 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeelBERto: Self-supervised Commonsense Learning for Question Answering
Mar 17, 2022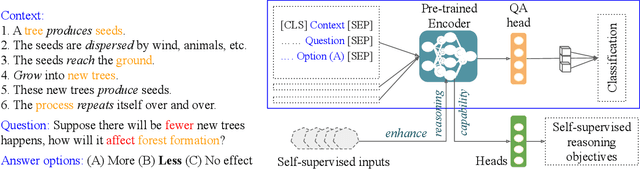

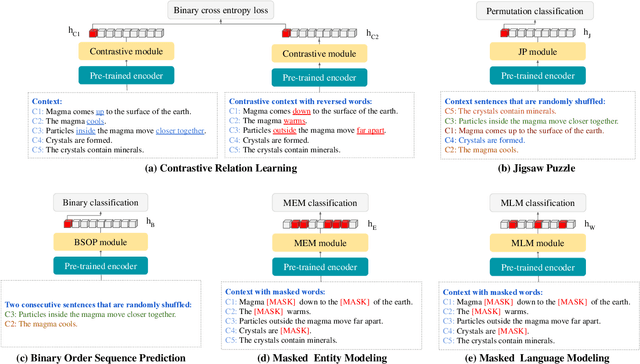
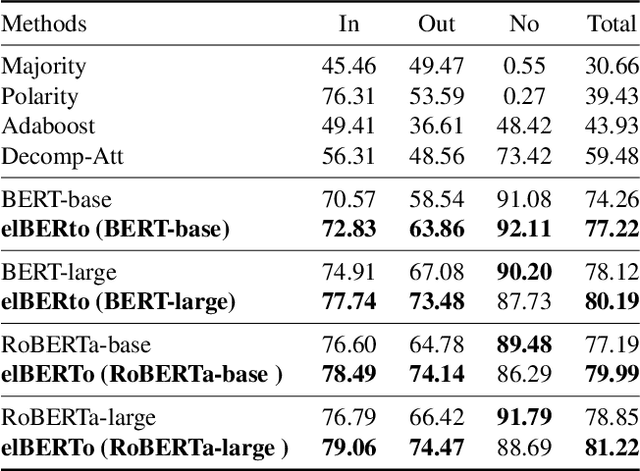
Commonsense question answering requires reasoning about everyday situations and causes and effects implicit in context. Typically, existing approaches first retrieve external evidence and then perform commonsense reasoning using these evidence. In this paper, we propose a Self-supervised Bidirectional Encoder Representation Learning of Commonsense (elBERto) framework, which is compatible with off-the-shelf QA model architectures. The framework comprises five self-supervised tasks to force the model to fully exploit the additional training signals from contexts containing rich commonsense. The tasks include a novel Contrastive Relation Learning task to encourage the model to distinguish between logically contrastive contexts, a new Jigsaw Puzzle task that requires the model to infer logical chains in long contexts, and three classic SSL tasks to maintain pre-trained models language encoding ability. On the representative WIQA, CosmosQA, and ReClor datasets, elBERto outperforms all other methods, including those utilizing explicit graph reasoning and external knowledge retrieval. Moreover, elBERto achieves substantial improvements on out-of-paragraph and no-effect questions where simple lexical similarity comparison does not help, indicating that it successfully learns commonsense and is able to leverage it when given dynamic context.
A Causal Lens for Controllable Text Generation
Jan 22, 2022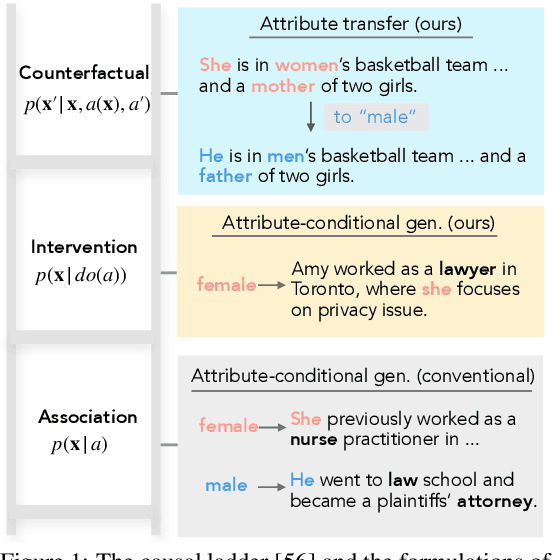
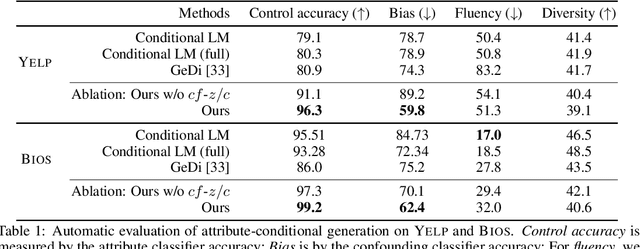
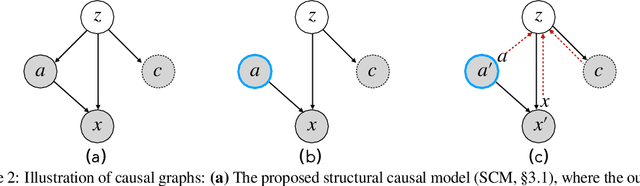
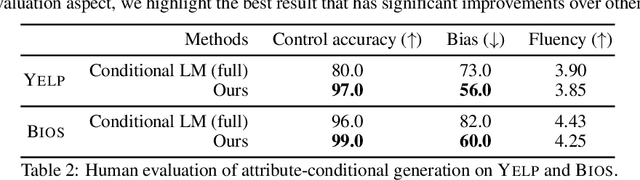
Controllable text generation concerns two fundamental tasks of wide applications, namely generating text of given attributes (i.e., attribute-conditional generation), and minimally editing existing text to possess desired attributes (i.e., text attribute transfer). Extensive prior work has largely studied the two problems separately, and developed different conditional models which, however, are prone to producing biased text (e.g., various gender stereotypes). This paper proposes to formulate controllable text generation from a principled causal perspective which models the two tasks with a unified framework. A direct advantage of the causal formulation is the use of rich causality tools to mitigate generation biases and improve control. We treat the two tasks as interventional and counterfactual causal inference based on a structural causal model, respectively. We then apply the framework to the challenging practical setting where confounding factors (that induce spurious correlations) are observable only on a small fraction of data. Experiments show significant superiority of the causal approach over previous conditional models for improved control accuracy and reduced bias.
Compression, Transduction, and Creation: A Unified Framework for Evaluating Natural Language Generation
Sep 14, 2021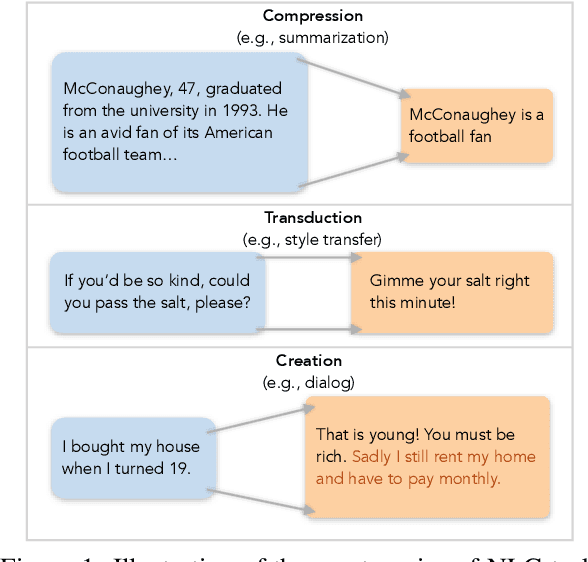
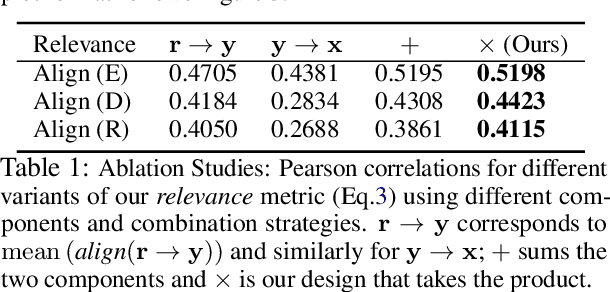
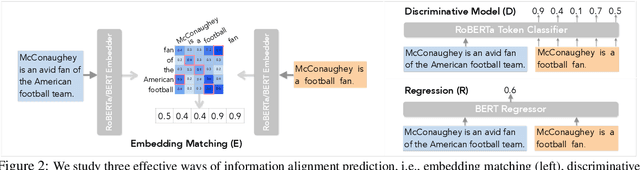

Natural language generation (NLG) spans a broad range of tasks, each of which serves for specific objectives and desires different properties of generated text. The complexity makes automatic evaluation of NLG particularly challenging. Previous work has typically focused on a single task and developed individual evaluation metrics based on specific intuitions. In this paper, we propose a unifying perspective based on the nature of information change in NLG tasks, including compression (e.g., summarization), transduction (e.g., text rewriting), and creation (e.g., dialog). Information alignment between input, context, and output text plays a common central role in characterizing the generation. With automatic alignment prediction models, we develop a family of interpretable metrics that are suitable for evaluating key aspects of different NLG tasks, often without need of gold reference data. Experiments show the uniformly designed metrics achieve stronger or comparable correlations with human judgement compared to state-of-the-art metrics in each of diverse tasks, including text summarization, style transfer, and knowledge-grounded dialog.
Panoramic Learning with A Standardized Machine Learning Formalism
Aug 17, 2021Machine Learning (ML) is about computational methods that enable machines to learn concepts from experiences. In handling a wide variety of experiences ranging from data instances, knowledge, constraints, to rewards, adversaries, and lifelong interplay in an ever-growing spectrum of tasks, contemporary ML/AI research has resulted in a multitude of learning paradigms and methodologies. Despite the continual progresses on all different fronts, the disparate narrowly-focused methods also make standardized, composable, and reusable development of learning solutions difficult, and make it costly if possible to build AI agents that panoramically learn from all types of experiences. This paper presents a standardized ML formalism, in particular a standard equation of the learning objective, that offers a unifying understanding of diverse ML algorithms, making them special cases due to different choices of modeling components. The framework also provides guidance for mechanic design of new ML solutions, and serves as a promising vehicle towards panoramic learning with all experiences.
Don't Take It Literally: An Edit-Invariant Sequence Loss for Text Generation
Jul 23, 2021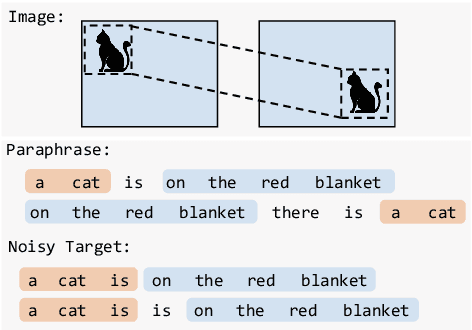
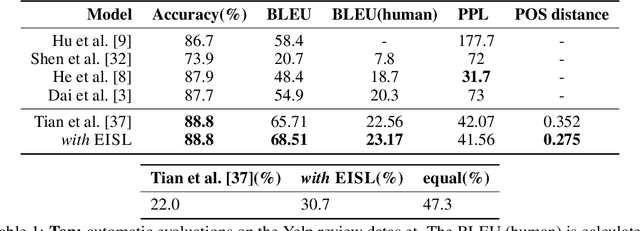
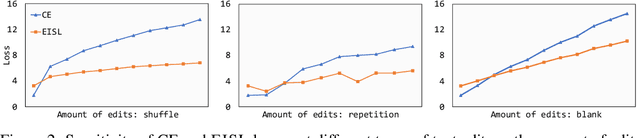
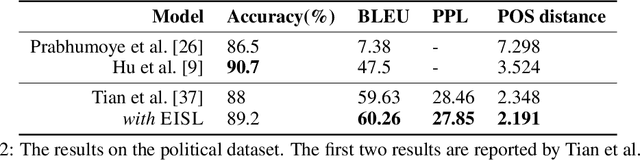
Neural text generation models are typically trained by maximizing log-likelihood with the sequence cross entropy loss, which encourages an exact token-by-token match between a target sequence with a generated sequence. Such training objective is sub-optimal when the target sequence not perfect, e.g., when the target sequence is corrupted with noises, or when only weak sequence supervision is available. To address this challenge, we propose a novel Edit-Invariant Sequence Loss (EISL), which computes the matching loss of a target n-gram with all n-grams in the generated sequence. EISL draws inspirations from convolutional networks (ConvNets) which are shift-invariant to images, hence is robust to the shift of n-grams to tolerate edits in the target sequences. Moreover, the computation of EISL is essentially a convolution operation with target n-grams as kernels, which is easy to implement with existing libraries. To demonstrate the effectiveness of EISL, we conduct experiments on three tasks: machine translation with noisy target sequences, unsupervised text style transfer, and non-autoregressive machine translation. Experimental results show our method significantly outperforms cross entropy loss on these three tasks.
Text Generation with Efficient (Soft) Q-Learning
Jun 17, 2021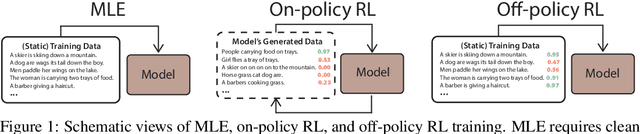
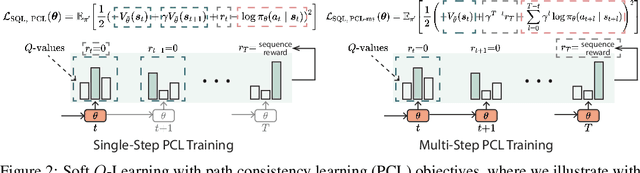
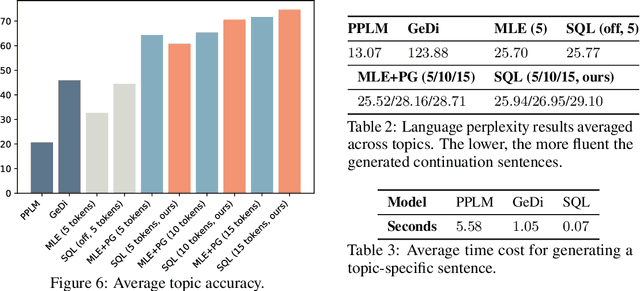
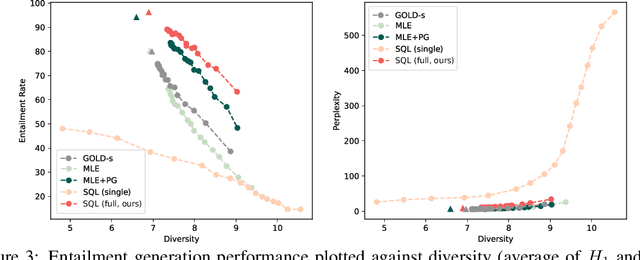
Maximum likelihood estimation (MLE) is the predominant algorithm for training text generation models. This paradigm relies on direct supervision examples, which is not applicable to many applications, such as generating adversarial attacks or generating prompts to control language models. Reinforcement learning (RL) on the other hand offers a more flexible solution by allowing users to plug in arbitrary task metrics as reward. Yet previous RL algorithms for text generation, such as policy gradient (on-policy RL) and Q-learning (off-policy RL), are often notoriously inefficient or unstable to train due to the large sequence space and the sparse reward received only at the end of sequences. In this paper, we introduce a new RL formulation for text generation from the soft Q-learning perspective. It further enables us to draw from the latest RL advances, such as path consistency learning, to combine the best of on-/off-policy updates, and learn effectively from sparse reward. We apply the approach to a wide range of tasks, including learning from noisy/negative examples, adversarial attacks, and prompt generation. Experiments show our approach consistently outperforms both task-specialized algorithms and the previous RL methods. On standard supervised tasks where MLE prevails, our approach also achieves competitive performance and stability by training text generation from scratch.
A Data-Centric Framework for Composable NLP Workflows
Mar 03, 2021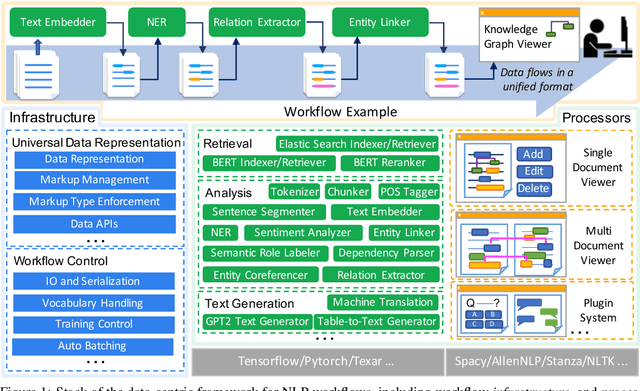
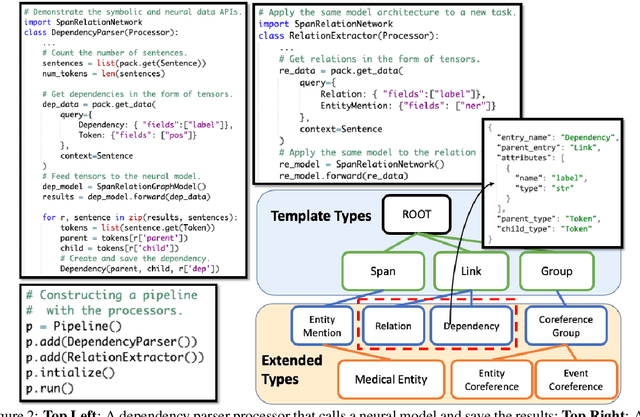
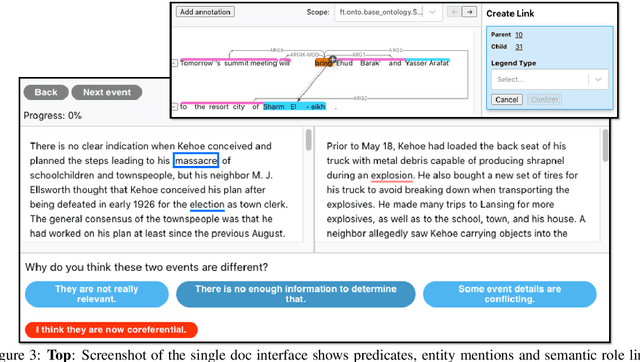
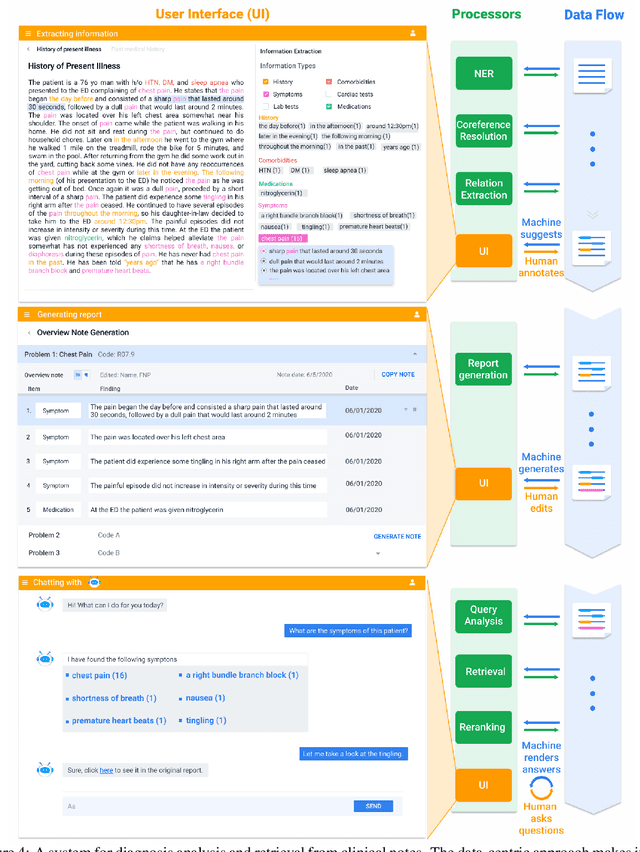
Empirical natural language processing (NLP) systems in application domains (e.g., healthcare, finance, education) involve interoperation among multiple components, ranging from data ingestion, human annotation, to text retrieval, analysis, generation, and visualization. We establish a unified open-source framework to support fast development of such sophisticated NLP workflows in a composable manner. The framework introduces a uniform data representation to encode heterogeneous results by a wide range of NLP tasks. It offers a large repository of processors for NLP tasks, visualization, and annotation, which can be easily assembled with full interoperability under the unified representation. The highly extensible framework allows plugging in custom processors from external off-the-shelf NLP and deep learning libraries. The whole framework is delivered through two modularized yet integratable open-source projects, namely Forte1 (for workflow infrastructure and NLP function processors) and Stave2 (for user interaction, visualization, and annotation).
Summarizing Text on Any Aspects: A Knowledge-Informed Weakly-Supervised Approach
Oct 18, 2020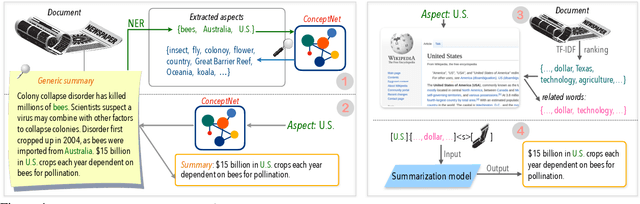
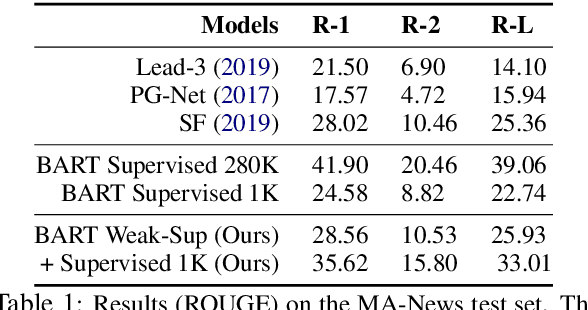
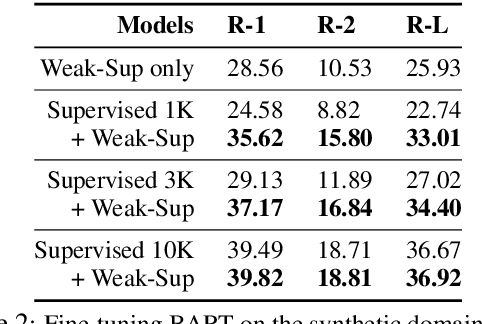
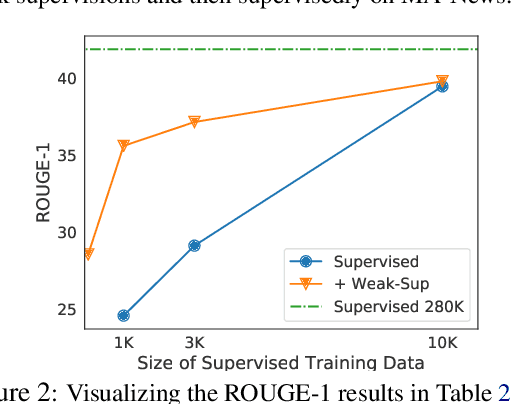
Given a document and a target aspect (e.g., a topic of interest), aspect-based abstractive summarization attempts to generate a summary with respect to the aspect. Previous studies usually assume a small pre-defined set of aspects and fall short of summarizing on other diverse topics. In this work, we study summarizing on arbitrary aspects relevant to the document, which significantly expands the application of the task in practice. Due to the lack of supervision data, we develop a new weak supervision construction method and an aspect modeling scheme, both of which integrate rich external knowledge sources such as ConceptNet and Wikipedia. Experiments show our approach achieves performance boosts on summarizing both real and synthetic documents given pre-defined or arbitrary aspects.
A Survey of Knowledge-Enhanced Text Generation
Oct 09, 2020



The goal of text generation is to make machines express in human language. It is one of the most important yet challenging tasks in natural language processing (NLP). Since 2014, various neural encoder-decoder models pioneered by Seq2Seq have been proposed to achieve the goal by learning to map input text to output text. However, the input text alone often provides limited knowledge to generate the desired output, so the performance of text generation is still far from satisfaction in many real-world scenarios. To address this issue, researchers have considered incorporating various forms of knowledge beyond the input text into the generation models. This research direction is known as knowledge-enhanced text generation. In this survey, we present a comprehensive review of the research on knowledge enhanced text generation over the past five years. The main content includes two parts: (i) general methods and architectures for integrating knowledge into text generation; (ii) specific techniques and applications according to different forms of knowledge data. This survey can have broad audiences, researchers and practitioners, in academia and industry.
Improving GAN Training with Probability Ratio Clipping and Sample Reweighting
Jun 30, 2020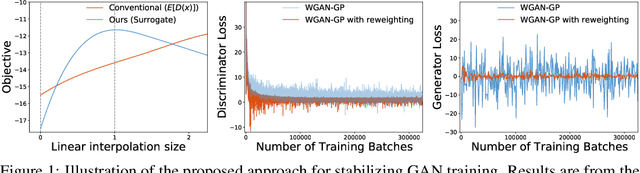


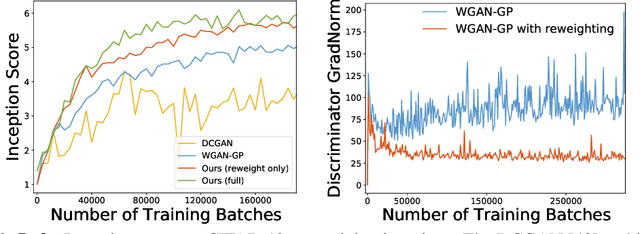
Despite success on a wide range of problems related to vision, generative adversarial networks (GANs) can suffer from inferior performance due to unstable training, especially for text generation. We propose a new variational GAN training framework which enjoys superior training stability. Our approach is inspired by a connection of GANs and reinforcement learning under a variational perspective. The connection leads to (1) probability ratio clipping that regularizes generator training to prevent excessively large updates, and (2) a sample re-weighting mechanism that stabilizes discriminator training by downplaying bad-quality fake samples. We provide theoretical analysis on the convergence of our approach. By plugging the training approach in diverse state-of-the-art GAN architectures, we obtain significantly improved performance over a range of tasks, including text generation, text style transfer, and image generation.