 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Normalization for Accelerating and Stabilizing Transformers
Aug 02, 2022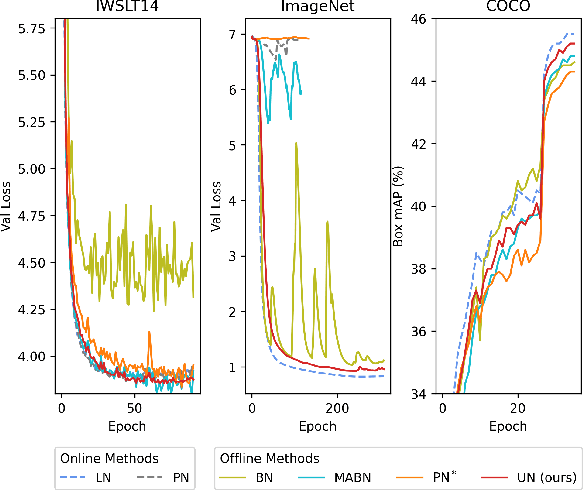
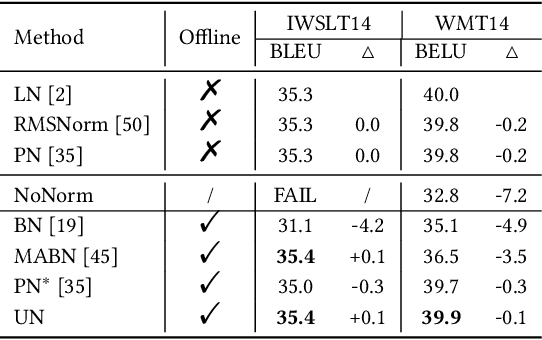
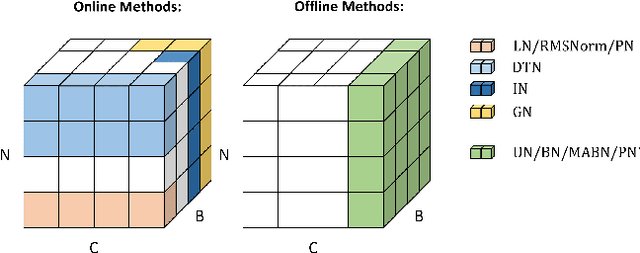
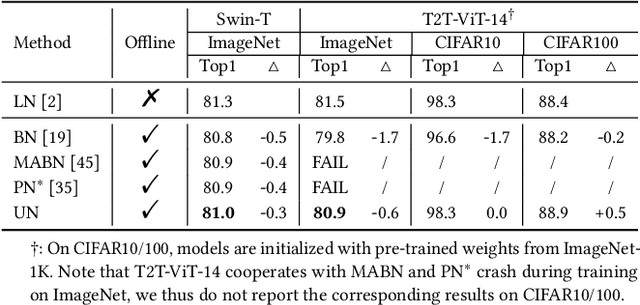
Solid results from Transformers have made them prevailing architectures in various natural language and vision tasks. As a default component in Transformers, Layer Normalization (LN) normalizes activations within each token to boost the robustness. However, LN requires on-the-fly statistics calculation in inference as well as division and square root operations, leading to inefficiency on hardware. What is more, replacing LN with other hardware-efficient normalization schemes (e.g., Batch Normalization) results in inferior performance, even collapse in training. We find that this dilemma is caused by abnormal behaviors of activation statistics, including large fluctuations over iterations and extreme outliers across layers. To tackle these issues, we propose Unified Normalization (UN), which can speed up the inference by being fused with other linear operations and achieve comparable performance on par with LN. UN strives to boost performance by calibrating the activation and gradient statistics with a tailored fluctuation smoothing strategy. Meanwhile, an adaptive outlier filtration strategy is applied to avoid collapse in training whose effectiveness is theoretically proved and experimentally verified in this paper. We demonstrate that UN can be an efficient drop-in alternative to LN by conducting extensive experiments on language and vision tasks. Besides, we evaluate the efficiency of our method on GPU. Transformers equipped with UN enjoy about 31% inference speedup and nearly 18% memory reduction. Code will be released at https://github.com/hikvision-research/Unified-Normalization.
A Safe Semi-supervised Graph Convolution Network
Jul 05, 2022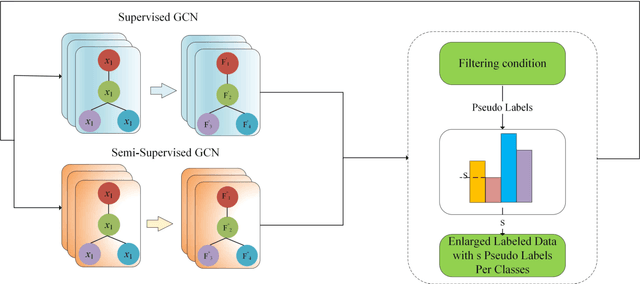
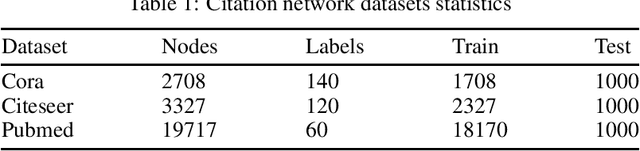
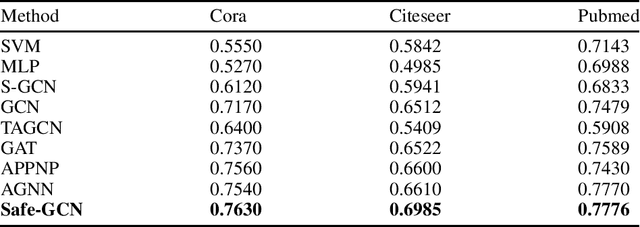
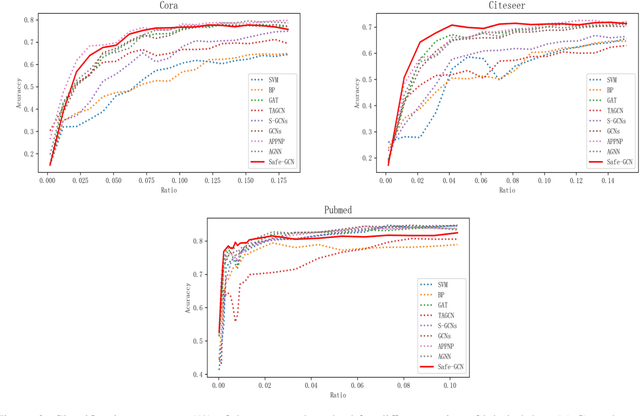
In the semi-supervised learning field, Graph Convolution Network (GCN), as a variant model of GNN, has achieved promising results for non-Euclidean data by introducing convolution into GNN. However, GCN and its variant models fail to safely use the information of risk unlabeled data, which will degrade the performance of semi-supervised learning. Therefore, we propose a Safe GCN framework (Safe-GCN) to improve the learning performance. In the Safe-GCN, we design an iterative process to label the unlabeled data. In each iteration, a GCN and its supervised version(S-GCN) are learned to find the unlabeled data with high confidence. The high-confidence unlabeled data and their pseudo labels are then added to the label set. Finally, both added unlabeled data and labeled ones are used to train a S-GCN which can achieve the safe exploration of the risk unlabeled data and enable safe use of large numbers of unlabeled data. The performance of Safe-GCN is evaluated on three well-known citation network datasets and the obtained results demonstrate the effectiveness of the proposed framework over several graph-based semi-supervised learning methods.
NAFS: A Simple yet Tough-to-beat Baseline for Graph Representation Learning
Jun 17, 2022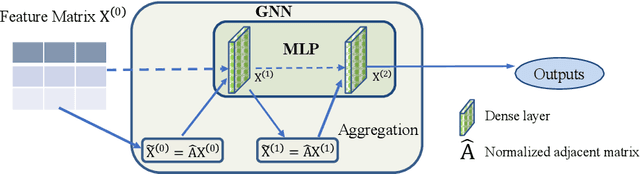
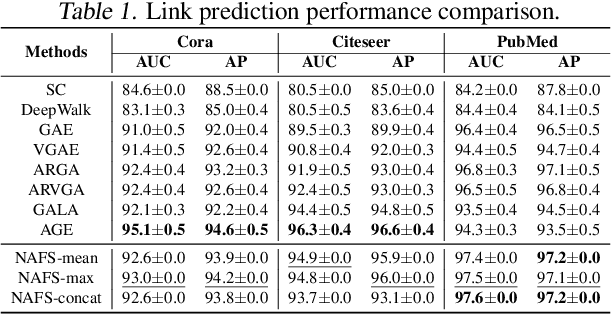
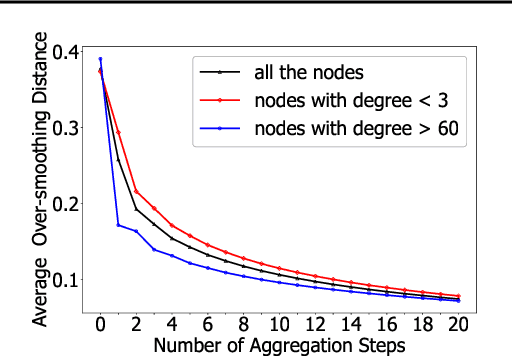
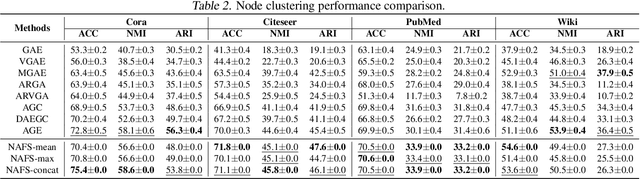
Recently, graph neural networks (GNNs) have shown prominent performance in graph representation learning by leveraging knowledge from both graph structure and node features. However, most of them have two major limitations. First, GNNs can learn higher-order structural information by stacking more layers but can not deal with large depth due to the over-smoothing issue. Second, it is not easy to apply these methods on large graphs due to the expensive computation cost and high memory usage. In this paper, we present node-adaptive feature smoothing (NAFS), a simple non-parametric method that constructs node representations without parameter learning. NAFS first extracts the features of each node with its neighbors of different hops by feature smoothing, and then adaptively combines the smoothed features. Besides, the constructed node representation can further be enhanced by the ensemble of smoothed features extracted via different smoothing strategies. We conduct experiments on four benchmark datasets on two different application scenarios: node clustering and link prediction. Remarkably, NAFS with feature ensemble outperforms the state-of-the-art GNNs on these tasks and mitigates the aforementioned two limitations of most learning-based GNN counterparts.
* 17 pages, 8 figures
DFG-NAS: Deep and Flexible Graph Neural Architecture Search
Jun 17, 2022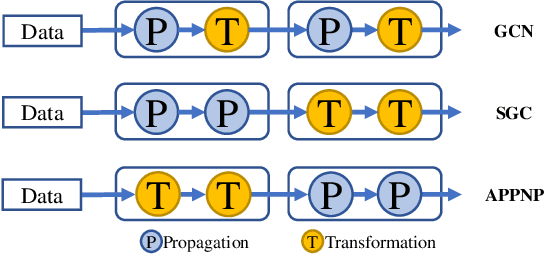
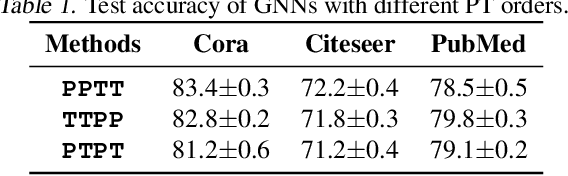
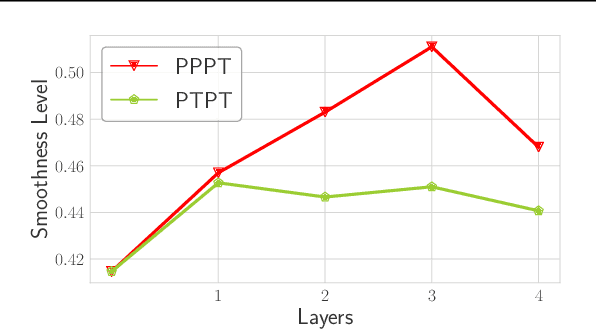
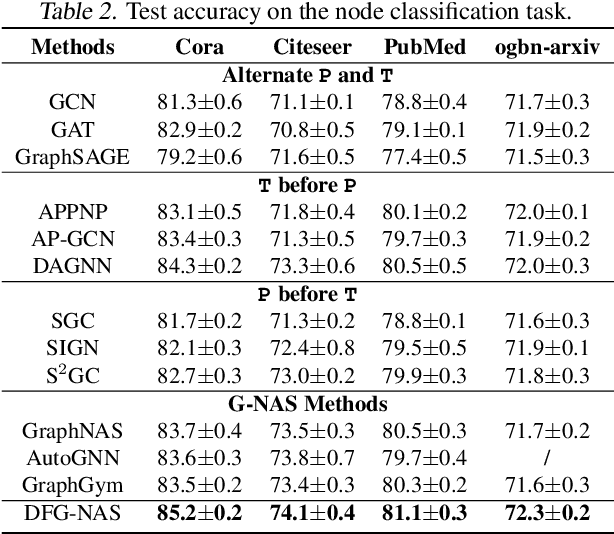
Graph neural networks (GNNs) have been intensively applied to various graph-based applications. Despite their success, manually designing the well-behaved GNNs requires immense human expertise. And thus it is inefficient to discover the potentially optimal data-specific GNN architecture. This paper proposes DFG-NAS, a new neural architecture search (NAS) method that enables the automatic search of very deep and flexible GNN architectures. Unlike most existing methods that focus on micro-architectures, DFG-NAS highlights another level of design: the search for macro-architectures on how atomic propagation (\textbf{\texttt{P}}) and transformation (\textbf{\texttt{T}}) operations are integrated and organized into a GNN. To this end, DFG-NAS proposes a novel search space for \textbf{\texttt{P-T}} permutations and combinations based on message-passing dis-aggregation, defines four custom-designed macro-architecture mutations, and employs the evolutionary algorithm to conduct an efficient and effective search. Empirical studies on four node classification tasks demonstrate that DFG-NAS outperforms state-of-the-art manual designs and NAS methods of GNNs.
* 13 pages, 7 figures
Model Degradation Hinders Deep Graph Neural Networks
Jun 09, 2022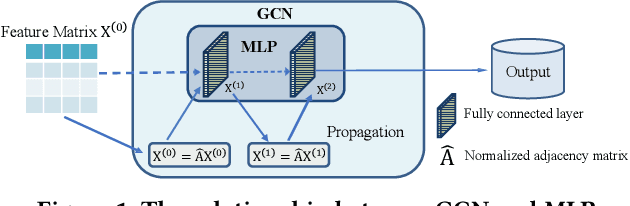
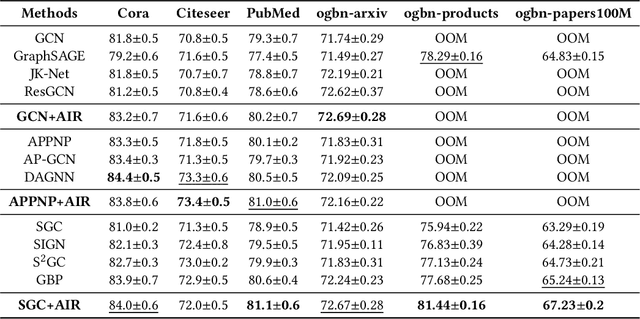
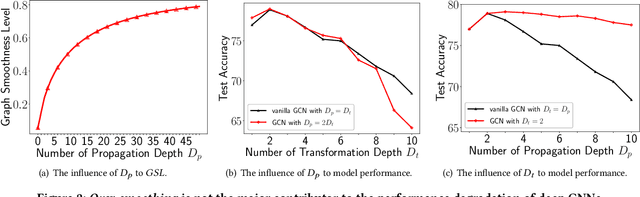
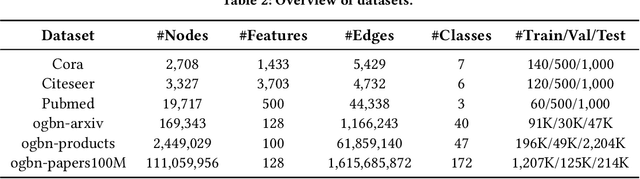
Graph Neural Networks (GNNs) have achieved great success in various graph mining tasks.However, drastic performance degradation is always observed when a GNN is stacked with many layers. As a result, most GNNs only have shallow architectures, which limits their expressive power and exploitation of deep neighborhoods.Most recent studies attribute the performance degradation of deep GNNs to the \textit{over-smoothing} issue. In this paper, we disentangle the conventional graph convolution operation into two independent operations: \textit{Propagation} (\textbf{P}) and \textit{Transformation} (\textbf{T}).Following this, the depth of a GNN can be split into the propagation depth ($D_p$) and the transformation depth ($D_t$). Through extensive experiments, we find that the major cause for the performance degradation of deep GNNs is the \textit{model degradation} issue caused by large $D_t$ rather than the \textit{over-smoothing} issue mainly caused by large $D_p$. Further, we present \textit{Adaptive Initial Residual} (AIR), a plug-and-play module compatible with all kinds of GNN architectures, to alleviate the \textit{model degradation} issue and the \textit{over-smoothing} issue simultaneously. Experimental results on six real-world datasets demonstrate that GNNs equipped with AIR outperform most GNNs with shallow architectures owing to the benefits of both large $D_p$ and $D_t$, while the time costs associated with AIR can be ignored.
* 11 pages, 10 figures
Graph Attention Multi-Layer Perceptron
Jun 09, 2022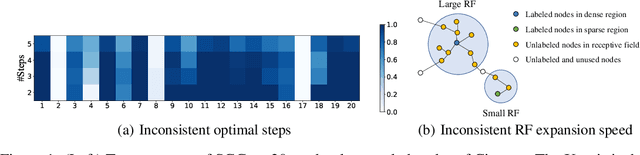

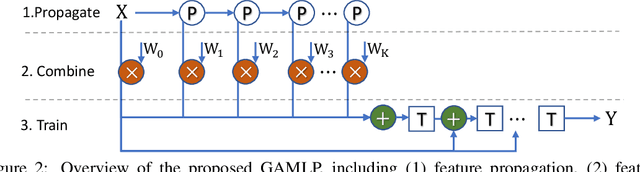
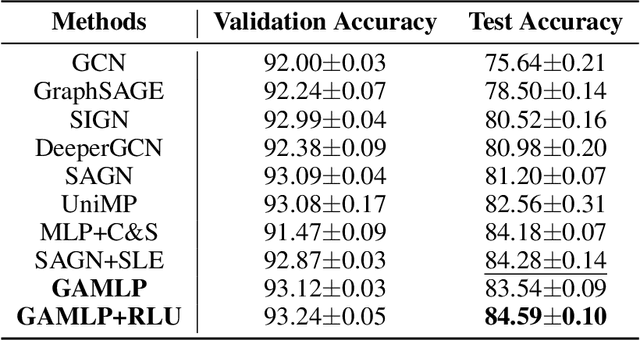
Graph neural networks (GNNs) have achieved great success in many graph-based applications. However, the enormous size and high sparsity level of graphs hinder their applications under industrial scenarios. Although some scalable GNNs are proposed for large-scale graphs, they adopt a fixed $K$-hop neighborhood for each node, thus facing the over-smoothing issue when adopting large propagation depths for nodes within sparse regions. To tackle the above issue, we propose a new GNN architecture -- Graph Attention Multi-Layer Perceptron (GAMLP), which can capture the underlying correlations between different scales of graph knowledge. We have deployed GAMLP in Tencent with the Angel platform, and we further evaluate GAMLP on both real-world datasets and large-scale industrial datasets. Extensive experiments on these 14 graph datasets demonstrate that GAMLP achieves state-of-the-art performance while enjoying high scalability and efficiency. Specifically, it outperforms GAT by 1.3\% regarding predictive accuracy on our large-scale Tencent Video dataset while achieving up to $50\times$ training speedup. Besides, it ranks top-1 on both the leaderboards of the largest homogeneous and heterogeneous graph (i.e., ogbn-papers100M and ogbn-mag) of Open Graph Benchmark.
* 11 pages, 7 figures. arXiv admin note: text overlap with arXiv:2108.10097
TransBO: Hyperparameter Optimization via Two-Phase Transfer Learning
Jun 06, 2022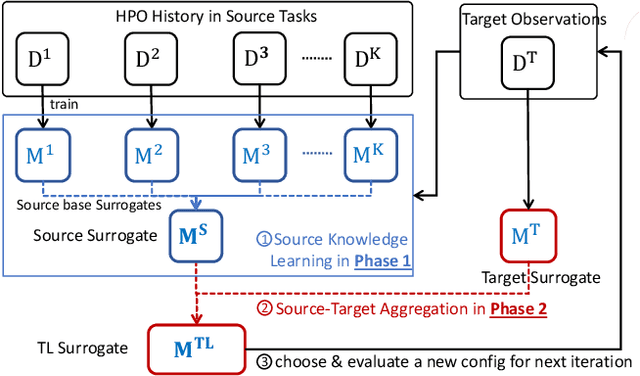
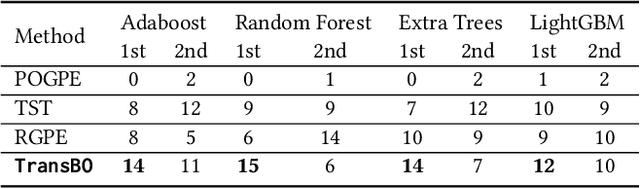
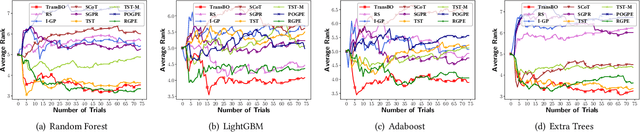

With the extensive applications of machine learning models, automatic hyperparameter optimization (HPO) has become increasingly important. Motivated by the tuning behaviors of human experts, it is intuitive to leverage auxiliary knowledge from past HPO tasks to accelerate the current HPO task. In this paper, we propose TransBO, a novel two-phase transfer learning framework for HPO, which can deal with the complementary nature among source tasks and dynamics during knowledge aggregation issues simultaneously. This framework extracts and aggregates source and target knowledge jointly and adaptively, where the weights can be learned in a principled manner. The extensive experiments, including static and dynamic transfer learning settings and neural architecture search, demonstrate the superiority of TransBO over the state-of-the-arts.
* 9 pages and 2 extra pages of appendix
Instance-wise Prompt Tuning for Pretrained Language Models
Jun 04, 2022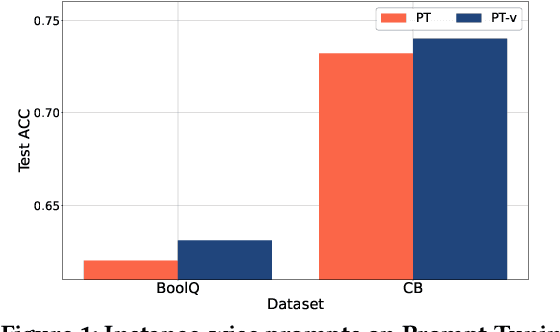

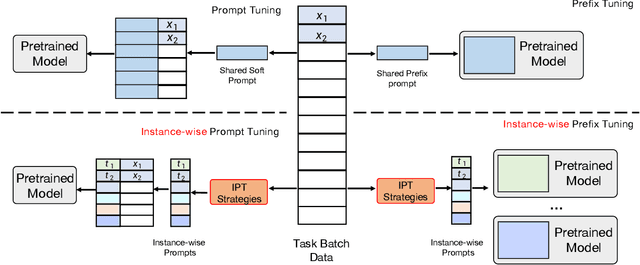
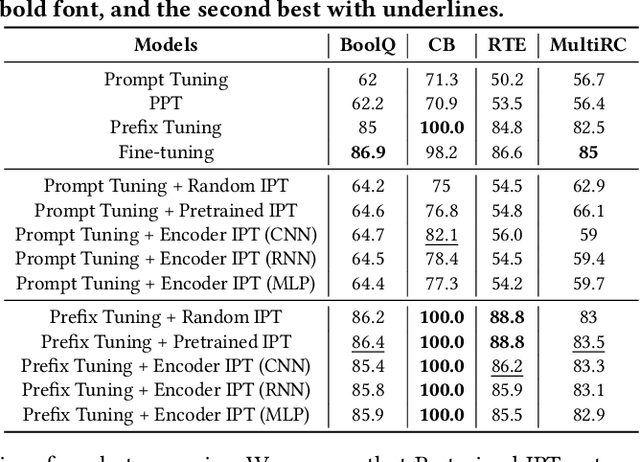
Prompt Learning has recently gained great popularity in bridging the gap between pretraining tasks and various downstream tasks. It freezes Pretrained Language Models (PLMs) and only tunes a few task-related parameters (prompts) for downstream tasks, greatly reducing the cost of tuning giant models. The key enabler of this is the idea of querying PLMs with task-specific knowledge implicated in prompts. This paper reveals a major limitation of existing methods that the indiscriminate prompts for all input data in a task ignore the intrinsic knowledge from input data, resulting in sub-optimal performance. We introduce Instance-wise Prompt Tuning (IPT), the first prompt learning paradigm that injects knowledge from the input data instances to the prompts, thereby providing PLMs with richer and more concrete context information. We devise a series of strategies to produce instance-wise prompts, addressing various concerns like model quality and cost-efficiency. Across multiple tasks and resource settings, IPT significantly outperforms task-based prompt learning methods, and achieves comparable performance to conventional finetuning with only 0.5% - 1.5% of tuned parameters.
AMCAD: Adaptive Mixed-Curvature Representation based Advertisement Retrieval System
Mar 28, 2022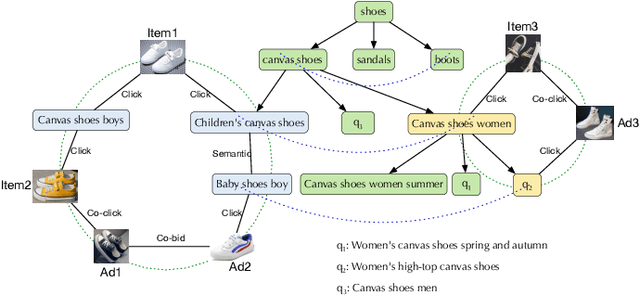
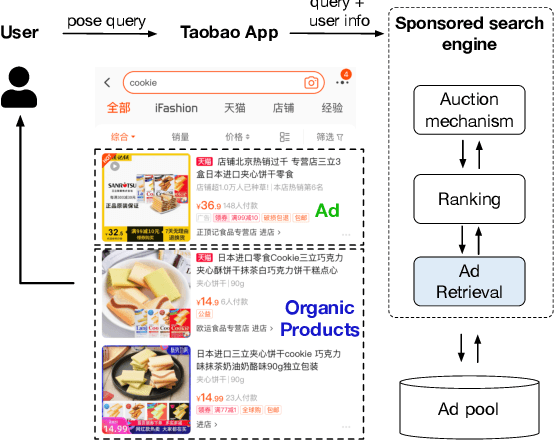
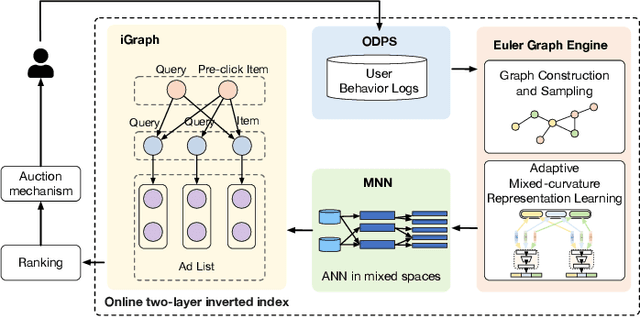
Graph embedding based retrieval has become one of the most popular techniques in the information retrieval community and search engine industry. The classical paradigm mainly relies on the flat Euclidean geometry. In recent years, hyperbolic (negative curvature) and spherical (positive curvature) representation methods have shown their superiority to capture hierarchical and cyclic data structures respectively. However, in industrial scenarios such as e-commerce sponsored search platforms, the large-scale heterogeneous query-item-advertisement interaction graphs often have multiple structures coexisting. Existing methods either only consider a single geometry space, or combine several spaces manually, which are incapable and inflexible to model the complexity and heterogeneity in the real scenario. To tackle this challenge, we present a web-scale Adaptive Mixed-Curvature ADvertisement retrieval system (AMCAD) to automatically capture the complex and heterogeneous graph structures in non-Euclidean spaces. Specifically, entities are represented in adaptive mixed-curvature spaces, where the types and curvatures of the subspaces are trained to be optimal combinations. Besides, an attentive edge-wise space projector is designed to model the similarities between heterogeneous nodes according to local graph structures and the relation types. Moreover, to deploy AMCAD in Taobao, one of the largest ecommerce platforms with hundreds of million users, we design an efficient two-layer online retrieval framework for the task of graph based advertisement retrieval. Extensive evaluations on real-world datasets and A/B tests on online traffic are conducted to illustrate the effectiveness of the proposed system.
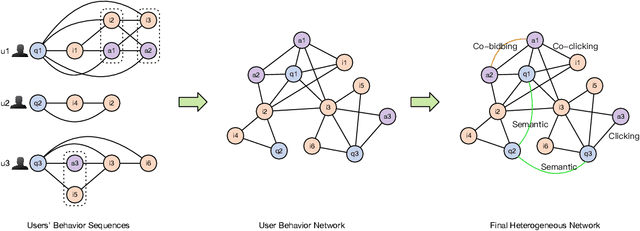
ZOOMER: Boosting Retrieval on Web-scale Graphs by Regions of Interest
Mar 20, 2022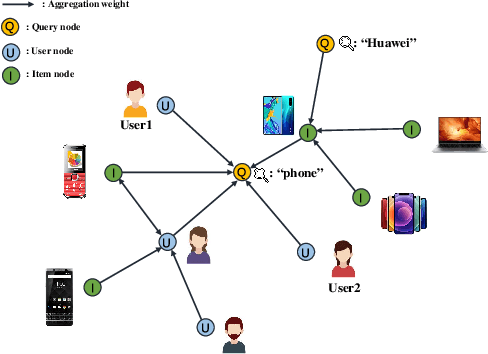
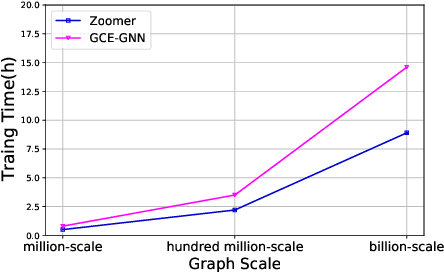
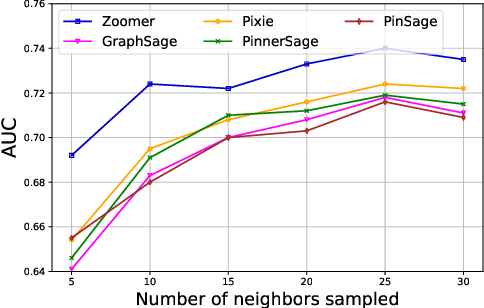
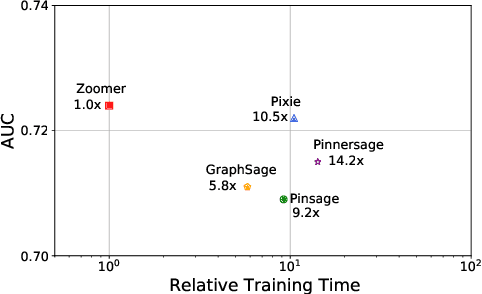
We introduce ZOOMER, a system deployed at Taobao, the largest e-commerce platform in China, for training and serving GNN-based recommendations over web-scale graphs. ZOOMER is designed for tackling two challenges presented by the massive user data at Taobao: low training/serving efficiency due to the huge scale of the graphs, and low recommendation quality due to the information overload which distracts the recommendation model from specific user intentions. ZOOMER achieves this by introducing a key concept, Region of Interests (ROI) in GNNs for recommendations, i.e., a neighborhood region in the graph with significant relevance to a strong user intention. ZOOMER narrows the focus from the whole graph and "zooms in" on the more relevant ROIs, thereby reducing the training/serving cost and mitigating the information overload at the same time. With carefully designed mechanisms, ZOOMER identifies the interest expressed by each recommendation request, constructs an ROI subgraph by sampling with respect to the interest, and guides the GNN to reweigh different parts of the ROI towards the interest by a multi-level attention module. Deployed as a large-scale distributed system, ZOOMER supports graphs with billions of nodes for training and thousands of requests per second for serving. ZOOMER achieves up to 14x speedup when downsizing sampling scales with comparable (even better) AUC performance than baseline methods. Besides, both the offline evaluation and online A/B test demonstrate the effectiveness of ZOOMER.