 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANCHOR: Abductive Network Construction with Hierarchical Orchestration for Reliable Probability Inference in Large Language Models
May 11, 2026A central challenge in large-scale decision-making under incomplete information is estimating reliable probabilities. Recent approaches leverage Large Language Models (LLMs) to generate explanatory factors and elicit coarse-grained probability estimates. Typically, an LLM performs forward abduction to propose factors, each paired with two mutually exclusive attributes, and a Naïve Bayes model is trained over factor combinations to refine the final probabilities. However, sparse factor spaces often yield ``unknown'' outcomes, while expanding factors increases noise and spurious correlations, weakening conditional independence and degrading reliability. To address these limitations, we propose \textsc{Anchor}, an inference framework that orchestrates aggregated Bayesian inference over a hierarchically structured factor space. \textsc{Anchor} first constructs a dense and organized factor space via iterative generation and hierarchical clustering. It then performs context-aware mapping through hierarchical retrieval and refinement, substantially reducing ``unknown'' predictions. Finally, \textsc{Anchor} augments Naïve Bayes with a Causal Bayesian Network to capture latent dependencies among factors, relaxing the strict independence assumption. Experiments show that \textsc{Anchor} markedly reduces ``unknown'' predictions and produces more reliable probability estimates than direct LLM baselines, achieving state-of-the-art performance while significantly reducing time and token overhead.
DTCRS: Dynamic Tree Construction for Recursive Summarization
Apr 08, 2026Retrieval-Augmented Generation (RAG) mitigates the hallucination problem of Large Language Models (LLMs) by incorporating external knowledge. Recursive summarization constructs a hierarchical summary tree by clustering text chunks, integrating information from multiple parts of a document to provide evidence for abstractive questions involving multi-step reasoning. However, summary trees often contain a large number of redundant summary nodes, which not only increase construction time but may also negatively impact question answering. Moreover, recursive summarization is not suitable for all types of questions. We introduce DTCRS, a method that dynamically generates summary trees based on document structure and query semantics. DTCRS determines whether a summary tree is necessary by analyzing the question type. It then decomposes the question and uses the embeddings of sub-questions as initial cluster centers, reducing redundant summaries while improving the relevance between summaries and the question. Our approach significantly reduces summary tree construction time and achieves substantial improvements across three QA tasks. Additionally, we investigate the applicability of recursive summarization to different question types, providing valuable insights for future research.
GCoT-Decoding: Unlocking Deep Reasoning Paths for Universal Question Answering
Apr 08, 2026Chain-of-Thought reasoning can enhance large language models, but it requires manually designed prompts to guide the model. Recently proposed CoT-decoding enables the model to generate CoT-style reasoning paths without prompts, but it is only applicable to problems with fixed answer sets. To address this limitation, we propose a general decoding strategy GCoT-decoding that extends applicability to a broader range of question-answering tasks. GCoT-decoding employs a two-stage branching method combining Fibonacci sampling and heuristic error backtracking to generate candidate decoding paths. It then splits each path into a reasoning span and an answer span to accurately compute path confidence, and finally aggregates semantically similar paths to identify a consensus answer, replacing traditional majority voting. We conduct extensive experiments on six datasets covering both fixed and free QA tasks. Our method not only maintains strong performance on fixed QA but also achieves significant improvements on free QA, demonstrating its generality.
AGSC: Adaptive Granularity and Semantic Clustering for Uncertainty Quantification in Long-text Generation
Apr 08, 2026Large Language Models (LLMs) have demonstrated impressive capabilities in long-form generation, yet their application is hindered by the hallucination problem. While Uncertainty Quantification (UQ) is essential for assessing reliability, the complex structure makes reliable aggregation across heterogeneous themes difficult, in addition, existing methods often overlook the nuance of neutral information and suffer from the high computational cost of fine-grained decomposition. To address these challenges, we propose AGSC (Adaptive Granularity and GMM-based Semantic Clustering), a UQ framework tailored for long-form generation. AGSC first uses NLI neutral probabilities as triggers to distinguish irrelevance from uncertainty, reducing unnecessary computation. It then applies Gaussian Mixture Model (GMM) soft clustering to model latent semantic themes and assign topic-aware weights for downstream aggregation. Experiments on BIO and LongFact show that AGSC achieves state-of-the-art correlation with factuality while reducing inference time by about 60% compared to full atomic decomposition.
An Intra- and Cross-frame Topological Consistency Scheme for Semi-supervised Atherosclerotic Coronary Plaque Segmentation
Jan 14, 2025



Enhancing the precision of segmenting coronary atherosclerotic plaques from CT Angiography (CTA) images is pivotal for advanced Coronary Atherosclerosis Analysis (CAA), which distinctively relies on the analysis of vessel cross-section images reconstructed via Curved Planar Reformation. This task presents significant challenges due to the indistinct boundaries and structures of plaques and blood vessels, leading to the inadequate performance of current deep learning models, compounded by the inherent difficulty in annotating such complex data. To address these issues, we propose a novel dual-consistency semi-supervised framework that integrates Intra-frame Topological Consistency (ITC) and Cross-frame Topological Consistency (CTC) to leverage labeled and unlabeled data. ITC employs a dual-task network for simultaneous segmentation mask and Skeleton-aware Distance Transform (SDT) prediction, achieving similar prediction of topology structure through consistency constraint without additional annotations. Meanwhile, CTC utilizes an unsupervised estimator for analyzing pixel flow between skeletons and boundaries of adjacent frames, ensuring spatial continuity. Experiments on two CTA datasets show that our method surpasses existing semi-supervised methods and approaches the performance of supervised methods on CAA. In addition, our method also performs better than other methods on the ACDC dataset, demonstrating its generalization.
HAUR: Human Annotation Understanding and Recognition Through Text-Heavy Images
Dec 24, 2024Vision Question Answering (VQA) tasks use images to convey critical information to answer text-based questions, which is one of the most common forms of question answering in real-world scenarios. Numerous vision-text models exist today and have performed well on certain VQA tasks. However, these models exhibit significant limitations in understanding human annotations on text-heavy images. To address this, we propose the Human Annotation Understanding and Recognition (HAUR) task. As part of this effort, we introduce the Human Annotation Understanding and Recognition-5 (HAUR-5) dataset, which encompasses five common types of human annotations. Additionally, we developed and trained our model, OCR-Mix. Through comprehensive cross-model comparisons, our results demonstrate that OCR-Mix outperforms other models in this task. Our dataset and model will be released soon .
Exploring Dynamic Selection of Branch Expansion Orders for Code Generation
Jun 01, 2021
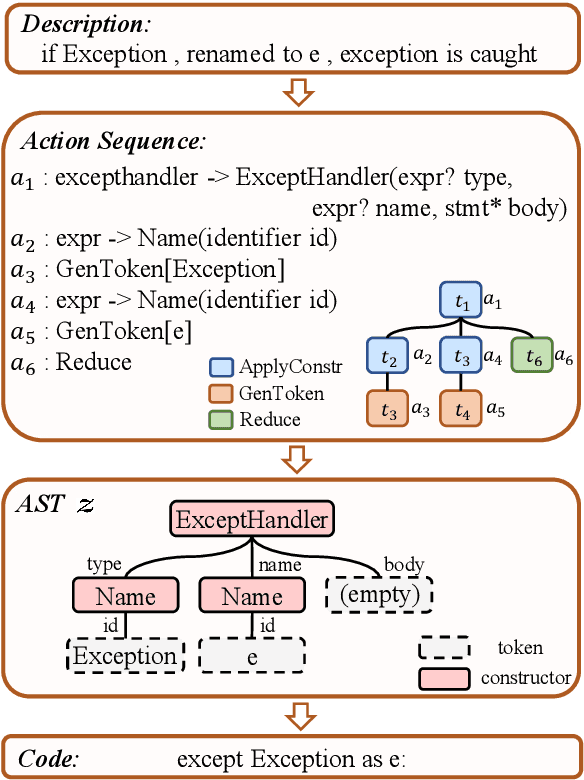
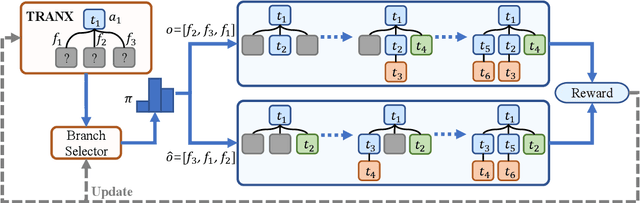
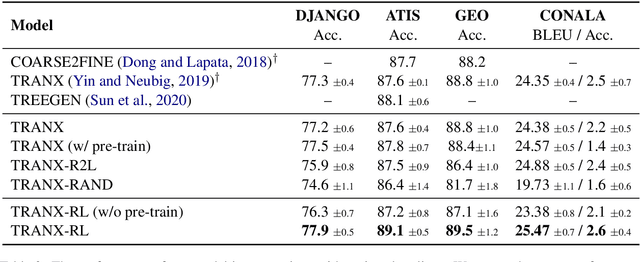
Due to the great potential in facilitating software development, code generation has attracted increasing attention recently. Generally, dominant models are Seq2Tree models, which convert the input natural language description into a sequence of tree-construction actions corresponding to the pre-order traversal of an Abstract Syntax Tree (AST). However, such a traversal order may not be suitable for handling all multi-branch nodes. In this paper, we propose to equip the Seq2Tree model with a context-based Branch Selector, which is able to dynamically determine optimal expansion orders of branches for multi-branch nodes. Particularly, since the selection of expansion orders is a non-differentiable multi-step operation, we optimize the selector through reinforcement learning, and formulate the reward function as the difference of model losses obtained through different expansion orders. Experimental results and in-depth analysis on several commonly-used datasets demonstrate the effectiveness and generality of our approach. We have released our code at https://github.com/DeepLearnXMU/CG-RL.