 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning State Conditioned Linear Mappings for Low-Dimensional Control of Robotic Manipulators
Oct 28, 2024



Identifying an appropriate task space that simplifies control solutions is important for solving robotic manipulation problems. One approach to this problem is learning an appropriate low-dimensional action space. Linear and nonlinear action mapping methods have trade-offs between simplicity on the one hand and the ability to express motor commands outside of a single low-dimensional subspace on the other. We propose that learning local linear action representations that adapt based on the current configuration of the robot achieves both of these benefits. Our state-conditioned linear maps ensure that for any given state, the high-dimensional robotic actuations are linear in the low-dimensional action. As the robot state evolves, so do the action mappings, ensuring the ability to represent motions that are immediately necessary. These local linear representations guarantee desirable theoretical properties by design, and we validate these findings empirically through two user studies. Results suggest state-conditioned linear maps outperform conditional autoencoder and PCA baselines on a pick-and-place task and perform comparably to mode switching in a more complex pouring task.
* 7 Pages, 8 Figures, Presented at the 2023 IEEE International Conference on Robotics and Automation (ICRA)
Managing Temporal Resolution in Continuous Value Estimation: A Fundamental Trade-off
Dec 17, 2022



A default assumption in reinforcement learning and optimal control is that experience arrives at discrete time points on a fixed clock cycle. Many applications, however, involve continuous systems where the time discretization is not fixed but instead can be managed by a learning algorithm. By analyzing Monte-Carlo value estimation for LQR systems in both finite-horizon and infinite-horizon settings, we uncover a fundamental trade-off between approximation and statistical error in value estimation. Importantly, these two errors behave differently with respect to time discretization, which implies that there is an optimal choice for the temporal resolution that depends on the data budget. These findings show how adapting the temporal resolution can provably improve value estimation quality in LQR systems from finite data. Empirically, we demonstrate the trade-off in numerical simulations of LQR instances and several non-linear environments.
Analyzing Neural Jacobian Methods in Applications of Visual Servoing and Kinematic Control
Jun 10, 2021
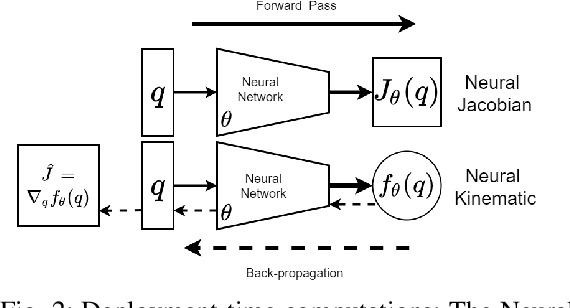
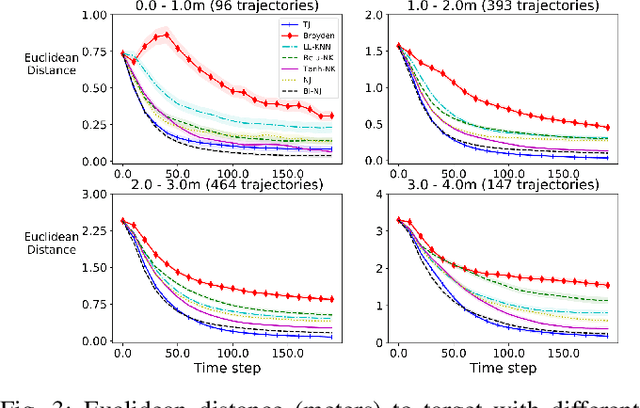
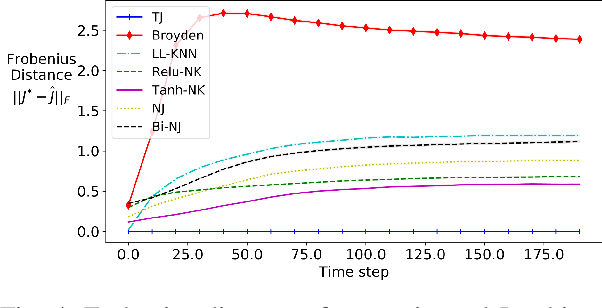
Designing adaptable control laws that can transfer between different robots is a challenge because of kinematic and dynamic differences, as well as in scenarios where external sensors are used. In this work, we empirically investigate a neural networks ability to approximate the Jacobian matrix for an application in Cartesian control schemes. Specifically, we are interested in approximating the kinematic Jacobian, which arises from kinematic equations mapping a manipulator's joint angles to the end-effector's location. We propose two different approaches to learn the kinematic Jacobian. The first method arises from visual servoing where we learn the kinematic Jacobian as an approximate linear system of equations from the k-nearest neighbors for a desired joint configuration. The second, motivated by forward models in machine learning, learns the kinematic behavior directly and calculates the Jacobian by differentiating the learned neural kinematics model. Simulation experimental results show that both methods achieve better performance than alternative data-driven methods for control, provide closer approximations to the proper kinematics Jacobian matrix, and on average produce better-conditioned Jacobian matrices. Real-world experiments were conducted on a Kinova Gen-3 lightweight robotic manipulator, which includes an uncalibrated visual servoing experiment, a practical application of our methods, as well as a 7-DOF point-to-point task highlighting that our methods are applicable on real robotic manipulators.
A Quantitative Analysis of Activities of Daily Living: Insights into Improving Functional Independence with Assistive Robotics
Apr 08, 2021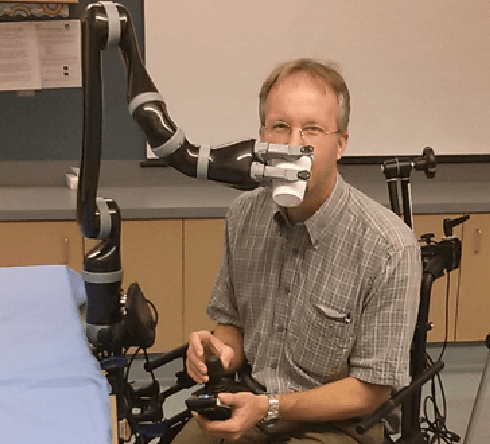
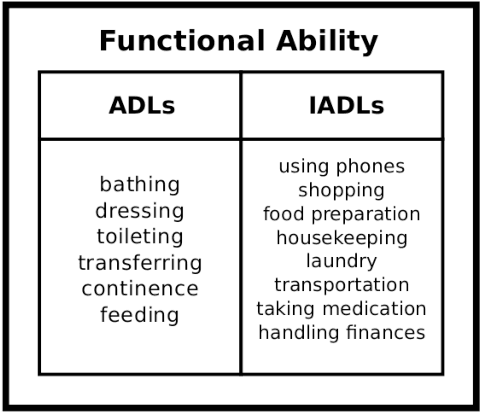
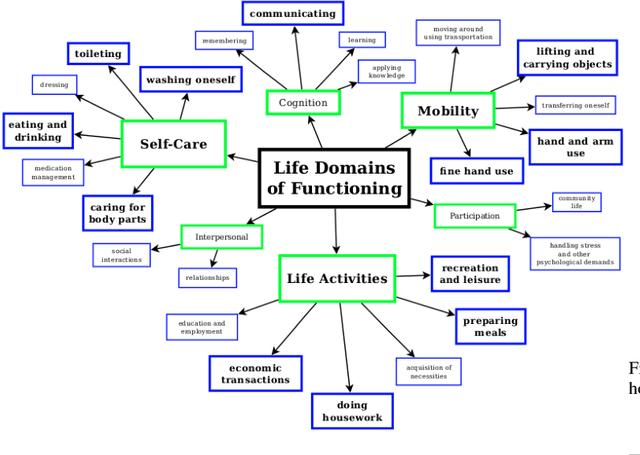
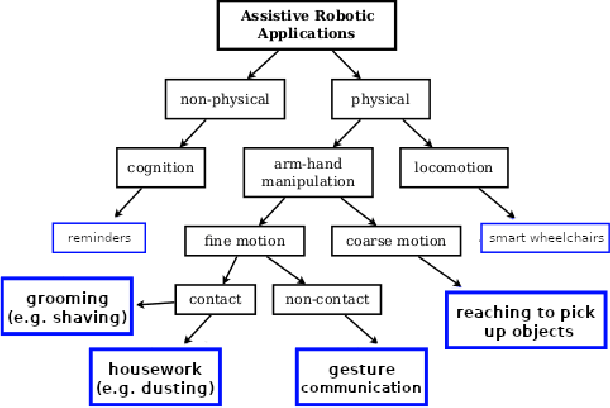
Human assistive robotics have the potential to help the elderly and individuals living with disabilities with their Activities of Daily Living (ADL). Robotics researchers focus on assistive tasks from the perspective of various control schemes and motion types. Health research on the other hand focuses on clinical assessment and rehabilitation, arguably leaving important differences between the two domains. In particular, little is known quantitatively on which ADLs are typically carried out in a persons everyday environment - at home, work, etc. Understanding what activities are frequently carried out during the day can help guide the development and prioritization of robotic technology for in-home assistive robotic deployment. This study targets several lifelogging databases, where we compute (i) ADL task frequency from long-term low sampling frequency video and Internet of Things (IoT) sensor data, and (ii) short term arm and hand movement data from 30 fps video data of domestic tasks. Robotics and health care communities have differing terms and taxonomies for representing tasks and motions. In this work, we derive and discuss a robotics-relevant taxonomy from quantitative ADL task and motion data in attempt to ameliorate taxonomic differences between the two communities. Our quantitative results provide direction for the development of better assistive robots to support the true demands of the healthcare community.
Assistive arm and hand manipulation: How does current research intersect with actual healthcare needs?
Jan 07, 2021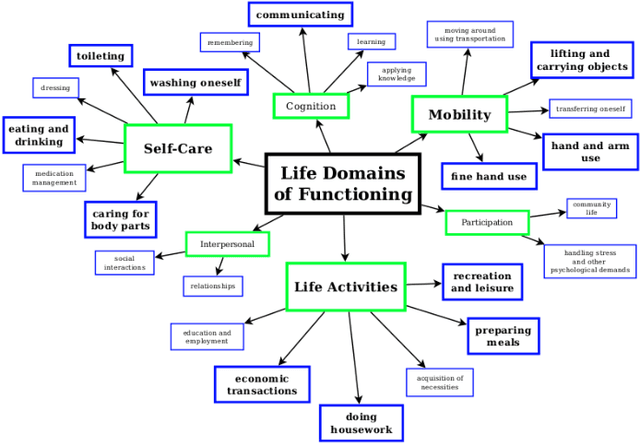
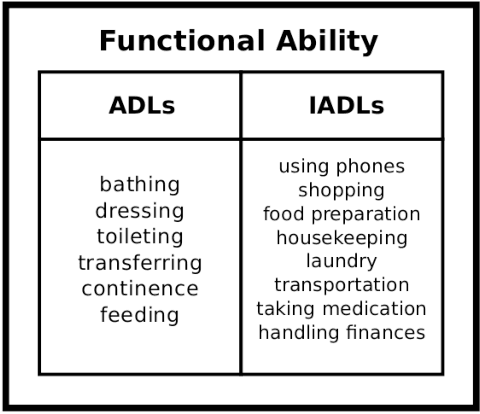
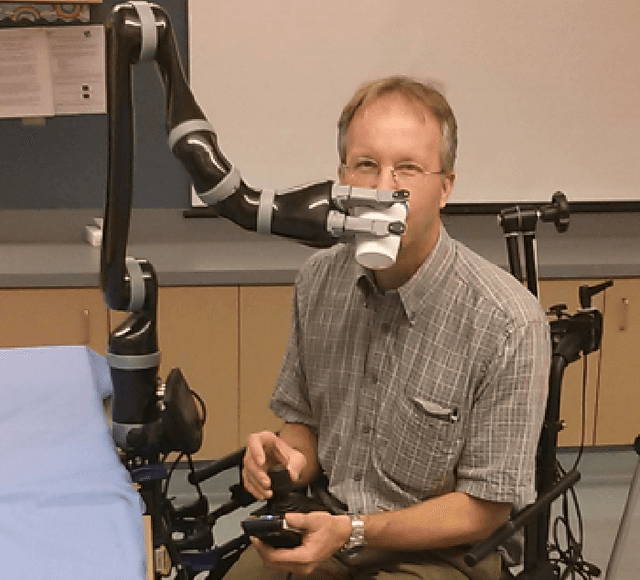
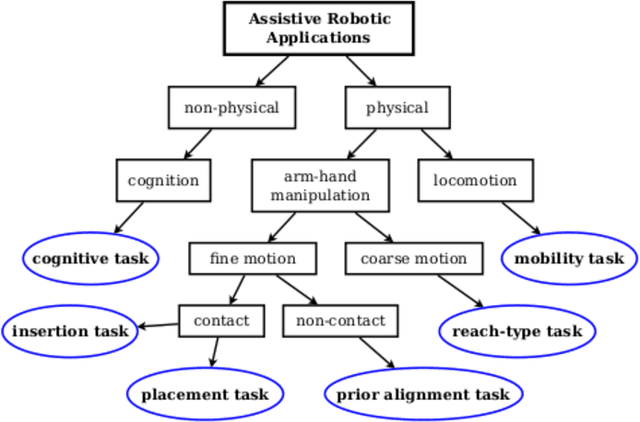
Human assistive robotics have the potential to help the elderly and individuals living with disabilities with their Activities of Daily Living (ADL). Robotics researchers present bottom up solutions using various control methods for different types of movements. Health research on the other hand focuses on clinical assessment and rehabilitation leaving arguably important differences between the two domains. In particular, little is known quantitatively on what ADLs humans perform in their everyday environment - at home, work etc. This information can help guide development and prioritization of robotic technology for in-home assistive robotic deployment. This study targets several lifelogging databases, where we compute (i) ADL task frequency from long-term low sampling frequency video and Internet of Things (IoT) sensor data, and (ii) short term arm and hand movement data from 30 fps video data of domestic tasks. Robotics and health care communities have different terms and taxonomies for representing tasks and motions. We derive and discuss a robotics-relevant taxonomy from this quantitative ADL task and ICF motion data in attempt to ameliorate these taxonomic differences. Our statistics quantify that humans reach, open drawers, doors, and retrieve and use objects hundreds of times a day. Commercial wheelchair mounted robot arms can help 150,000 upper body disabled in the USA alone, but only a few hundred robots are deployed. Better user interfaces, and more capable robots can increase the potential user base and number of ADL tasks solved significantly.
U$^2$-Net: Going Deeper with Nested U-Structure for Salient Object Detection
May 18, 2020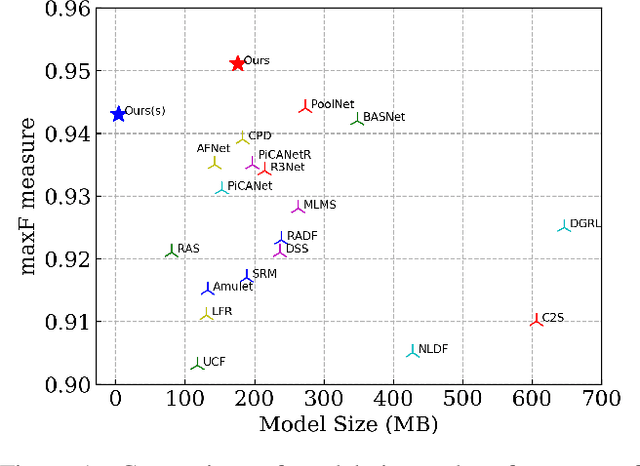
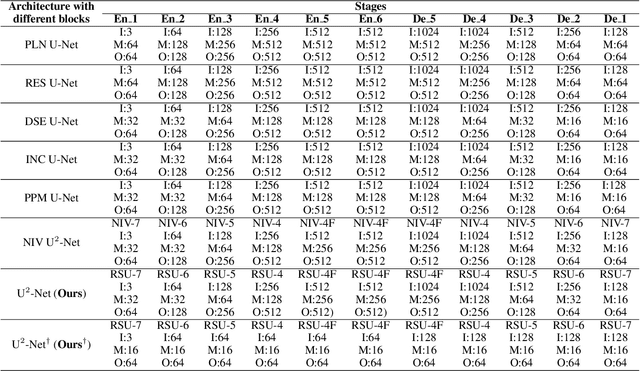
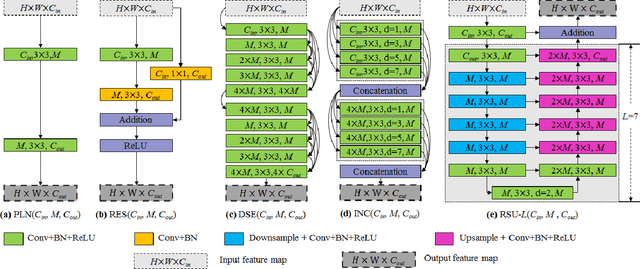
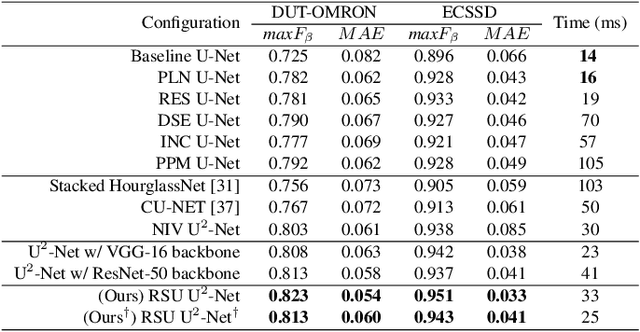
In this paper, we design a simple yet powerful deep network architecture, U$^2$-Net, for salient object detection (SOD). The architecture of our U$^2$-Net is a two-level nested U-structure. The design has the following advantages: (1) it is able to capture more contextual information from different scales thanks to the mixture of receptive fields of different sizes in our proposed ReSidual U-blocks (RSU), (2) it increases the depth of the whole architecture without significantly increasing the computational cost because of the pooling operations used in these RSU blocks. This architecture enables us to train a deep network from scratch without using backbones from image classification tasks. We instantiate two models of the proposed architecture, U$^2$-Net (176.3 MB, 30 FPS on GTX 1080Ti GPU) and U$^2$-Net$^{\dagger}$ (4.7 MB, 40 FPS), to facilitate the usage in different environments. Both models achieve competitive performance on six SOD datasets. The code is available: https://github.com/NathanUA/U-2-Net.
A Geometric Perspective on Visual Imitation Learning
Mar 05, 2020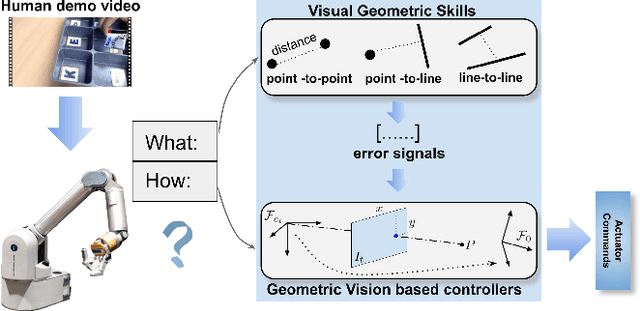
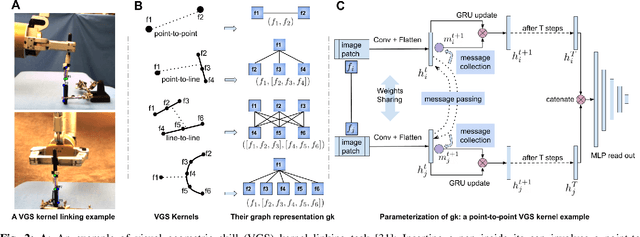
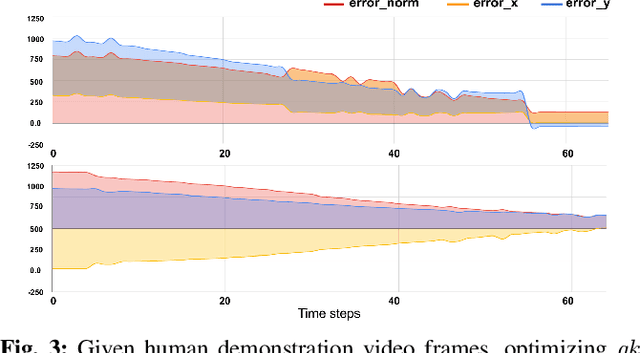
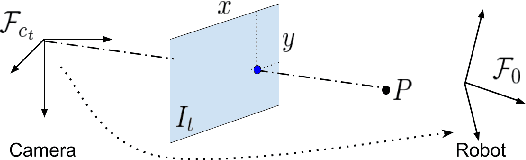
We consider the problem of visual imitation learning without human supervision (e.g. kinesthetic teaching or teleoperation), nor access to an interactive reinforcement learning (RL) training environment. We present a geometric perspective to derive solutions to this problem. Specifically, we propose VGS-IL (Visual Geometric Skill Imitation Learning), an end-to-end geometry-parameterized task concept inference method, to infer globally consistent geometric feature association rules from human demonstration video frames. We show that, instead of learning actions from image pixels, learning a geometry-parameterized task concept provides an explainable and invariant representation across demonstrator to imitator under various environmental settings. Moreover, such a task concept representation provides a direct link with geometric vision based controllers (e.g. visual servoing), allowing for efficient mapping of high-level task concepts to low-level robot actions.
Understanding Contexts Inside Robot and Human Manipulation Tasks through a Vision-Language Model and Ontology System in a Video Stream
Mar 02, 2020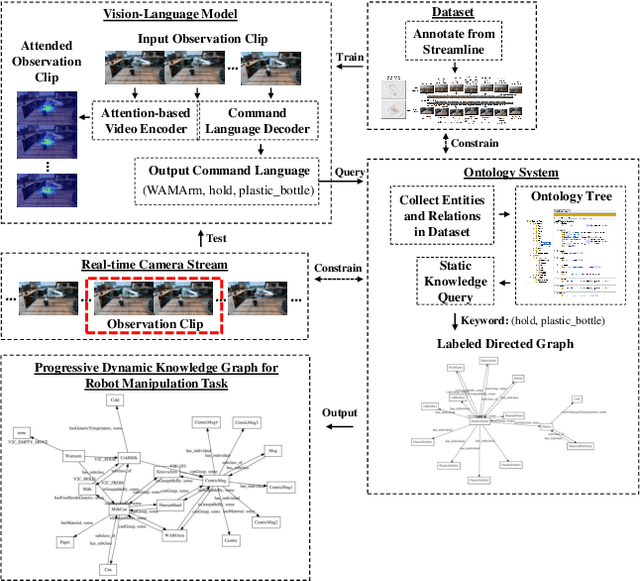
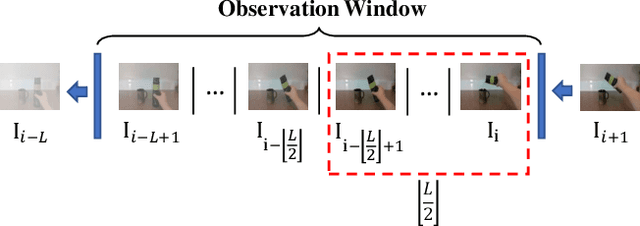
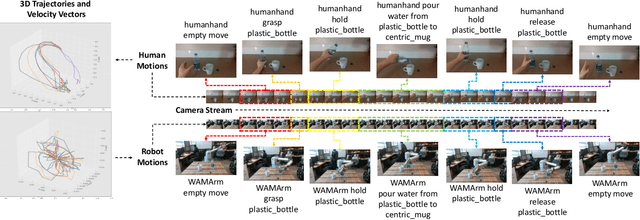
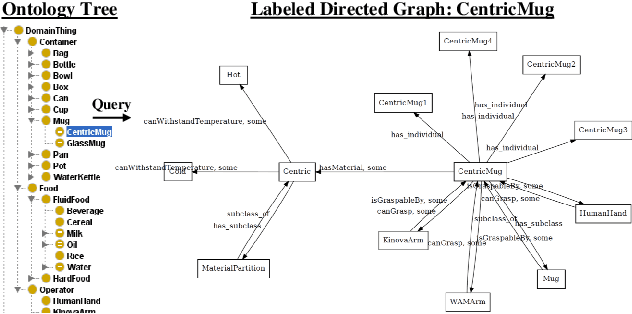
Manipulation tasks in daily life, such as pouring water, unfold intentionally under specialized manipulation contexts. Being able to process contextual knowledge in these Activities of Daily Living (ADLs) over time can help us understand manipulation intentions, which are essential for an intelligent robot to transition smoothly between various manipulation actions. In this paper, to model the intended concepts of manipulation, we present a vision dataset under a strictly constrained knowledge domain for both robot and human manipulations, where manipulation concepts and relations are stored by an ontology system in a taxonomic manner. Furthermore, we propose a scheme to generate a combination of visual attentions and an evolving knowledge graph filled with commonsense knowledge. Our scheme works with real-world camera streams and fuses an attention-based Vision-Language model with the ontology system. The experimental results demonstrate that the proposed scheme can successfully represent the evolution of an intended object manipulation procedure for both robots and humans. The proposed scheme allows the robot to mimic human-like intentional behaviors by watching real-time videos. We aim to develop this scheme further for real-world robot intelligence in Human-Robot Interaction.
Visual Geometric Skill Inference by Watching Human Demonstration
Nov 08, 2019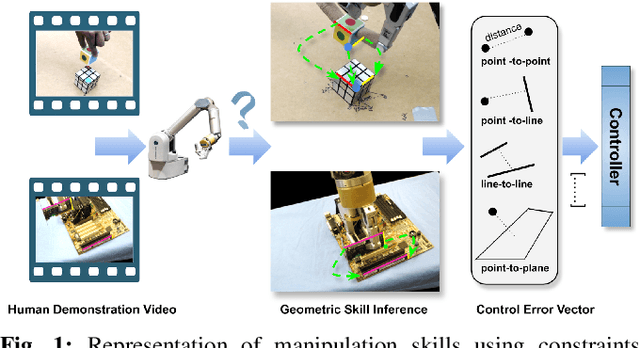
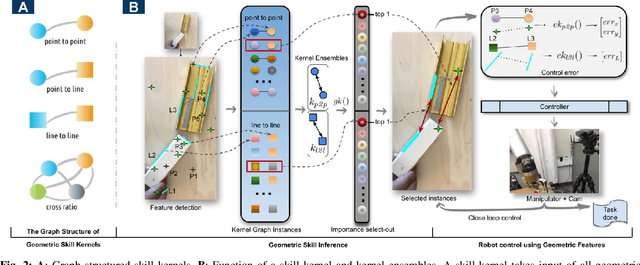
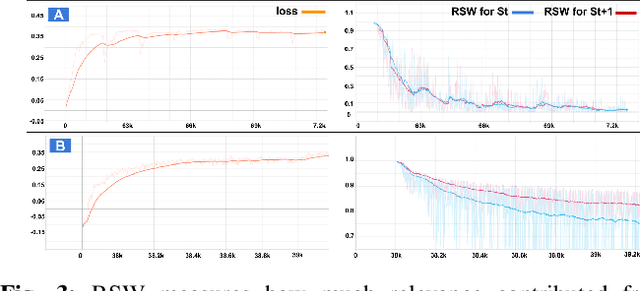

We study the problem of learning manipulation skills from human demonstration video by inferring association relationship between geometric features. Our motivation comes from the observation in human eye-hand coordination that a set of manipulation skills are actually minimizing the Euclidean distance between geometric primitives while regressing their association constraints in non-Euclidean space. We propose a graph based kernel regression method to directly infer the underlying association constraints from human demonstration video using Incremental Maximum Entropy Inverse Reinforcement Learning (InMaxEnt IRL). The learned skill inference provides human readable task definition and outputs control errors that can be directly plugged into traditional controllers. Our method removes the need of tedious feature selection and robust feature trackers in traditional approaches (e.g. feature based visual servoing). Experiments show our method reaches high accuracy even with only one human demonstration video and generalize well under variances.
Long range teleoperation for fine manipulation tasks under time-delay network conditions
Mar 21, 2019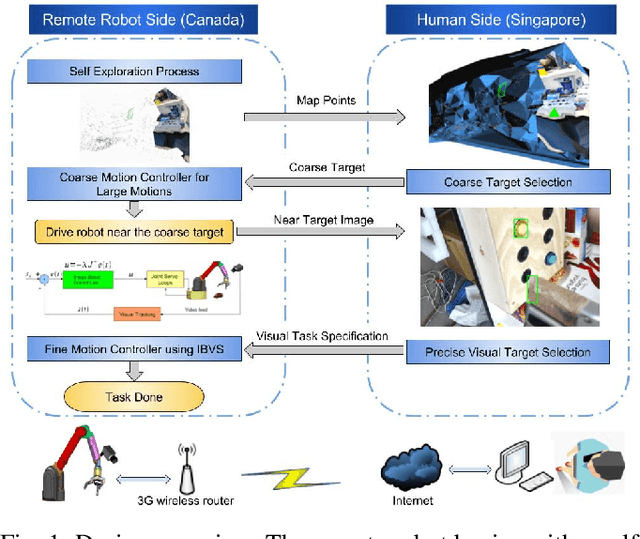
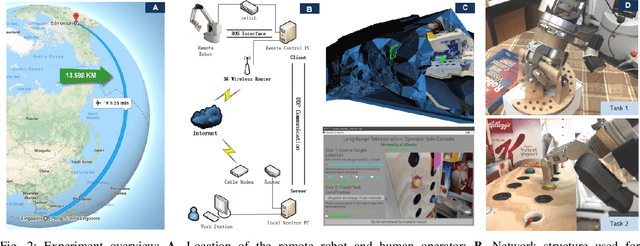
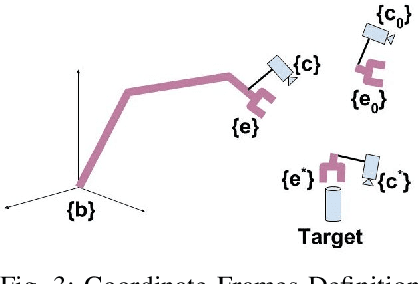
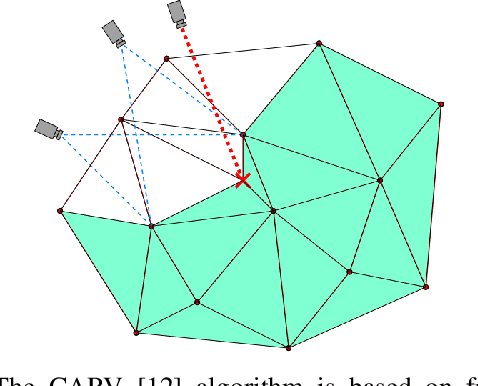
We present a coarse-to-fine approach based semi-autonomous teleoperation system using vision guidance. The system is optimized for long range teleoperation tasks under time-delay network conditions and does not require prior knowledge of the remote scene. Our system initializes with a self exploration behavior that senses the remote surroundings through a freely mounted eye-in-hand web cam. The self exploration stage estimates hand-eye calibration and provides a telepresence interface via real-time 3D geometric reconstruction. The human operator is able to specify a visual task through the interface and a coarse-to-fine controller guides the remote robot enabling our system to work in high latency networks. Large motions are guided by coarse 3D estimation, whereas fine motions use image cues (IBVS). Network data transmission cost is minimized by sending only sparse points and a final image to the human side. Experiments from Singapore to Canada on multiple tasks were conducted to show our system's capability to work in long range teleoperation tasks.