 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKling-Foley: Multimodal Diffusion Transformer for High-Quality Video-to-Audio Generation
Jun 24, 2025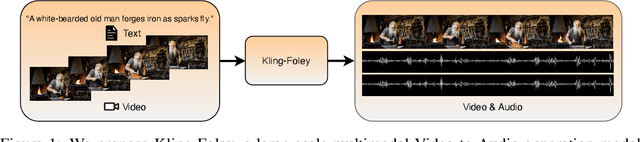
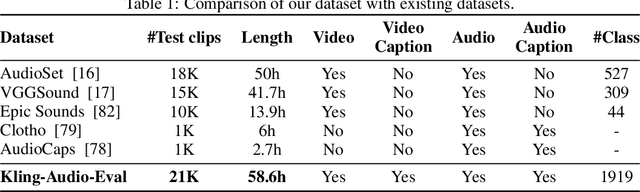
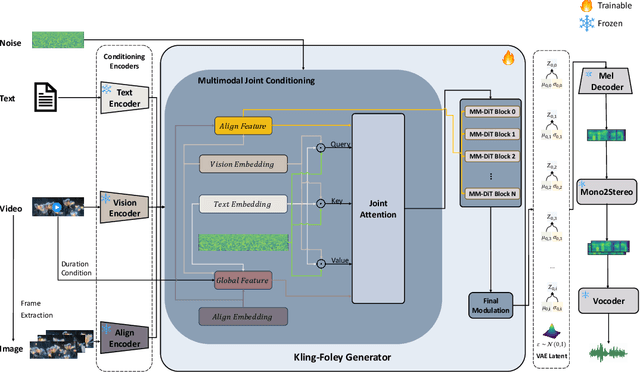
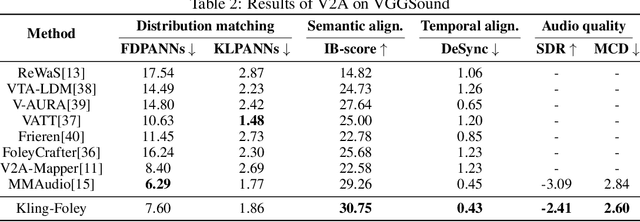
We propose Kling-Foley, a large-scale multimodal Video-to-Audio generation model that synthesizes high-quality audio synchronized with video content. In Kling-Foley, we introduce multimodal diffusion transformers to model the interactions between video, audio, and text modalities, and combine it with a visual semantic representation module and an audio-visual synchronization module to enhance alignment capabilities. Specifically, these modules align video conditions with latent audio elements at the frame level, thereby improving semantic alignment and audio-visual synchronization. Together with text conditions, this integrated approach enables precise generation of video-matching sound effects. In addition, we propose a universal latent audio codec that can achieve high-quality modeling in various scenarios such as sound effects, speech, singing, and music. We employ a stereo rendering method that imbues synthesized audio with a spatial presence. At the same time, in order to make up for the incomplete types and annotations of the open-source benchmark, we also open-source an industrial-level benchmark Kling-Audio-Eval. Our experiments show that Kling-Foley trained with the flow matching objective achieves new audio-visual SOTA performance among public models in terms of distribution matching, semantic alignment, temporal alignment and audio quality.
FIC-TSC: Learning Time Series Classification with Fisher Information Constraint
May 09, 2025



Analyzing time series data is crucial to a wide spectrum of applications, including economics, online marketplaces, and human healthcare. In particular, time series classification plays an indispensable role in segmenting different phases in stock markets, predicting customer behavior, and classifying worker actions and engagement levels. These aspects contribute significantly to the advancement of automated decision-making and system optimization in real-world applications. However, there is a large consensus that time series data often suffers from domain shifts between training and test sets, which dramatically degrades the classification performance. Despite the success of (reversible) instance normalization in handling the domain shifts for time series regression tasks, its performance in classification is unsatisfactory. In this paper, we propose \textit{FIC-TSC}, a training framework for time series classification that leverages Fisher information as the constraint. We theoretically and empirically show this is an efficient and effective solution to guide the model converge toward flatter minima, which enhances its generalizability to distribution shifts. We rigorously evaluate our method on 30 UEA multivariate and 85 UCR univariate datasets. Our empirical results demonstrate the superiority of the proposed method over 14 recent state-of-the-art methods.
STPNet: Scale-aware Text Prompt Network for Medical Image Segmentation
Apr 02, 2025Accurate segmentation of lesions plays a critical role in medical image analysis and diagnosis. Traditional segmentation approaches that rely solely on visual features often struggle with the inherent uncertainty in lesion distribution and size. To address these issues, we propose STPNet, a Scale-aware Text Prompt Network that leverages vision-language modeling to enhance medical image segmentation. Our approach utilizes multi-scale textual descriptions to guide lesion localization and employs retrieval-segmentation joint learning to bridge the semantic gap between visual and linguistic modalities. Crucially, STPNet retrieves relevant textual information from a specialized medical text repository during training, eliminating the need for text input during inference while retaining the benefits of cross-modal learning. We evaluate STPNet on three datasets: COVID-Xray, COVID-CT, and Kvasir-SEG. Experimental results show that our vision-language approach outperforms state-of-the-art segmentation methods, demonstrating the effectiveness of incorporating textual semantic knowledge into medical image analysis. The code has been made publicly on https://github.com/HUANGLIZI/STPNet.
Diffusion-Based mmWave Radar Point Cloud Enhancement Driven by Range Images
Mar 04, 2025Millimeter-wave (mmWave) radar has attracted significant attention in robotics and autonomous driving. However, despite the perception stability in harsh environments, the point cloud generated by mmWave radar is relatively sparse while containing significant noise, which limits its further development. Traditional mmWave radar enhancement approaches often struggle to leverage the effectiveness of diffusion models in super-resolution, largely due to the unnatural range-azimuth heatmap (RAH) or bird's eye view (BEV) representation. To overcome this limitation, we propose a novel method that pioneers the application of fusing range images with image diffusion models, achieving accurate and dense mmWave radar point clouds that are similar to LiDAR. Benefitting from the projection that aligns with human observation, the range image representation of mmWave radar is close to natural images, allowing the knowledge from pre-trained image diffusion models to be effectively transferred, significantly improving the overall performance. Extensive evaluations on both public datasets and self-constructed datasets demonstrate that our approach provides substantial improvements, establishing a new state-of-the-art performance in generating truly three-dimensional LiDAR-like point clouds via mmWave radar.
Power Domain Sparse Dimensional Constellation Multiple Access (PD-SDCMA): A Novel PD-NOMA for More Access Users
Feb 22, 2025With the advent of the 6G mobile communication network era, the existing non-orthogonal multiple-access (NOMA) technology faces the challenge of high successive interference in multi-user scenarios, which limits its ability to support more user access. To address this, this paper proposes a novel power-domain sparse-dimensional constellation multiple-access scheme (PD-SDCMA). Through the signal space dimension selection strategy (S2D-strategy), this scheme sparsely superposes low-dimensional constellations onto high-dimensional signal spaces, and reduces the high-order interference caused by SC by taking advantage of the non-correlation between dimensions. Specifically, PD-SDCMA reduces the successive interference between users by sparsifying the dimension allocation of constellation superposition and designs a sparse superposition method based on the theory of vector space signal representation. Simulation results show that, under the AWGN channel, PD-SDCMA significantly outperforms the traditional PD-NOMA in terms of the number of supported users under QPSK and 16QAM modulations, and also has better BER performance. This paper provides a new solution for efficient spectrum utilization in future scenarios with large-scale user access.
An Intra- and Cross-frame Topological Consistency Scheme for Semi-supervised Atherosclerotic Coronary Plaque Segmentation
Jan 14, 2025



Enhancing the precision of segmenting coronary atherosclerotic plaques from CT Angiography (CTA) images is pivotal for advanced Coronary Atherosclerosis Analysis (CAA), which distinctively relies on the analysis of vessel cross-section images reconstructed via Curved Planar Reformation. This task presents significant challenges due to the indistinct boundaries and structures of plaques and blood vessels, leading to the inadequate performance of current deep learning models, compounded by the inherent difficulty in annotating such complex data. To address these issues, we propose a novel dual-consistency semi-supervised framework that integrates Intra-frame Topological Consistency (ITC) and Cross-frame Topological Consistency (CTC) to leverage labeled and unlabeled data. ITC employs a dual-task network for simultaneous segmentation mask and Skeleton-aware Distance Transform (SDT) prediction, achieving similar prediction of topology structure through consistency constraint without additional annotations. Meanwhile, CTC utilizes an unsupervised estimator for analyzing pixel flow between skeletons and boundaries of adjacent frames, ensuring spatial continuity. Experiments on two CTA datasets show that our method surpasses existing semi-supervised methods and approaches the performance of supervised methods on CAA. In addition, our method also performs better than other methods on the ACDC dataset, demonstrating its generalization.
LLM-RG4: Flexible and Factual Radiology Report Generation across Diverse Input Contexts
Dec 16, 2024Drafting radiology reports is a complex task requiring flexibility, where radiologists tail content to available information and particular clinical demands. However, most current radiology report generation (RRG) models are constrained to a fixed task paradigm, such as predicting the full ``finding'' section from a single image, inherently involving a mismatch between inputs and outputs. The trained models lack the flexibility for diverse inputs and could generate harmful, input-agnostic hallucinations. To bridge the gap between current RRG models and the clinical demands in practice, we first develop a data generation pipeline to create a new MIMIC-RG4 dataset, which considers four common radiology report drafting scenarios and has perfectly corresponded input and output. Secondly, we propose a novel large language model (LLM) based RRG framework, namely LLM-RG4, which utilizes LLM's flexible instruction-following capabilities and extensive general knowledge. We further develop an adaptive token fusion module that offers flexibility to handle diverse scenarios with different input combinations, while minimizing the additional computational burden associated with increased input volumes. Besides, we propose a token-level loss weighting strategy to direct the model's attention towards positive and uncertain descriptions. Experimental results demonstrate that LLM-RG4 achieves state-of-the-art performance in both clinical efficiency and natural language generation on the MIMIC-RG4 and MIMIC-CXR datasets. We quantitatively demonstrate that our model has minimal input-agnostic hallucinations, whereas current open-source models commonly suffer from this problem.
VisionUnite: A Vision-Language Foundation Model for Ophthalmology Enhanced with Clinical Knowledge
Aug 05, 2024



The need for improved diagnostic methods in ophthalmology is acute, especially in the less developed regions with limited access to specialists and advanced equipment. Therefore, we introduce VisionUnite, a novel vision-language foundation model for ophthalmology enhanced with clinical knowledge. VisionUnite has been pretrained on an extensive dataset comprising 1.24 million image-text pairs, and further refined using our proposed MMFundus dataset, which includes 296,379 high-quality fundus image-text pairs and 889,137 simulated doctor-patient dialogue instances. Our experiments indicate that VisionUnite outperforms existing generative foundation models such as GPT-4V and Gemini Pro. It also demonstrates diagnostic capabilities comparable to junior ophthalmologists. VisionUnite performs well in various clinical scenarios including open-ended multi-disease diagnosis, clinical explanation, and patient interaction, making it a highly versatile tool for initial ophthalmic disease screening. VisionUnite can also serve as an educational aid for junior ophthalmologists, accelerating their acquisition of knowledge regarding both common and rare ophthalmic conditions. VisionUnite represents a significant advancement in ophthalmology, with broad implications for diagnostics, medical education, and understanding of disease mechanisms.
Are Large Language Models Possible to Conduct Cognitive Behavioral Therapy?
Jul 25, 2024



In contemporary society, the issue of psychological health has become increasingly prominent, characterized by the diversification, complexity, and universality of mental disorders. Cognitive Behavioral Therapy (CBT), currently the most influential and clinically effective psychological treatment method with no side effects, has limited coverage and poor quality in most countries. In recent years, researches on the recognition and intervention of emotional disorders using large language models (LLMs) have been validated, providing new possibilities for psychological assistance therapy. However, are LLMs truly possible to conduct cognitive behavioral therapy? Many concerns have been raised by mental health experts regarding the use of LLMs for therapy. Seeking to answer this question, we collected real CBT corpus from online video websites, designed and conducted a targeted automatic evaluation framework involving the evaluation of emotion tendency of generated text, structured dialogue pattern and proactive inquiry ability. For emotion tendency, we calculate the emotion tendency score of the CBT dialogue text generated by each model. For structured dialogue pattern, we use a diverse range of automatic evaluation metrics to compare speaking style, the ability to maintain consistency of topic and the use of technology in CBT between different models . As for inquiring to guide the patient, we utilize PQA (Proactive Questioning Ability) metric. We also evaluated the CBT ability of the LLM after integrating a CBT knowledge base to explore the help of introducing additional knowledge to enhance the model's CBT counseling ability. Four LLM variants with excellent performance on natural language processing are evaluated, and the experimental result shows the great potential of LLMs in psychological counseling realm, especially after combining with other technological means.
Rethinking Abdominal Organ Segmentation (RAOS) in the clinical scenario: A robustness evaluation benchmark with challenging cases
Jun 19, 2024



Deep learning has enabled great strides in abdominal multi-organ segmentation, even surpassing junior oncologists on common cases or organs. However, robustness on corner cases and complex organs remains a challenging open problem for clinical adoption. To investigate model robustness, we collected and annotated the RAOS dataset comprising 413 CT scans ($\sim$80k 2D images, $\sim$8k 3D organ annotations) from 413 patients each with 17 (female) or 19 (male) labelled organs, manually delineated by oncologists. We grouped scans based on clinical information into 1) diagnosis/radiotherapy (317 volumes), 2) partial excision without the whole organ missing (22 volumes), and 3) excision with the whole organ missing (74 volumes). RAOS provides a potential benchmark for evaluating model robustness including organ hallucination. It also includes some organs that can be very hard to access on public datasets like the rectum, colon, intestine, prostate and seminal vesicles. We benchmarked several state-of-the-art methods in these three clinical groups to evaluate performance and robustness. We also assessed cross-generalization between RAOS and three public datasets. This dataset and comprehensive analysis establish a potential baseline for future robustness research: \url{https://github.com/Luoxd1996/RAOS}.