 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Is No Longer Believing: Frontier Image Generation Models, Synthetic Visual Evidence, and Real-World Risk
Apr 27, 2026Frontier image generation has moved from artistic synthesis toward synthetic visual evidence. Systems such as GPT Image 2, Nano Banana Pro, Nano Banana 2, Grok Imagine, Qwen Image 2.0 Pro, and Seedream 5.0 Lite combine photorealistic rendering, readable typography, reference consistency, editing control, and in several cases reasoning or search-grounded image construction. These capabilities create large benefits for design, education, accessibility, and communication, yet they also weaken one of society's most common trust shortcuts: the belief that a plausible picture is a reliable record. This paper provides a source-grounded technical and policy analysis of synthetic visual risk. We first summarize the public capabilities of recent image models, then analyze public incidents involving fake crisis images, celebrity and public-figure imagery, medical scans, forged-looking documents, synthetic screenshots, phishing assets, and market-moving rumors. We introduce a capability-weighted risk framework that links model affordances to real-world harm in finance, medicine, news, law, emergency response, identity verification, and civic discourse. Our findings show that risk is driven less by photorealism alone than by the convergence of realism, legible text, identity persistence, fast iteration, and distribution context. We argue for layered control: model-side restrictions, cryptographic provenance, visible labeling, platform friction, sector-grade verification, and incident response. The paper closes with practical recommendations for model providers, platforms, newsrooms, financial institutions, healthcare systems, legal organizations, regulators, and ordinary users.
The Rise of Verbal Tics in Large Language Models: A Systematic Analysis Across Frontier Models
Apr 21, 2026As Large Language Models (LLMs) continue to evolve through alignment techniques such as Reinforcement Learning from Human Feedback (RLHF) and Constitutional AI, a growing and increasingly conspicuous phenomenon has emerged: the proliferation of verbal tics -- repetitive, formulaic linguistic patterns that pervade model outputs. These range from sycophantic openers ("That's a great question!", "Awesome!") to pseudo-empathetic affirmations ("I completely understand your concern", "I'm right here to catch you") and overused vocabulary ("delve", "tapestry", "nuanced"). In this paper, we present a systematic analysis of the verbal tic phenomenon across eight state-of-the-art LLMs: GPT-5.4, Claude Opus 4.7, Gemini 3.1 Pro, Grok 4.2, Doubao-Seed-2.0-pro, Kimi K2.5, DeepSeek V3.2, and MiMo-V2-Pro. Utilizing a custom evaluation framework for standardized API-based evaluation, we assess 10,000 prompts across 10 task categories in both English and Chinese, yielding 160,000 model responses. We introduce the Verbal Tic Index (VTI), a composite metric quantifying tic prevalence, and analyze its correlation with sycophancy, lexical diversity, and human-perceived naturalness. Our findings reveal significant inter-model variation: Gemini 3.1 Pro exhibits the highest VTI (0.590), while DeepSeek V3.2 achieves the lowest (0.295). We further demonstrate that verbal tics accumulate over multi-turn conversations, are amplified in subjective tasks, and show distinct cross-lingual patterns. Human evaluation (N = 120) confirms a strong inverse relationship between sycophancy and perceived naturalness (r = -0.87, p < 0.001). These results underscore the "alignment tax" of current training paradigms and highlight the urgent need for more authentic human-AI interaction frameworks.
UHD Low-Light Image Enhancement via Real-Time Enhancement Methods with Clifford Information Fusion
Apr 10, 2026Considering efficiency, ultra-high-definition (UHD) low-light image restoration is extremely challenging. Existing methods based on Transformer architectures or high-dimensional complex convolutional neural networks often suffer from the "memory wall" bottleneck, failing to achieve millisecond-level inference on edge devices. To address this issue, we propose a novel real-time UHD low-light enhancement network based on geometric feature fusion using Clifford algebra in 2D Euclidean space. First, we construct a four-layer feature pyramid with gradually increasing resolution, which decomposes input images into low-frequency and high-frequency structural components via a Gaussian blur kernel, and adopts a lightweight U-Net based on depthwise separable convolution for dual-branch feature extraction. Second, to resolve structural information loss and artifacts from traditional high-low frequency feature fusion, we introduce spatially aware Clifford algebra, which maps feature tensors to a multivector space (scalars, vectors, bivectors) and uses Clifford similarity to aggregate features while suppressing noise and preserving textures. In the reconstruction stage, the network outputs adaptive Gamma and Gain maps, which perform physically constrained non-linear brightness adjustment via Retinex theory. Integrated with FP16 mixed-precision computation and dynamic operator fusion, our method achieves millisecond-level inference for 4K/8K images on a single consumer-grade device, while outperforming state-of-the-art (SOTA) models on several restoration metrics.
Council Mode: Mitigating Hallucination and Bias in LLMs via Multi-Agent Consensus
Apr 03, 2026Large Language Models (LLMs), particularly those employing Mixture-of-Experts (MoE) architectures, have achieved remarkable capabilities across diverse natural language processing tasks. However, these models frequently suffer from hallucinations -- generating plausible but factually incorrect content -- and exhibit systematic biases that are amplified by uneven expert activation during inference. In this paper, we propose the Council Mode, a novel multi-agent consensus framework that addresses these limitations by dispatching queries to multiple heterogeneous frontier LLMs in parallel and synthesizing their outputs through a dedicated consensus model. The Council pipeline operates in three phases: (1) an intelligent triage classifier that routes queries based on complexity, (2) parallel expert generation across architecturally diverse models, and (3) a structured consensus synthesis that explicitly identifies agreement, disagreement, and unique findings before producing the final response. We implement and evaluate this architecture within an open-source AI workspace. Our comprehensive evaluation across multiple benchmarks demonstrates that the Council Mode achieves a 35.9% relative reduction in hallucination rates on the HaluEval benchmark and a 7.8-point improvement on TruthfulQA compared to the best-performing individual model, while maintaining significantly lower bias variance across domains. We provide the mathematical formulation of the consensus mechanism, detail the system architecture, and present extensive empirical results with ablation studies.
Magnetic Milli-spinner for Robotic Endovascular Surgery
Oct 28, 2024



Vascular diseases such as thrombosis, atherosclerosis, and aneurysm, which can lead to blockage of blood flow or blood vessel rupture, are common and life-threatening. Conventional minimally invasive treatments utilize catheters, or long tubes, to guide small devices or therapeutic agents to targeted regions for intervention. Unfortunately, catheters suffer from difficult and unreliable navigation in narrow, winding vessels such as those found in the brain. Magnetically actuated untethered robots, which have been extensively explored as an alternative, are promising for navigation in complex vasculatures and vascular disease treatments. Most current robots, however, cannot swim against high flows or are inadequate in treating certain conditions. Here, we introduce a multifunctional and magnetically actuated milli-spinner robot for rapid navigation and performance of various treatments in complicated vasculatures. The milli-spinner, with a unique hollow structure including helical fins and slits for propulsion, generates a distinct flow field upon spinning. The milli-spinner is the fastest-ever untethered magnetic robot for movement in tubular environments, easily achieving speeds of 23 cm/s, demonstrating promise as an untethered medical device for effective navigation in blood vessels and robotic treatment of numerous vascular diseases.
Physics-aware differentiable design of magnetically actuated kirigami for shape morphing
Aug 09, 2023Shape morphing that transforms morphologies in response to stimuli is crucial for future multifunctional systems. While kirigami holds great promise in enhancing shape-morphing, existing designs primarily focus on kinematics and overlook the underlying physics. This study introduces a differentiable inverse design framework that considers the physical interplay between geometry, materials, and stimuli of active kirigami, made by soft material embedded with magnetic particles, to realize target shape-morphing upon magnetic excitation. We achieve this by combining differentiable kinematics and energy models into a constrained optimization, simultaneously designing the cuts and magnetization orientations to ensure kinematic and physical feasibility. Complex kirigami designs are obtained automatically with unparallel efficiency, which can be remotely controlled to morph into intricate target shapes and even multiple states. The proposed framework can be extended to accommodate various active systems, bridging geometry and physics to push the frontiers in shape-morphing applications, like flexible electronics and minimally invasive surgery.
Stiffness Change for Reconfiguration of Inflated Beam Robots
Jul 06, 2023



Active control of the shape of soft robots is challenging. Despite having an infinite number of passive degrees of freedom (DOFs), soft robots typically only have a few actively controllable DOFs, limited by the number of degrees of actuation (DOAs). The complexity of actuators restricts the number of DOAs that can be incorporated into soft robots. Active shape control is further complicated by the buckling of soft robots under compressive forces; this is particularly challenging for compliant continuum robots due to their long aspect ratios. In this work, we show how variable stiffness can enable shape control of soft robots by addressing these challenges. Dynamically changing the stiffness of sections along a compliant continuum robot can selectively "activate" discrete joints. By changing which joints are activated, the output of a single actuator can be reconfigured to actively control many different joints, thus decoupling the number of controllable DOFs from the number of DOAs. We demonstrate embedded positive pressure layer jamming as a simple method for stiffness change in inflated beam robots, its compatibility with growing robots, and its use as an "activating" technology. We experimentally characterize the stiffness change in a growing inflated beam robot and present finite element models which serve as guides for robot design and fabrication. We fabricate a multi-segment everting inflated beam robot and demonstrate how stiffness change is compatible with growth through tip eversion, enables an increase in workspace, and achieves new actuation patterns not possible without stiffening.
Efficient and Accurate Co-Visible Region Localization with Matching Key-Points Crop (MKPC): A Two-Stage Pipeline for Enhancing Image Matching Performance
Mar 24, 2023



Image matching is a classic and fundamental task in computer vision. In this paper, under the hypothesis that the areas outside the co-visible regions carry little information, we propose a matching key-points crop (MKPC) algorithm. The MKPC locates, proposes and crops the critical regions, which are the co-visible areas with great efficiency and accuracy. Furthermore, building upon MKPC, we propose a general two-stage pipeline for image matching, which is compatible to any image matching models or combinations. We experimented with plugging SuperPoint + SuperGlue into the two-stage pipeline, whose results show that our method enhances the performance for outdoor pose estimations. What's more, in a fair comparative condition, our method outperforms the SOTA on Image Matching Challenge 2022 Benchmark, which represents the hardest outdoor benchmark of image matching currently.
Spinning-enabled Wireless Amphibious Origami Millirobot
Mar 18, 2022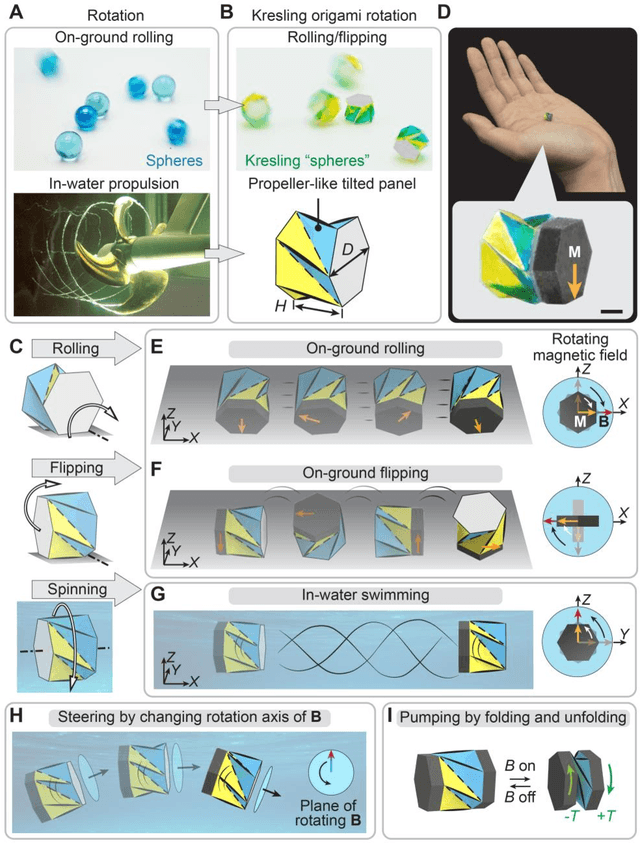
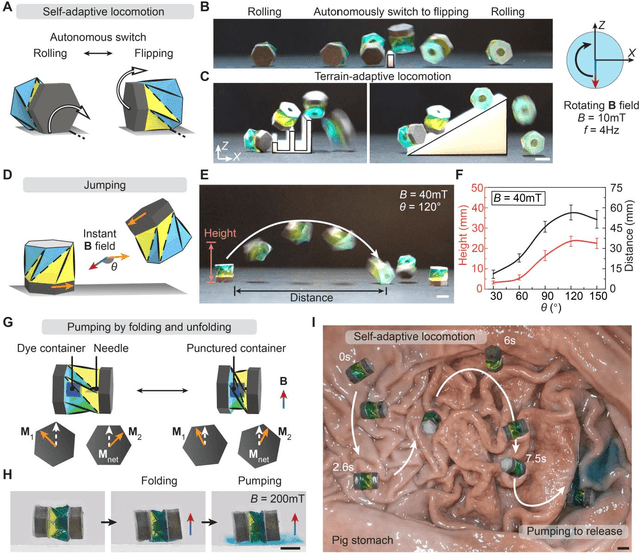
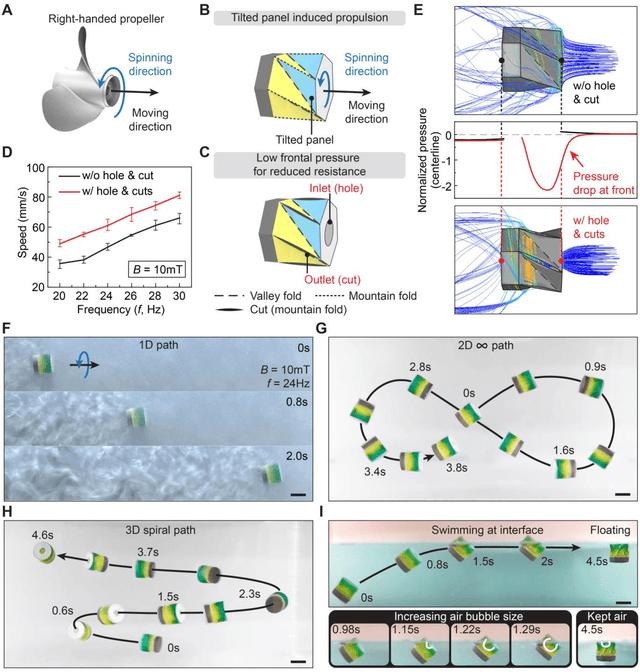
Wireless millimeter-scale origami robots that can locomote in narrow spaces and morph their shapes have recently been explored with great potential for biomedical applications. Existing millimeter-scale origami devices usually require separate geometrical components for locomotion and functions, which increases the complexity of the robotic systems and their operation upon limited locomotion modes. Additionally, none of them can achieve both on-ground and in-water locomotion. Here we report a magnetically actuated amphibious origami millirobot that integrates capabilities of spinning-enabled multimodal locomotion, controlled delivery of liquid medicine, and cargo transportation with wireless operation. This millirobot takes full advantage of the geometrical features and folding/unfolding capability of Kresling origami, a triangulated hollow cylinder, to fulfill multifunction: its geometrical features are exploited for generating omnidirectional locomotion in various working environments, including on unstructured ground, in liquids, and at air-liquid interfaces through rolling, flipping, and spinning-induced propulsion; the folding/unfolding is utilized as a pumping mechanism for integrated multifunctionality such as controlled delivery of liquid medicine; furthermore, the spinning motion provides a sucking mechanism for targeted solid cargo transportation. This origami millirobot breaks the conventional way of utilizing origami folding only for shape reconfiguration and integrates multiple functions in one simple body. We anticipate the reported magnetic amphibious origami millirobots have the potential to serve as minimally invasive devices for biomedical diagnoses and treatments.