 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInductive Generalization for Robotic Manipulation
Jun 19, 2026Understanding the generalization capabilities of visuomotor policies is essential in the development of capable robotic agents. Generalizable models learn structures that transfer across domains. However, in practice, visuomotor policies test performance by interpolation on known distributions using unstructured domain shifts (e.g. lighting, clutter, diverse objects). We argue that to measure generalization capabilities we must instead test the inductive capacity of policies on progressively harder, out-of-distribution task variants. We call this inductive generalization, drawing directly on how axis-based evaluation has revealed inherent generalization limitations in language models (e.g. sequence length, counting) arXiv:2502.00197 . We provide a reusable and formal evaluation protocol for measuring inductive generalization in any manipulation policy, and establish baselines showing that existing paradigms fail this test; e.g. SoTA Vision-Language-Action models and find that policies that appear to generalize to prior domain shifts (distractors, etc) fail inductive generalization tests. These results expose a class of learning challenges orthogonal to those addressed by data and model scaling in robot learning, yet are imperative to solve in order to realize general purpose robots.
Formalizing the Binding Problem
Jun 02, 2026Representations of the world, arguably, contain information about features (e.g. something is blue, something is a circle) but also information about which features are part of the same object (e.g. the circle is blue), which we call binding information. Any system with the ability to understand scenes with multiple objects must be able to solve the binding problem: it needs to know which features belong together. However, despite work showing that Vision Transformers (ViTs) know which patches belong together, it is not known whether current deep learning models learn to exhibit binding information, i.e., for features. We may believe that there is not much binding information, after all misattributing features to wrong objects is a common failure of ViT-based architectures, especially in scenes with objects sharing features. Here we formalize the binding problem with an information-theoretic approach, and introduce a probing method to measure binding information in model representations. We perform experiments on ViTs, measuring binding from different components of the architecture, such as the image summary token [CLS] or the spatial tokens. We use datasets with different binding challenges, such as feature sharing, occlusion, and natural features, while comparing the performance of several pre-trained ViTs. Overall, our research demonstrates binding as a key ingredient to strong visual recognition and reasoning.
Tools Fail: Detecting Silent Errors in Faulty Tools
Jun 27, 2024



Tools have become a mainstay of LLMs, allowing them to retrieve knowledge not in their weights, to perform tasks on the web, and even to control robots. However, most ontologies and surveys of tool-use have assumed the core challenge for LLMs is choosing the tool. Instead, we introduce a framework for tools more broadly which guides us to explore a model's ability to detect "silent" tool errors, and reflect on how to plan. This more directly aligns with the increasingly popular use of models as tools. We provide an initial approach to failure recovery with promising results both on a controlled calculator setting and embodied agent planning.
DiffusionPID: Interpreting Diffusion via Partial Information Decomposition
Jun 07, 2024



Text-to-image diffusion models have made significant progress in generating naturalistic images from textual inputs, and demonstrate the capacity to learn and represent complex visual-semantic relationships. While these diffusion models have achieved remarkable success, the underlying mechanisms driving their performance are not yet fully accounted for, with many unanswered questions surrounding what they learn, how they represent visual-semantic relationships, and why they sometimes fail to generalize. Our work presents Diffusion Partial Information Decomposition (DiffusionPID), a novel technique that applies information-theoretic principles to decompose the input text prompt into its elementary components, enabling a detailed examination of how individual tokens and their interactions shape the generated image. We introduce a formal approach to analyze the uniqueness, redundancy, and synergy terms by applying PID to the denoising model at both the image and pixel level. This approach enables us to characterize how individual tokens and their interactions affect the model output. We first present a fine-grained analysis of characteristics utilized by the model to uniquely localize specific concepts, we then apply our approach in bias analysis and show it can recover gender and ethnicity biases. Finally, we use our method to visually characterize word ambiguity and similarity from the model's perspective and illustrate the efficacy of our method for prompt intervention. Our results show that PID is a potent tool for evaluating and diagnosing text-to-image diffusion models.
Language Models Need Inductive Biases to Count Inductively
May 30, 2024



Counting is a fundamental example of generalization, whether viewed through the mathematical lens of Peano's axioms defining the natural numbers or the cognitive science literature for children learning to count. The argument holds for both cases that learning to count means learning to count infinitely. While few papers have tried to distill transformer "reasoning" to the simplest case of counting, investigating length generalization does occur throughout the literature. In the "train short, test long" paradigm of NLP, length refers to the training sentence length. In formal language recognition, length refers to the input sequence length, or the maximum stack size induced by a pushdown automata. In general problem solving, length refers to the number of hops in a deductive reasoning chain or the recursion depth. For all cases, counting is central to task success. And crucially, generalizing counting inductively is central to success on OOD instances. This work provides extensive empirical results on training language models to count. We experiment with architectures ranging from RNNs, Transformers, State-Space Models and RWKV. We present carefully-designed task formats, auxiliary tasks and positional embeddings to avoid limitations in generalization with OOD-position and OOD-vocabulary. We find that while traditional RNNs trivially achieve inductive counting, Transformers have to rely on positional embeddings to count out-of-domain. As counting is the basis for many arguments concerning the expressivity of Transformers, our finding calls for the community to reexamine the application scope of primitive functions defined in formal characterizations. Finally, modern RNNs also largely underperform traditional RNNs in generalizing counting inductively. We discuss how design choices that enable parallelized training of modern RNNs cause them to lose merits of a recurrent nature.
Flow Priors for Linear Inverse Problems via Iterative Corrupted Trajectory Matching
May 29, 2024



Generative models based on flow matching have attracted significant attention for their simplicity and superior performance in high-resolution image synthesis. By leveraging the instantaneous change-of-variables formula, one can directly compute image likelihoods from a learned flow, making them enticing candidates as priors for downstream tasks such as inverse problems. In particular, a natural approach would be to incorporate such image probabilities in a maximum-a-posteriori (MAP) estimation problem. A major obstacle, however, lies in the slow computation of the log-likelihood, as it requires backpropagating through an ODE solver, which can be prohibitively slow for high-dimensional problems. In this work, we propose an iterative algorithm to approximate the MAP estimator efficiently to solve a variety of linear inverse problems. Our algorithm is mathematically justified by the observation that the MAP objective can be approximated by a sum of $N$ ``local MAP'' objectives, where $N$ is the number of function evaluations. By leveraging Tweedie's formula, we show that we can perform gradient steps to sequentially optimize these objectives. We validate our approach for various linear inverse problems, such as super-resolution, deblurring, inpainting, and compressed sensing, and demonstrate that we can outperform other methods based on flow matching.
Skews in the Phenomenon Space Hinder Generalization in Text-to-Image Generation
Mar 25, 2024



The literature on text-to-image generation is plagued by issues of faithfully composing entities with relations. But there lacks a formal understanding of how entity-relation compositions can be effectively learned. Moreover, the underlying phenomenon space that meaningfully reflects the problem structure is not well-defined, leading to an arms race for larger quantities of data in the hope that generalization emerges out of large-scale pretraining. We hypothesize that the underlying phenomenological coverage has not been proportionally scaled up, leading to a skew of the presented phenomenon which harms generalization. We introduce statistical metrics that quantify both the linguistic and visual skew of a dataset for relational learning, and show that generalization failures of text-to-image generation are a direct result of incomplete or unbalanced phenomenological coverage. We first perform experiments in a synthetic domain and demonstrate that systematically controlled metrics are strongly predictive of generalization performance. Then we move to natural images and show that simple distribution perturbations in light of our theories boost generalization without enlarging the absolute data size. This work informs an important direction towards quality-enhancing the data diversity or balance orthogonal to scaling up the absolute size. Our discussions point out important open questions on 1) Evaluation of generated entity-relation compositions, and 2) Better models for reasoning with abstract relations.
Toxicity Detection with Generative Prompt-based Inference
May 24, 2022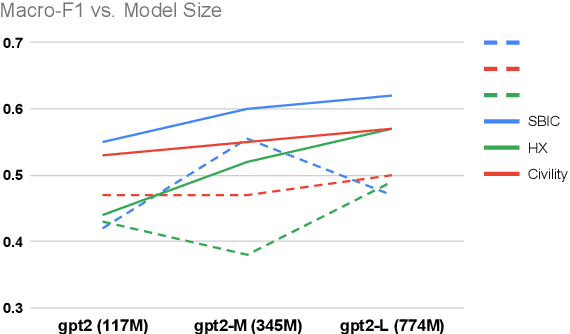

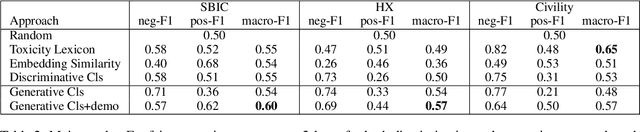
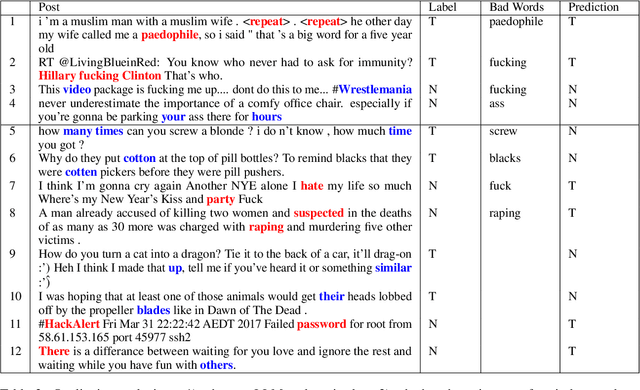
Due to the subtleness, implicity, and different possible interpretations perceived by different people, detecting undesirable content from text is a nuanced difficulty. It is a long-known risk that language models (LMs), once trained on corpus containing undesirable content, have the power to manifest biases and toxicity. However, recent studies imply that, as a remedy, LMs are also capable of identifying toxic content without additional fine-tuning. Prompt-methods have been shown to effectively harvest this surprising self-diagnosing capability. However, existing prompt-based methods usually specify an instruction to a language model in a discriminative way. In this work, we explore the generative variant of zero-shot prompt-based toxicity detection with comprehensive trials on prompt engineering. We evaluate on three datasets with toxicity labels annotated on social media posts. Our analysis highlights the strengths of our generative classification approach both quantitatively and qualitatively. Interesting aspects of self-diagnosis and its ethical implications are discussed.
WebQA: Multihop and Multimodal QA
Sep 21, 2021
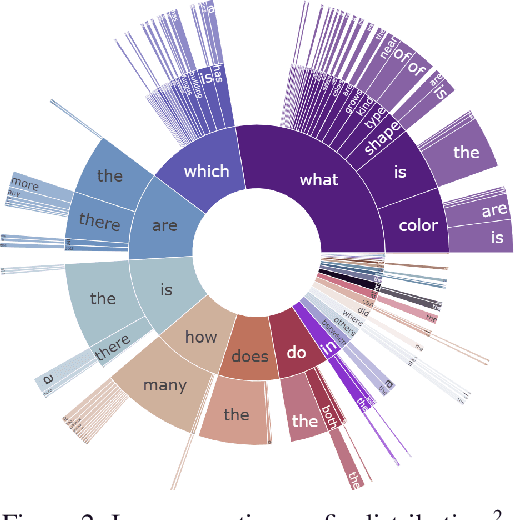


Web search is fundamentally multimodal and multihop. Often, even before asking a question we choose to go directly to image search to find our answers. Further, rarely do we find an answer from a single source but aggregate information and reason through implications. Despite the frequency of this everyday occurrence, at present, there is no unified question answering benchmark that requires a single model to answer long-form natural language questions from text and open-ended visual sources -- akin to a human's experience. We propose to bridge this gap between the natural language and computer vision communities with WebQA. We show that A. our multihop text queries are difficult for a large-scale transformer model, and B. existing multi-modal transformers and visual representations do not perform well on open-domain visual queries. Our challenge for the community is to create a unified multimodal reasoning model that seamlessly transitions and reasons regardless of the source modality.