 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDressWild: Feed-Forward Pose-Agnostic Garment Sewing Pattern Generation from In-the-Wild Images
Feb 18, 2026Recent advances in garment pattern generation have shown promising progress. However, existing feed-forward methods struggle with diverse poses and viewpoints, while optimization-based approaches are computationally expensive and difficult to scale. This paper focuses on sewing pattern generation for garment modeling and fabrication applications that demand editable, separable, and simulation-ready garments. We propose DressWild, a novel feed-forward pipeline that reconstructs physics-consistent 2D sewing patterns and the corresponding 3D garments from a single in-the-wild image. Given an input image, our method leverages vision-language models (VLMs) to normalize pose variations at the image level, then extract pose-aware, 3D-informed garment features. These features are fused through a transformer-based encoder and subsequently used to predict sewing pattern parameters, which can be directly applied to physical simulation, texture synthesis, and multi-layer virtual try-on. Extensive experiments demonstrate that our approach robustly recovers diverse sewing patterns and the corresponding 3D garments from in-the-wild images without requiring multi-view inputs or iterative optimization, offering an efficient and scalable solution for realistic garment simulation and animation.
Relational Knowledge Distillation Using Fine-tuned Function Vectors
Jan 13, 2026Representing relations between concepts is a core prerequisite for intelligent systems to make sense of the world. Recent work using causal mediation analysis has shown that a small set of attention heads encodes task representation in in-context learning, captured in a compact representation known as the function vector. We show that fine-tuning function vectors with only a small set of examples (about 20 word pairs) yields better performance on relation-based word-completion tasks than using the original vectors derived from causal mediation analysis. These improvements hold for both small and large language models. Moreover, the fine-tuned function vectors yield improved decoding performance for relation words and show stronger alignment with human similarity judgments of semantic relations. Next, we introduce the composite function vector - a weighted combination of fine-tuned function vectors - to extract relational knowledge and support analogical reasoning. At inference time, inserting this composite vector into LLM activations markedly enhances performance on challenging analogy problems drawn from cognitive science and SAT benchmarks. Our results highlight the potential of activation patching as a controllable mechanism for encoding and manipulating relational knowledge, advancing both the interpretability and reasoning capabilities of large language models.
SlowFast-VGen: Slow-Fast Learning for Action-Driven Long Video Generation
Oct 30, 2024



Human beings are endowed with a complementary learning system, which bridges the slow learning of general world dynamics with fast storage of episodic memory from a new experience. Previous video generation models, however, primarily focus on slow learning by pre-training on vast amounts of data, overlooking the fast learning phase crucial for episodic memory storage. This oversight leads to inconsistencies across temporally distant frames when generating longer videos, as these frames fall beyond the model's context window. To this end, we introduce SlowFast-VGen, a novel dual-speed learning system for action-driven long video generation. Our approach incorporates a masked conditional video diffusion model for the slow learning of world dynamics, alongside an inference-time fast learning strategy based on a temporal LoRA module. Specifically, the fast learning process updates its temporal LoRA parameters based on local inputs and outputs, thereby efficiently storing episodic memory in its parameters. We further propose a slow-fast learning loop algorithm that seamlessly integrates the inner fast learning loop into the outer slow learning loop, enabling the recall of prior multi-episode experiences for context-aware skill learning. To facilitate the slow learning of an approximate world model, we collect a large-scale dataset of 200k videos with language action annotations, covering a wide range of scenarios. Extensive experiments show that SlowFast-VGen outperforms baselines across various metrics for action-driven video generation, achieving an FVD score of 514 compared to 782, and maintaining consistency in longer videos, with an average of 0.37 scene cuts versus 0.89. The slow-fast learning loop algorithm significantly enhances performances on long-horizon planning tasks as well. Project Website: https://slowfast-vgen.github.io
Skews in the Phenomenon Space Hinder Generalization in Text-to-Image Generation
Mar 25, 2024



The literature on text-to-image generation is plagued by issues of faithfully composing entities with relations. But there lacks a formal understanding of how entity-relation compositions can be effectively learned. Moreover, the underlying phenomenon space that meaningfully reflects the problem structure is not well-defined, leading to an arms race for larger quantities of data in the hope that generalization emerges out of large-scale pretraining. We hypothesize that the underlying phenomenological coverage has not been proportionally scaled up, leading to a skew of the presented phenomenon which harms generalization. We introduce statistical metrics that quantify both the linguistic and visual skew of a dataset for relational learning, and show that generalization failures of text-to-image generation are a direct result of incomplete or unbalanced phenomenological coverage. We first perform experiments in a synthetic domain and demonstrate that systematically controlled metrics are strongly predictive of generalization performance. Then we move to natural images and show that simple distribution perturbations in light of our theories boost generalization without enlarging the absolute data size. This work informs an important direction towards quality-enhancing the data diversity or balance orthogonal to scaling up the absolute size. Our discussions point out important open questions on 1) Evaluation of generated entity-relation compositions, and 2) Better models for reasoning with abstract relations.
Aligner: One Global Token is Worth Millions of Parameters When Aligning Large Language Models
Dec 09, 2023We introduce Aligner, a novel Parameter-Efficient Fine-Tuning (PEFT) method for aligning multi-billion-parameter-sized Large Language Models (LLMs). Aligner employs a unique design that constructs a globally shared set of tunable tokens that modify the attention of every layer. Remarkably with this method, even when using one token accounting for a mere 5,000 parameters, Aligner can still perform comparably well to state-of-the-art LLM adaptation methods like LoRA that require millions of parameters. This capacity is substantiated in both instruction following and value alignment tasks. Besides the multiple order-of-magnitude improvement in parameter efficiency, the insight Aligner provides into the internal mechanisms of LLMs is also valuable. The architectural features and efficacy of our method, in addition to our experiments demonstrate that an LLM separates its internal handling of "form" and "knowledge" in a somewhat orthogonal manner. This finding promises to motivate new research into LLM mechanism understanding and value alignment.
Learning Energy-Based Models by Cooperative Diffusion Recovery Likelihood
Sep 12, 2023Training energy-based models (EBMs) with maximum likelihood estimation on high-dimensional data can be both challenging and time-consuming. As a result, there a noticeable gap in sample quality between EBMs and other generative frameworks like GANs and diffusion models. To close this gap, inspired by the recent efforts of learning EBMs by maximimizing diffusion recovery likelihood (DRL), we propose cooperative diffusion recovery likelihood (CDRL), an effective approach to tractably learn and sample from a series of EBMs defined on increasingly noisy versons of a dataset, paired with an initializer model for each EBM. At each noise level, the initializer model learns to amortize the sampling process of the EBM, and the two models are jointly estimated within a cooperative training framework. Samples from the initializer serve as starting points that are refined by a few sampling steps from the EBM. With the refined samples, the EBM is optimized by maximizing recovery likelihood, while the initializer is optimized by learning from the difference between the refined samples and the initial samples. We develop a new noise schedule and a variance reduction technique to further improve the sample quality. Combining these advances, we significantly boost the FID scores compared to existing EBM methods on CIFAR-10 and ImageNet 32x32, with a 2x speedup over DRL. In addition, we extend our method to compositional generation and image inpainting tasks, and showcase the compatibility of CDRL with classifier-free guidance for conditional generation, achieving similar trade-offs between sample quality and sample diversity as in diffusion models.
Progressive Energy-Based Cooperative Learning for Multi-Domain Image-to-Image Translation
Jun 26, 2023This paper studies a novel energy-based cooperative learning framework for multi-domain image-to-image translation. The framework consists of four components: descriptor, translator, style encoder, and style generator. The descriptor is a multi-head energy-based model that represents a multi-domain image distribution. The components of translator, style encoder, and style generator constitute a diversified image generator. Specifically, given an input image from a source domain, the translator turns it into a stylised output image of the target domain according to a style code, which can be inferred by the style encoder from a reference image or produced by the style generator from a random noise. Since the style generator is represented as an domain-specific distribution of style codes, the translator can provide a one-to-many transformation (i.e., diversified generation) between source domain and target domain. To train our framework, we propose a likelihood-based multi-domain cooperative learning algorithm to jointly train the multi-domain descriptor and the diversified image generator (including translator, style encoder, and style generator modules) via multi-domain MCMC teaching, in which the descriptor guides the diversified image generator to shift its probability density toward the data distribution, while the diversified image generator uses its randomly translated images to initialize the descriptor's Langevin dynamics process for efficient sampling.
Robust Transfer Learning with Pretrained Language Models through Adapters
Aug 05, 2021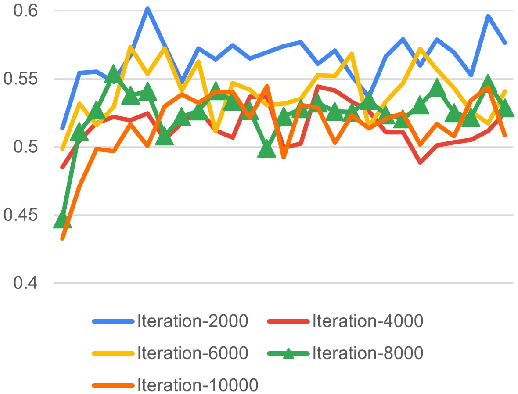

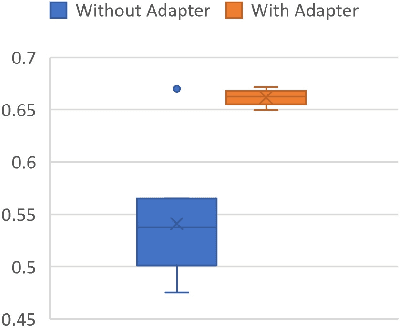

Transfer learning with large pretrained transformer-based language models like BERT has become a dominating approach for most NLP tasks. Simply fine-tuning those large language models on downstream tasks or combining it with task-specific pretraining is often not robust. In particular, the performance considerably varies as the random seed changes or the number of pretraining and/or fine-tuning iterations varies, and the fine-tuned model is vulnerable to adversarial attack. We propose a simple yet effective adapter-based approach to mitigate these issues. Specifically, we insert small bottleneck layers (i.e., adapter) within each layer of a pretrained model, then fix the pretrained layers and train the adapter layers on the downstream task data, with (1) task-specific unsupervised pretraining and then (2) task-specific supervised training (e.g., classification, sequence labeling). Our experiments demonstrate that such a training scheme leads to improved stability and adversarial robustness in transfer learning to various downstream tasks.
Deep neural network based i-vector mapping for speaker verification using short utterances
Oct 16, 2018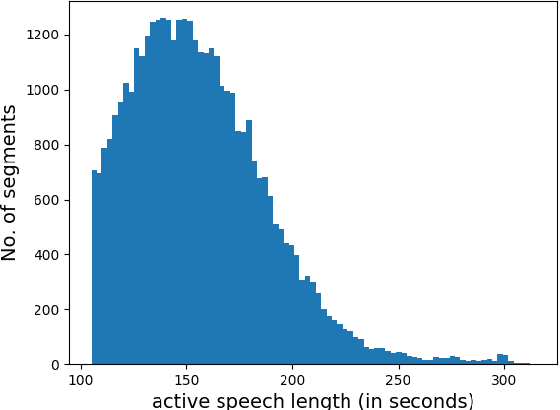
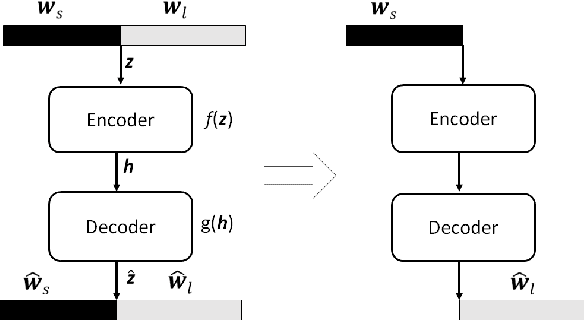

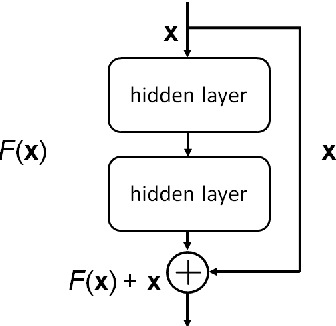
Text-independent speaker recognition using short utterances is a highly challenging task due to the large variation and content mismatch between short utterances. I-vector based systems have become the standard in speaker verification applications, but they are less effective with short utterances. In this paper, we first compare two state-of-the-art universal background model training methods for i-vector modeling using full-length and short utterance evaluation tasks. The two methods are Gaussian mixture model (GMM) based and deep neural network (DNN) based methods. The results indicate that the I-vector_DNN system outperforms the I-vector_GMM system under various durations. However, the performances of both systems degrade significantly as the duration of the utterances decreases. To address this issue, we propose two novel nonlinear mapping methods which train DNN models to map the i-vectors extracted from short utterances to their corresponding long-utterance i-vectors. The mapped i-vector can restore missing information and reduce the variance of the original short-utterance i-vectors. The proposed methods both model the joint representation of short and long utterance i-vectors by using autoencoder. Experimental results using the NIST SRE 2010 dataset show that both methods provide significant improvement and result in a max of 28.43% relative improvement in Equal Error Rates from a baseline system, when using deep encoder with residual blocks and adding an additional phoneme vector. When further testing the best-validated models of SRE10 on the Speaker In The Wild dataset, the methods result in a 23.12% improvement on arbitrary-duration (1-5 s) short-utterance conditions.
Layered Logic Classifiers: Exploring the `And' and `Or' Relations
May 28, 2014



Designing effective and efficient classifier for pattern analysis is a key problem in machine learning and computer vision. Many the solutions to the problem require to perform logic operations such as `and', `or', and `not'. Classification and regression tree (CART) include these operations explicitly. Other methods such as neural networks, SVM, and boosting learn/compute a weighted sum on features (weak classifiers), which weakly perform the 'and' and 'or' operations. However, it is hard for these classifiers to deal with the 'xor' pattern directly. In this paper, we propose layered logic classifiers for patterns of complicated distributions by combining the `and', `or', and `not' operations. The proposed algorithm is very general and easy to implement. We test the classifiers on several typical datasets from the Irvine repository and two challenging vision applications, object segmentation and pedestrian detection. We observe significant improvements on all the datasets over the widely used decision stump based AdaBoost algorithm. The resulting classifiers have much less training complexity than decision tree based AdaBoost, and can be applied in a wide range of domains.