 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRL: Combining SLIP Model and Reinforcement Learning for Agile Robotic Jumping
Jun 17, 2026Robotic jumping is pivotal in applications such as search and rescue and logistics, where crossing obstacles and enhancing mobility efficiency are critical. The Spring-Loaded Inverted Pendulum (SLIP) model leverages simplified spring-mass dynamics that naturally encode biologically plausible hopping motions, yet its performance degrades on irregular terrain due to idealized assumptions regarding contact and joint dynamics. Meanwhile, Reinforcement Learning (RL) can adapt to diverse and complex environments but often requires extensive data from unguided exploration. The complementary strengths of SLIP's physically grounded baseline and RL's adaptive capabilities motivate a hybrid framework that overcomes these individual limitations. We therefore propose Spring-loaded Reinforcement Learning (SRL), which integrates SLIP-based feedforward control signals with RL-driven real-time feedback, enabling continuous optimization of robotic jumping. Experimental results demonstrate that SRL can achieve more stable jumps with much less training time than the baseline method, maintaining an average position tracking error below 0.1 m and velocity tracking errors within +/-3% of the target values. Through bipedal and quadrupedal simulations of ground and stair jumping, as well as sim-to-sim and sim-to-real validations, SRL exhibits robust adaptability to various task requirements and environmental complexities, underscoring its potential for real-world deployment.
Hierarchical Structure-Property Alignment for Data-Efficient Molecular Generation and Editing
Nov 11, 2025Property-constrained molecular generation and editing are crucial in AI-driven drug discovery but remain hindered by two factors: (i) capturing the complex relationships between molecular structures and multiple properties remains challenging, and (ii) the narrow coverage and incomplete annotations of molecular properties weaken the effectiveness of property-based models. To tackle these limitations, we propose HSPAG, a data-efficient framework featuring hierarchical structure-property alignment. By treating SMILES and molecular properties as complementary modalities, the model learns their relationships at atom, substructure, and whole-molecule levels. Moreover, we select representative samples through scaffold clustering and hard samples via an auxiliary variational auto-encoder (VAE), substantially reducing the required pre-training data. In addition, we incorporate a property relevance-aware masking mechanism and diversified perturbation strategies to enhance generation quality under sparse annotations. Experiments demonstrate that HSPAG captures fine-grained structure-property relationships and supports controllable generation under multiple property constraints. Two real-world case studies further validate the editing capabilities of HSPAG.
Unity RL Playground: A Versatile Reinforcement Learning Framework for Mobile Robots
Mar 07, 2025



This paper introduces Unity RL Playground, an open-source reinforcement learning framework built on top of Unity ML-Agents. Unity RL Playground automates the process of training mobile robots to perform various locomotion tasks such as walking, running, and jumping in simulation, with the potential for seamless transfer to real hardware. Key features include one-click training for imported robot models, universal compatibility with diverse robot configurations, multi-mode motion learning capabilities, and extreme performance testing to aid in robot design optimization and morphological evolution. The attached video can be found at https://linqi-ye.github.io/video/iros25.mp4 and the code is coming soon.
MBC: Multi-Brain Collaborative Control for Quadruped Robots
Sep 24, 2024In the field of locomotion task of quadruped robots, Blind Policy and Perceptive Policy each have their own advantages and limitations. The Blind Policy relies on preset sensor information and algorithms, suitable for known and structured environments, but it lacks adaptability in complex or unknown environments. The Perceptive Policy uses visual sensors to obtain detailed environmental information, allowing it to adapt to complex terrains, but its effectiveness is limited under occluded conditions, especially when perception fails. Unlike the Blind Policy, the Perceptive Policy is not as robust under these conditions. To address these challenges, we propose a MBC:Multi-Brain collaborative system that incorporates the concepts of Multi-Agent Reinforcement Learning and introduces collaboration between the Blind Policy and the Perceptive Policy. By applying this multi-policy collaborative model to a quadruped robot, the robot can maintain stable locomotion even when the perceptual system is impaired or observational data is incomplete. Our simulations and real-world experiments demonstrate that this system significantly improves the robot's passability and robustness against perception failures in complex environments, validating the effectiveness of multi-policy collaboration in enhancing robotic motion performance.
Adaptive Inverse Mapping: A Model-free Semi-supervised Learning Approach towards Robust Imaging through Dynamic Scattering Media
Aug 18, 2021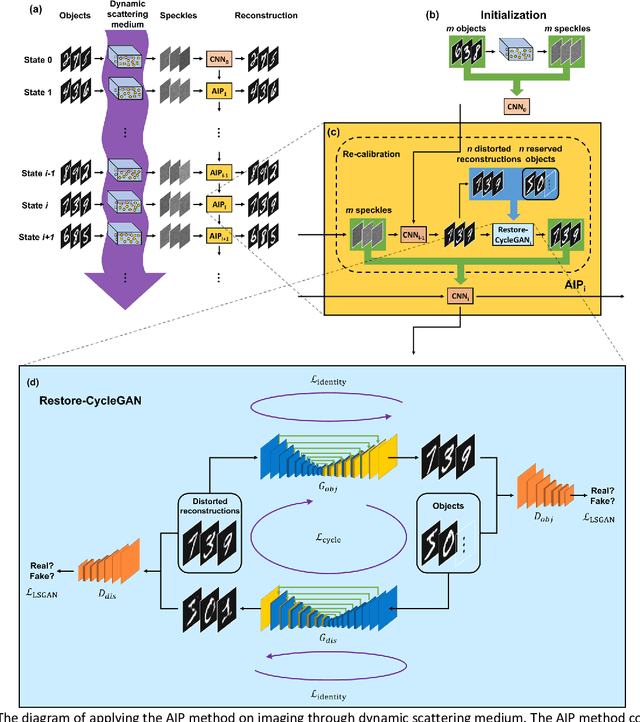
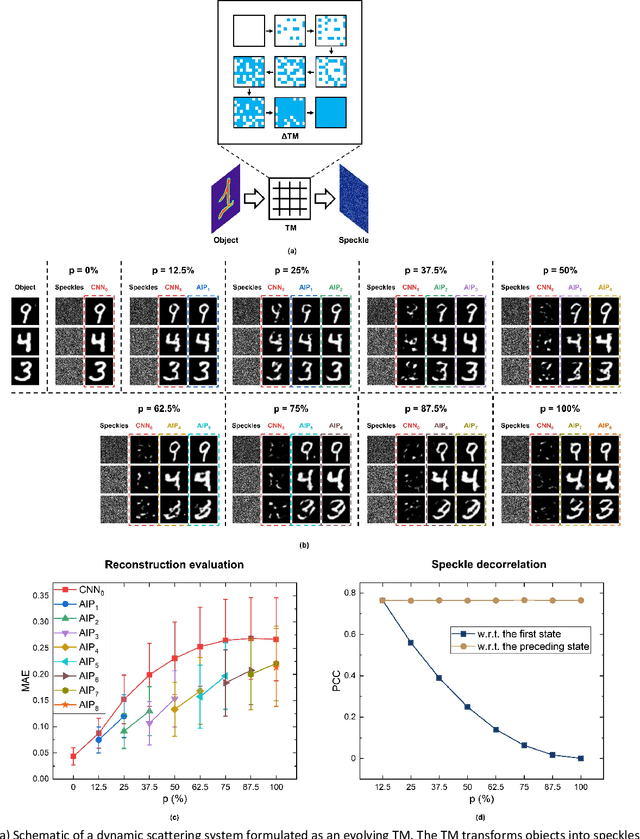
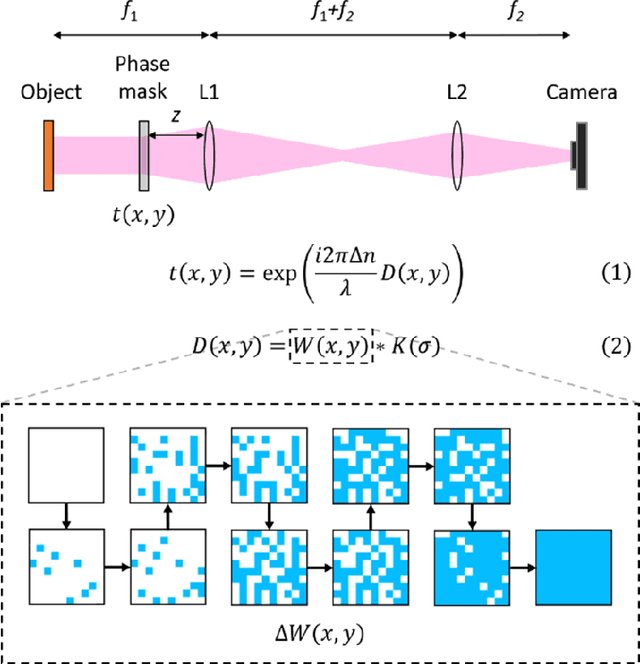
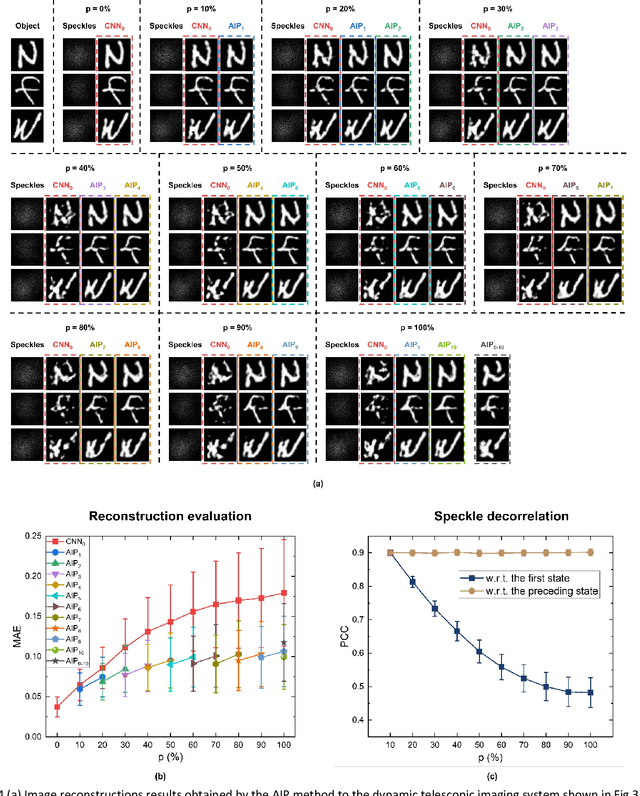
Imaging through scattering media is a useful and yet demanding task since it involves solving for an inverse mapping from speckle images to object images. It becomes even more challenging when the scattering medium undergoes dynamic changes. Various approaches have been proposed in recent years. However, to date, none is able to preserve high image quality without either assuming a finite number of sources for dynamic changes, assuming a thin scattering medium, or requiring the access to both ends of the medium. In this paper, we propose an adaptive inverse mapping (AIP) method which is flexible regarding any dynamic change and only requires output speckle images after initialization. We show that the inverse mapping can be corrected through unsupervised learning if the output speckle images are followed closely. We test the AIP method on two numerical simulations, namely, a dynamic scattering system formulated as an evolving transmission matrix and a telescope with a changing random phase mask at a defocus plane. Then we experimentally apply the AIP method on a dynamic fiber-optic imaging system. Increased robustness in imaging is observed in all three cases. With the excellent performance, we see the great potential of the AIP method in imaging through dynamic scattering media.