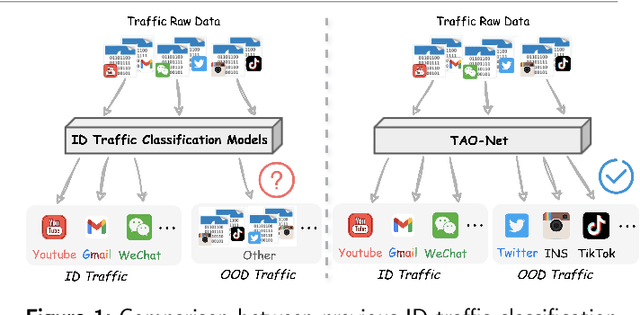

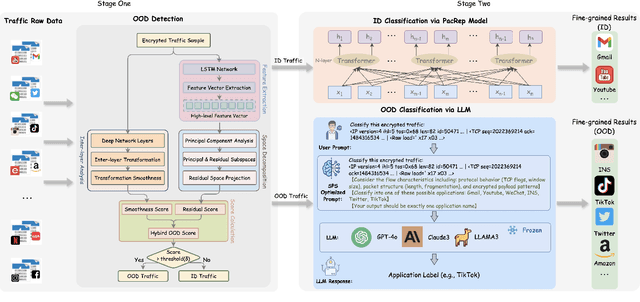
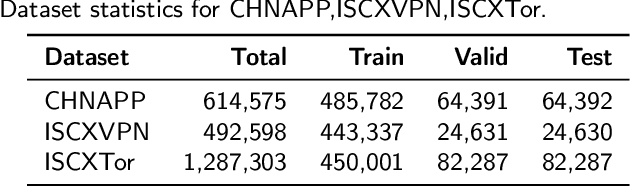
Encrypted traffic classification aims to identify applications or services by analyzing network traffic data. One of the critical challenges is the continuous emergence of new applications, which generates Out-of-Distribution (OOD) traffic patterns that deviate from known categories and are not well represented by predefined models. Current approaches rely on predefined categories, which limits their effectiveness in handling unknown traffic types. Although some methods mitigate this limitation by simply classifying unknown traffic into a single "Other" category, they fail to make a fine-grained classification. In this paper, we propose a Two-stage Adaptive OOD classification Network (TAO-Net) that achieves accurate classification for both In-Distribution (ID) and OOD encrypted traffic. The method incorporates an innovative two-stage design: the first stage employs a hybrid OOD detection mechanism that integrates transformer-based inter-layer transformation smoothness and feature analysis to effectively distinguish between ID and OOD traffic, while the second stage leverages large language models with a novel semantic-enhanced prompt strategy to transform OOD traffic classification into a generation task, enabling flexible fine-grained classification without relying on predefined labels. Experiments on three datasets demonstrate that TAO-Net achieves 96.81-97.70% macro-precision and 96.77-97.68% macro-F1, outperforming previous methods that only reach 44.73-86.30% macro-precision, particularly in identifying emerging network applications.