 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHVTSurv: Hierarchical Vision Transformer for Patient-Level Survival Prediction from Whole Slide Image
Jun 30, 2023



Survival prediction based on whole slide images (WSIs) is a challenging task for patient-level multiple instance learning (MIL). Due to the vast amount of data for a patient (one or multiple gigapixels WSIs) and the irregularly shaped property of WSI, it is difficult to fully explore spatial, contextual, and hierarchical interaction in the patient-level bag. Many studies adopt random sampling pre-processing strategy and WSI-level aggregation models, which inevitably lose critical prognostic information in the patient-level bag. In this work, we propose a hierarchical vision Transformer framework named HVTSurv, which can encode the local-level relative spatial information, strengthen WSI-level context-aware communication, and establish patient-level hierarchical interaction. Firstly, we design a feature pre-processing strategy, including feature rearrangement and random window masking. Then, we devise three layers to progressively obtain patient-level representation, including a local-level interaction layer adopting Manhattan distance, a WSI-level interaction layer employing spatial shuffle, and a patient-level interaction layer using attention pooling. Moreover, the design of hierarchical network helps the model become more computationally efficient. Finally, we validate HVTSurv with 3,104 patients and 3,752 WSIs across 6 cancer types from The Cancer Genome Atlas (TCGA). The average C-Index is 2.50-11.30% higher than all the prior weakly supervised methods over 6 TCGA datasets. Ablation study and attention visualization further verify the superiority of the proposed HVTSurv. Implementation is available at: https://github.com/szc19990412/HVTSurv.
AMCAD: Adaptive Mixed-Curvature Representation based Advertisement Retrieval System
Mar 28, 2022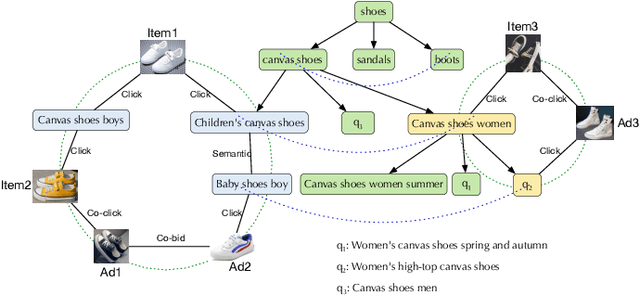
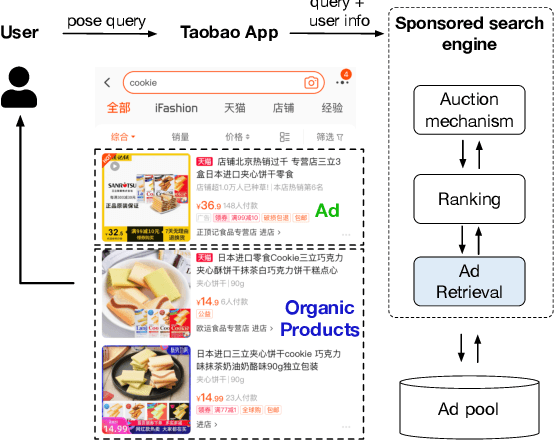
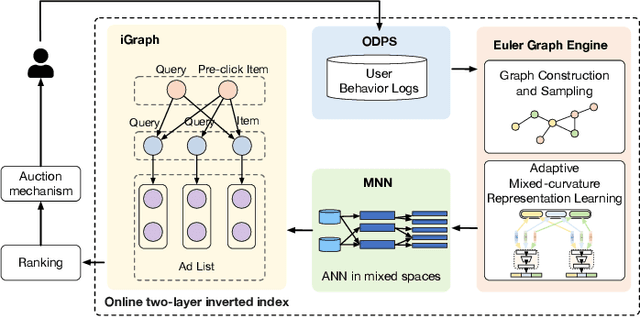
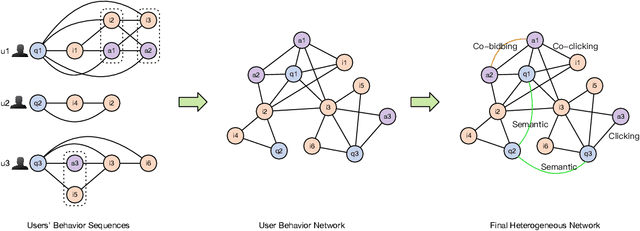
Graph embedding based retrieval has become one of the most popular techniques in the information retrieval community and search engine industry. The classical paradigm mainly relies on the flat Euclidean geometry. In recent years, hyperbolic (negative curvature) and spherical (positive curvature) representation methods have shown their superiority to capture hierarchical and cyclic data structures respectively. However, in industrial scenarios such as e-commerce sponsored search platforms, the large-scale heterogeneous query-item-advertisement interaction graphs often have multiple structures coexisting. Existing methods either only consider a single geometry space, or combine several spaces manually, which are incapable and inflexible to model the complexity and heterogeneity in the real scenario. To tackle this challenge, we present a web-scale Adaptive Mixed-Curvature ADvertisement retrieval system (AMCAD) to automatically capture the complex and heterogeneous graph structures in non-Euclidean spaces. Specifically, entities are represented in adaptive mixed-curvature spaces, where the types and curvatures of the subspaces are trained to be optimal combinations. Besides, an attentive edge-wise space projector is designed to model the similarities between heterogeneous nodes according to local graph structures and the relation types. Moreover, to deploy AMCAD in Taobao, one of the largest ecommerce platforms with hundreds of million users, we design an efficient two-layer online retrieval framework for the task of graph based advertisement retrieval. Extensive evaluations on real-world datasets and A/B tests on online traffic are conducted to illustrate the effectiveness of the proposed system.
Asymptotically Unbiased Estimation for Delayed Feedback Modeling via Label Correction
Feb 15, 2022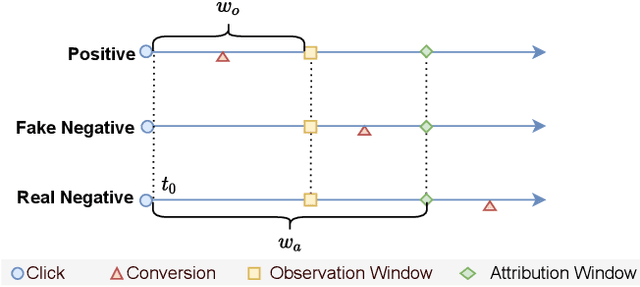
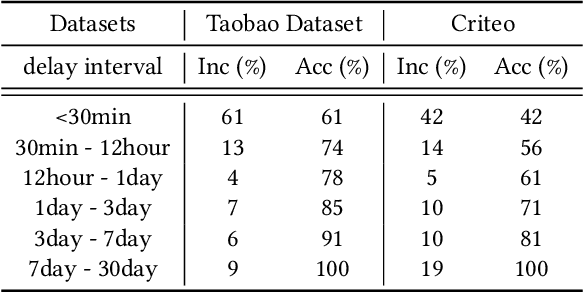

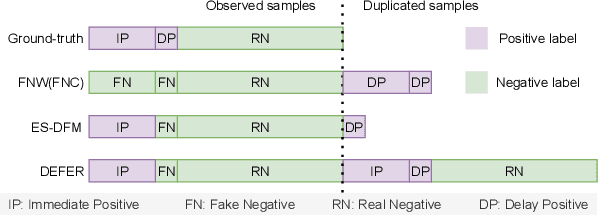
Alleviating the delayed feedback problem is of crucial importance for the conversion rate(CVR) prediction in online advertising. Previous delayed feedback modeling methods using an observation window to balance the trade-off between waiting for accurate labels and consuming fresh feedback. Moreover, to estimate CVR upon the freshly observed but biased distribution with fake negatives, the importance sampling is widely used to reduce the distribution bias. While effective, we argue that previous approaches falsely treat fake negative samples as real negative during the importance weighting and have not fully utilized the observed positive samples, leading to suboptimal performance. In this work, we propose a new method, DElayed Feedback modeling with UnbiaSed Estimation, (DEFUSE), which aim to respectively correct the importance weights of the immediate positive, the fake negative, the real negative, and the delay positive samples at finer granularity. Specifically, we propose a two-step optimization approach that first infers the probability of fake negatives among observed negatives before applying importance sampling. To fully exploit the ground-truth immediate positives from the observed distribution, we further develop a bi-distribution modeling framework to jointly model the unbiased immediate positives and the biased delay conversions. Experimental results on both public and our industrial datasets validate the superiority of DEFUSE. Codes are available at https://github.com/ychen216/DEFUSE.git.
RPM-Oriented Query Rewriting Framework for E-commerce Keyword-Based Sponsored Search
Oct 28, 2019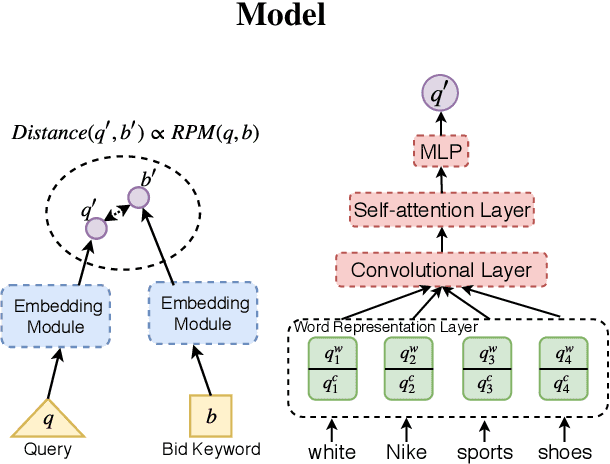
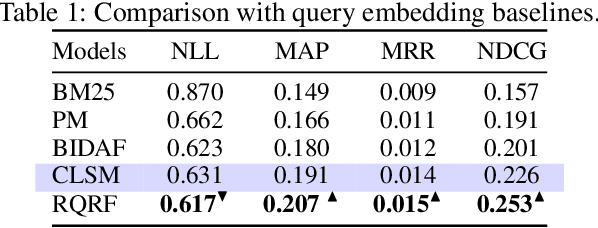

Sponsored search optimizes revenue and relevance, which is estimated by Revenue Per Mille (RPM). Existing sponsored search models are all based on traditional statistical models, which have poor RPM performance when queries follow a heavy-tailed distribution. Here, we propose an RPM-oriented Query Rewriting Framework (RQRF) which outputs related bid keywords that can yield high RPM. RQRF embeds both queries and bid keywords to vectors in the same implicit space, converting the rewriting probability between each query and keyword to the distance between the two vectors. For label construction, we propose an RPM-oriented sample construction method, labeling keywords based on whether or not they can lead to high RPM. Extensive experiments are conducted to evaluate performance of RQRF. In a one month large-scale real-world traffic of e-commerce sponsored search system, the proposed model significantly outperforms traditional baseline.
* 2 pages, 2 figures
EENMF: An End-to-End Neural Matching Framework for E-Commerce Sponsored Search
Dec 09, 2018
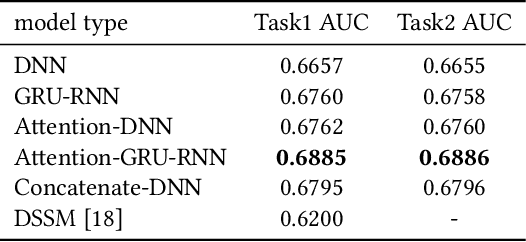
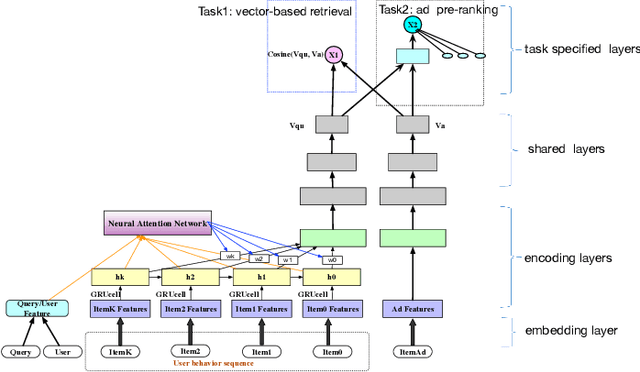
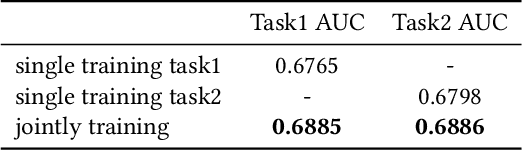
E-commerce sponsored search contributes an important part of revenue for the e-commerce company. In consideration of effectiveness and efficiency, a large-scale sponsored search system commonly adopts a multi-stage architecture. We name these stages as ad retrieval, ad pre-ranking and ad ranking. Ad retrieval and ad pre-ranking are collectively referred to as ad matching in this paper. We propose an end-to-end neural matching framework (EENMF) to model two tasks---vector-based ad retrieval and neural networks based ad pre-ranking. Under the deep matching framework, vector-based ad retrieval harnesses user recent behavior sequence to retrieve relevant ad candidates without the constraint of keyword bidding. Simultaneously, the deep model is employed to perform the global pre-ranking of ad candidates from multiple retrieval paths effectively and efficiently. Besides, the proposed model tries to optimize the pointwise cross-entropy loss which is consistent with the objective of predict models in the ranking stage. We conduct extensive evaluation to validate the performance of the proposed framework. In the real traffic of a large-scale e-commerce sponsored search, the proposed approach significantly outperforms the baseline.