 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORES: Open-vocabulary Responsible Visual Synthesis
Aug 26, 2023



Avoiding synthesizing specific visual concepts is an essential challenge in responsible visual synthesis. However, the visual concept that needs to be avoided for responsible visual synthesis tends to be diverse, depending on the region, context, and usage scenarios. In this work, we formalize a new task, Open-vocabulary Responsible Visual Synthesis (ORES), where the synthesis model is able to avoid forbidden visual concepts while allowing users to input any desired content. To address this problem, we present a Two-stage Intervention (TIN) framework. By introducing 1) rewriting with learnable instruction through a large-scale language model (LLM) and 2) synthesizing with prompt intervention on a diffusion synthesis model, it can effectively synthesize images avoiding any concepts but following the user's query as much as possible. To evaluate on ORES, we provide a publicly available dataset, baseline models, and benchmark. Experimental results demonstrate the effectiveness of our method in reducing risks of image generation. Our work highlights the potential of LLMs in responsible visual synthesis. Our code and dataset is public available.
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Aug 04, 2023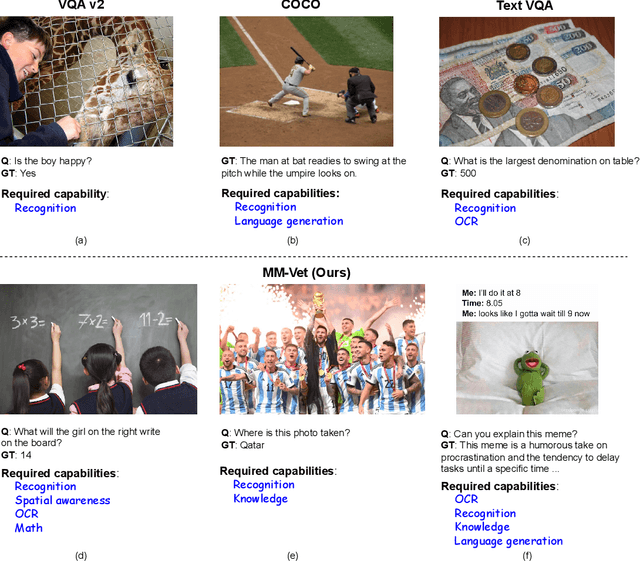

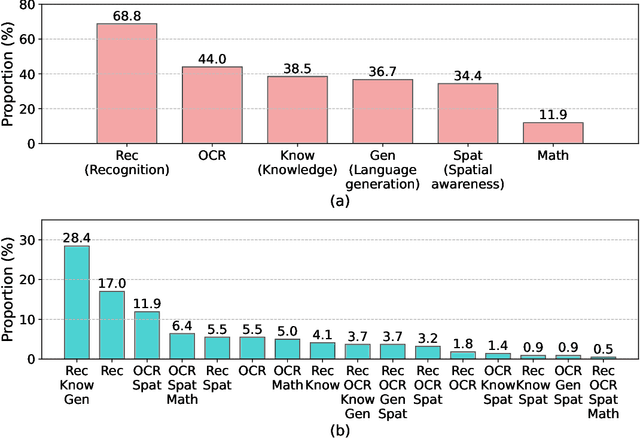
We propose MM-Vet, an evaluation benchmark that examines large multimodal models (LMMs) on complicated multimodal tasks. Recent LMMs have shown various intriguing abilities, such as solving math problems written on the blackboard, reasoning about events and celebrities in news images, and explaining visual jokes. Rapid model advancements pose challenges to evaluation benchmark development. Problems include: (1) How to systematically structure and evaluate the complicated multimodal tasks; (2) How to design evaluation metrics that work well across question and answer types; and (3) How to give model insights beyond a simple performance ranking. To this end, we present MM-Vet, designed based on the insight that the intriguing ability to solve complicated tasks is often achieved by a generalist model being able to integrate different core vision-language (VL) capabilities. MM-Vet defines 6 core VL capabilities and examines the 16 integrations of interest derived from the capability combination. For evaluation metrics, we propose an LLM-based evaluator for open-ended outputs. The evaluator enables the evaluation across different question types and answer styles, resulting in a unified scoring metric. We evaluate representative LMMs on MM-Vet, providing insights into the capabilities of different LMM system paradigms and models. Code and data are available at https://github.com/yuweihao/MM-Vet.
Does Full Waveform Inversion Benefit from Big Data?
Jul 28, 2023This paper investigates the impact of big data on deep learning models for full waveform inversion (FWI). While it is well known that big data can boost the performance of deep learning models in many tasks, its effectiveness has not been validated for FWI. To address this gap, we present an empirical study that investigates how deep learning models in FWI behave when trained on OpenFWI, a collection of large-scale, multi-structural datasets published recently. Particularly, we train and evaluate the FWI models on a combination of 10 2D subsets in OpenFWI that contain 470K data pairs in total. Our experiments demonstrate that larger datasets lead to better performance and generalization of deep learning models for FWI. We further demonstrate that model capacity needs to scale in accordance with data size for optimal improvement.
Spatial-Frequency U-Net for Denoising Diffusion Probabilistic Models
Jul 27, 2023In this paper, we study the denoising diffusion probabilistic model (DDPM) in wavelet space, instead of pixel space, for visual synthesis. Considering the wavelet transform represents the image in spatial and frequency domains, we carefully design a novel architecture SFUNet to effectively capture the correlation for both domains. Specifically, in the standard denoising U-Net for pixel data, we supplement the 2D convolutions and spatial-only attention layers with our spatial frequency-aware convolution and attention modules to jointly model the complementary information from spatial and frequency domains in wavelet data. Our new architecture can be used as a drop-in replacement to the pixel-based network and is compatible with the vanilla DDPM training process. By explicitly modeling the wavelet signals, we find our model is able to generate images with higher quality on CIFAR-10, FFHQ, LSUN-Bedroom, and LSUN-Church datasets, than the pixel-based counterpart.
DisCo: Disentangled Control for Referring Human Dance Generation in Real World
Jun 30, 2023Generative AI has made significant strides in computer vision, particularly in image/video synthesis conditioned on text descriptions. Despite the advancements, it remains challenging especially in the generation of human-centric content such as dance synthesis. Existing dance synthesis methods struggle with the gap between synthesized content and real-world dance scenarios. In this paper, we define a new problem setting: Referring Human Dance Generation, which focuses on real-world dance scenarios with three important properties: (i) Faithfulness: the synthesis should retain the appearance of both human subject foreground and background from the reference image, and precisely follow the target pose; (ii) Generalizability: the model should generalize to unseen human subjects, backgrounds, and poses; (iii) Compositionality: it should allow for composition of seen/unseen subjects, backgrounds, and poses from different sources. To address these challenges, we introduce a novel approach, DISCO, which includes a novel model architecture with disentangled control to improve the faithfulness and compositionality of dance synthesis, and an effective human attribute pre-training for better generalizability to unseen humans. Extensive qualitative and quantitative results demonstrate that DISCO can generate high-quality human dance images and videos with diverse appearances and flexible motions. Code, demo, video and visualization are available at: https://disco-dance.github.io/.
OpenSTL: A Comprehensive Benchmark of Spatio-Temporal Predictive Learning
Jun 20, 2023



Spatio-temporal predictive learning is a learning paradigm that enables models to learn spatial and temporal patterns by predicting future frames from given past frames in an unsupervised manner. Despite remarkable progress in recent years, a lack of systematic understanding persists due to the diverse settings, complex implementation, and difficult reproducibility. Without standardization, comparisons can be unfair and insights inconclusive. To address this dilemma, we propose OpenSTL, a comprehensive benchmark for spatio-temporal predictive learning that categorizes prevalent approaches into recurrent-based and recurrent-free models. OpenSTL provides a modular and extensible framework implementing various state-of-the-art methods. We conduct standard evaluations on datasets across various domains, including synthetic moving object trajectory, human motion, driving scenes, traffic flow and weather forecasting. Based on our observations, we provide a detailed analysis of how model architecture and dataset properties affect spatio-temporal predictive learning performance. Surprisingly, we find that recurrent-free models achieve a good balance between efficiency and performance than recurrent models. Thus, we further extend the common MetaFormers to boost recurrent-free spatial-temporal predictive learning. We open-source the code and models at https://github.com/chengtan9907/OpenSTL.
RefineVIS: Video Instance Segmentation with Temporal Attention Refinement
Jun 07, 2023We introduce a novel framework called RefineVIS for Video Instance Segmentation (VIS) that achieves good object association between frames and accurate segmentation masks by iteratively refining the representations using sequence context. RefineVIS learns two separate representations on top of an off-the-shelf frame-level image instance segmentation model: an association representation responsible for associating objects across frames and a segmentation representation that produces accurate segmentation masks. Contrastive learning is utilized to learn temporally stable association representations. A Temporal Attention Refinement (TAR) module learns discriminative segmentation representations by exploiting temporal relationships and a novel temporal contrastive denoising technique. Our method supports both online and offline inference. It achieves state-of-the-art video instance segmentation accuracy on YouTube-VIS 2019 (64.4 AP), Youtube-VIS 2021 (61.4 AP), and OVIS (46.1 AP) datasets. The visualization shows that the TAR module can generate more accurate instance segmentation masks, particularly for challenging cases such as highly occluded objects.
PaintSeg: Training-free Segmentation via Painting
Jun 04, 2023



The paper introduces PaintSeg, a new unsupervised method for segmenting objects without any training. We propose an adversarial masked contrastive painting (AMCP) process, which creates a contrast between the original image and a painted image in which a masked area is painted using off-the-shelf generative models. During the painting process, inpainting and outpainting are alternated, with the former masking the foreground and filling in the background, and the latter masking the background while recovering the missing part of the foreground object. Inpainting and outpainting, also referred to as I-step and O-step, allow our method to gradually advance the target segmentation mask toward the ground truth without supervision or training. PaintSeg can be configured to work with a variety of prompts, e.g. coarse masks, boxes, scribbles, and points. Our experimental results demonstrate that PaintSeg outperforms existing approaches in coarse mask-prompt, box-prompt, and point-prompt segmentation tasks, providing a training-free solution suitable for unsupervised segmentation.
Image is First-order Norm+Linear Autoregressive
May 25, 2023This paper reveals that every image can be understood as a first-order norm+linear autoregressive process, referred to as FINOLA, where norm+linear denotes the use of normalization before the linear model. We demonstrate that images of size 256$\times$256 can be reconstructed from a compressed vector using autoregression up to a 16$\times$16 feature map, followed by upsampling and convolution. This discovery sheds light on the underlying partial differential equations (PDEs) governing the latent feature space. Additionally, we investigate the application of FINOLA for self-supervised learning through a simple masked prediction technique. By encoding a single unmasked quadrant block, we can autoregressively predict the surrounding masked region. Remarkably, this pre-trained representation proves effective for image classification and object detection tasks, even in lightweight networks, without requiring fine-tuning. The code will be made publicly available.
Conformal Inference for Invariant Risk Minimization
May 22, 2023



The application of machine learning models can be significantly impeded by the occurrence of distributional shifts, as the assumption of homogeneity between the population of training and testing samples in machine learning and statistics may not be feasible in practical situations. One way to tackle this problem is to use invariant learning, such as invariant risk minimization (IRM), to acquire an invariant representation that aids in generalization with distributional shifts. This paper develops methods for obtaining distribution-free prediction regions to describe uncertainty estimates for invariant representations, accounting for the distribution shifts of data from different environments. Our approach involves a weighted conformity score that adapts to the specific environment in which the test sample is situated. We construct an adaptive conformal interval using the weighted conformity score and prove its conditional average under certain conditions. To demonstrate the effectiveness of our approach, we conduct several numerical experiments, including simulation studies and a practical example using real-world data.