 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperbolic Dual Feature Augmentation for Open-Environment
Jun 10, 2025Feature augmentation generates novel samples in the feature space, providing an effective way to enhance the generalization ability of learning algorithms with hyperbolic geometry. Most hyperbolic feature augmentation is confined to closed-environment, assuming the number of classes is fixed (\emph{i.e.}, seen classes) and generating features only for these classes. In this paper, we propose a hyperbolic dual feature augmentation method for open-environment, which augments features for both seen and unseen classes in the hyperbolic space. To obtain a more precise approximation of the real data distribution for efficient training, (1) we adopt a neural ordinary differential equation module, enhanced by meta-learning, estimating the feature distributions of both seen and unseen classes; (2) we then introduce a regularizer to preserve the latent hierarchical structures of data in the hyperbolic space; (3) we also derive an upper bound for the hyperbolic dual augmentation loss, allowing us to train a hyperbolic model using infinite augmentations for seen and unseen classes. Extensive experiments on five open-environment tasks: class-incremental learning, few-shot open-set recognition, few-shot learning, zero-shot learning, and general image classification, demonstrate that our method effectively enhances the performance of hyperbolic algorithms in open-environment.
When Large Multimodal Models Confront Evolving Knowledge:Challenges and Pathways
May 30, 2025Large language/multimodal models (LLMs/LMMs) store extensive pre-trained knowledge but struggle to maintain consistency with real-world updates, making it difficult to avoid catastrophic forgetting while acquiring evolving knowledge. Previous work focused on constructing textual knowledge datasets and exploring knowledge injection in LLMs, lacking exploration of multimodal evolving knowledge injection in LMMs. To address this, we propose the EVOKE benchmark to evaluate LMMs' ability to inject multimodal evolving knowledge in real-world scenarios. Meanwhile, a comprehensive evaluation of multimodal evolving knowledge injection revealed two challenges: (1) Existing knowledge injection methods perform terribly on evolving knowledge. (2) Supervised fine-tuning causes catastrophic forgetting, particularly instruction following ability is severely compromised. Additionally, we provide pathways and find that: (1) Text knowledge augmentation during the training phase improves performance, while image augmentation cannot achieve it. (2) Continual learning methods, especially Replay and MoELoRA, effectively mitigate forgetting. Our findings indicate that current knowledge injection methods have many limitations on evolving knowledge, which motivates further research on more efficient and stable knowledge injection methods.
VUDG: A Dataset for Video Understanding Domain Generalization
May 30, 2025Video understanding has made remarkable progress in recent years, largely driven by advances in deep models and the availability of large-scale annotated datasets. However, existing works typically ignore the inherent domain shifts encountered in real-world video applications, leaving domain generalization (DG) in video understanding underexplored. Hence, we propose Video Understanding Domain Generalization (VUDG), a novel dataset designed specifically for evaluating the DG performance in video understanding. VUDG contains videos from 11 distinct domains that cover three types of domain shifts, and maintains semantic similarity across different domains to ensure fair and meaningful evaluation. We propose a multi-expert progressive annotation framework to annotate each video with both multiple-choice and open-ended question-answer pairs. Extensive experiments on 9 representative large video-language models (LVLMs) and several traditional video question answering methods show that most models (including state-of-the-art LVLMs) suffer performance degradation under domain shifts. These results highlight the challenges posed by VUDG and the difference in the robustness of current models to data distribution shifts. We believe VUDG provides a valuable resource for prompting future research in domain generalization video understanding.
Chain-of-Focus: Adaptive Visual Search and Zooming for Multimodal Reasoning via RL
May 21, 2025



Vision language models (VLMs) have achieved impressive performance across a variety of computer vision tasks. However, the multimodal reasoning capability has not been fully explored in existing models. In this paper, we propose a Chain-of-Focus (CoF) method that allows VLMs to perform adaptive focusing and zooming in on key image regions based on obtained visual cues and the given questions, achieving efficient multimodal reasoning. To enable this CoF capability, we present a two-stage training pipeline, including supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, we construct the MM-CoF dataset, comprising 3K samples derived from a visual agent designed to adaptively identify key regions to solve visual tasks with different image resolutions and questions. We use MM-CoF to fine-tune the Qwen2.5-VL model for cold start. In the RL stage, we leverage the outcome accuracies and formats as rewards to update the Qwen2.5-VL model, enabling further refining the search and reasoning strategy of models without human priors. Our model achieves significant improvements on multiple benchmarks. On the V* benchmark that requires strong visual reasoning capability, our model outperforms existing VLMs by 5% among 8 image resolutions ranging from 224 to 4K, demonstrating the effectiveness of the proposed CoF method and facilitating the more efficient deployment of VLMs in practical applications.
Memory-Centric Embodied Question Answer
May 20, 2025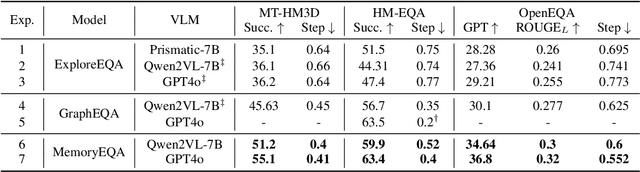
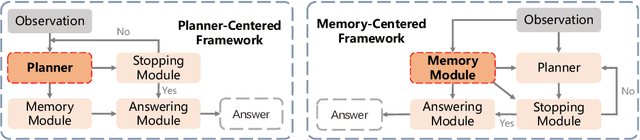
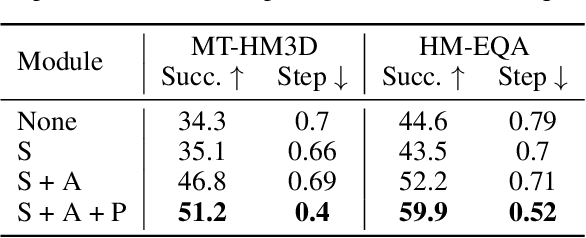
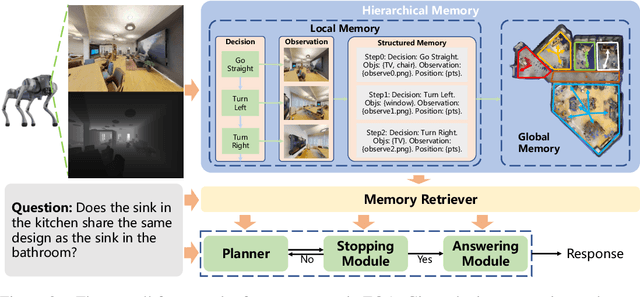
Embodied Question Answering (EQA) requires agents to autonomously explore and understand the environment to answer context-dependent questions. Existing frameworks typically center around the planner, which guides the stopping module, memory module, and answering module for reasoning. In this paper, we propose a memory-centric EQA framework named MemoryEQA. Unlike planner-centric EQA models where the memory module cannot fully interact with other modules, MemoryEQA flexible feeds memory information into all modules, thereby enhancing efficiency and accuracy in handling complex tasks, such as those involving multiple targets across different regions. Specifically, we establish a multi-modal hierarchical memory mechanism, which is divided into global memory that stores language-enhanced scene maps, and local memory that retains historical observations and state information. When performing EQA tasks, the multi-modal large language model is leveraged to convert memory information into the required input formats for injection into different modules. To evaluate EQA models' memory capabilities, we constructed the MT-HM3D dataset based on HM3D, comprising 1,587 question-answer pairs involving multiple targets across various regions, which requires agents to maintain memory of exploration-acquired target information. Experimental results on HM-EQA, MT-HM3D, and OpenEQA demonstrate the effectiveness of our framework, where a 19.8% performance gain on MT-HM3D compared to baseline model further underscores memory capability's pivotal role in resolving complex tasks.
Iterative Tool Usage Exploration for Multimodal Agents via Step-wise Preference Tuning
May 06, 2025Multimodal agents, which integrate a controller (e.g., a large language model) with external tools, have demonstrated remarkable capabilities in tackling complex tasks. However, existing agents need to collect a large number of expert data for fine-tuning to adapt to new environments. In this paper, we propose an online self-exploration method for multimodal agents, namely SPORT, via step-wise preference optimization to refine the trajectories of agents, which automatically generates tasks and learns from solving the generated tasks, without any expert annotation. SPORT operates through four iterative components: task synthesis, step sampling, step verification, and preference tuning. First, we synthesize multi-modal tasks using language models. Then, we introduce a novel search scheme, where step sampling and step verification are executed alternately to solve each generated task. We employ a verifier to provide AI feedback to construct step-wise preference data. The data is subsequently used to update the controller's policy through preference tuning, producing a SPORT Agent. By interacting with real environments, the SPORT Agent evolves into a more refined and capable system. Evaluation in the GTA and GAIA benchmarks show that the SPORT Agent achieves 6.41\% and 3.64\% improvements, underscoring the generalization and effectiveness introduced by our method. The project page is https://SPORT-Agents.github.io.
Iterative Trajectory Exploration for Multimodal Agents
Apr 30, 2025Multimodal agents, which integrate a controller (e.g., a large language model) with external tools, have demonstrated remarkable capabilities in tackling complex tasks. However, existing agents need to collect a large number of expert data for fine-tuning to adapt to new environments. In this paper, we propose an online self-exploration method for multimodal agents, namely SPORT, via step-wise preference optimization to refine the trajectories of agents, which automatically generates tasks and learns from solving the generated tasks, without any expert annotation. SPORT operates through four iterative components: task synthesis, step sampling, step verification, and preference tuning. First, we synthesize multi-modal tasks using language models. Then, we introduce a novel search scheme, where step sampling and step verification are executed alternately to solve each generated task. We employ a verifier to provide AI feedback to construct step-wise preference data. The data is subsequently used to update the controller's policy through preference tuning, producing a SPORT Agent. By interacting with real environments, the SPORT Agent evolves into a more refined and capable system. Evaluation in the GTA and GAIA benchmarks show that the SPORT Agent achieves 6.41\% and 3.64\% improvements, underscoring the generalization and effectiveness introduced by our method. The project page is https://SPORT-Agents.github.io.
TongUI: Building Generalized GUI Agents by Learning from Multimodal Web Tutorials
Apr 17, 2025Building Graphical User Interface (GUI) agents is a promising research direction, which simulates human interaction with computers or mobile phones to perform diverse GUI tasks. However, a major challenge in developing generalized GUI agents is the lack of sufficient trajectory data across various operating systems and applications, mainly due to the high cost of manual annotations. In this paper, we propose the TongUI framework that builds generalized GUI agents by learning from rich multimodal web tutorials. Concretely, we crawl and process online GUI tutorials (such as videos and articles) into GUI agent trajectory data, through which we produce the GUI-Net dataset containing 143K trajectory data across five operating systems and more than 200 applications. We develop the TongUI agent by fine-tuning Qwen2.5-VL-3B/7B models on GUI-Net, which show remarkable performance improvements on commonly used grounding and navigation benchmarks, outperforming baseline agents about 10\% on multiple benchmarks, showing the effectiveness of the GUI-Net dataset and underscoring the significance of our TongUI framework. We will fully open-source the code, the GUI-Net dataset, and the trained models soon.
Building LLM Agents by Incorporating Insights from Computer Systems
Apr 06, 2025LLM-driven autonomous agents have emerged as a promising direction in recent years. However, many of these LLM agents are designed empirically or based on intuition, often lacking systematic design principles, which results in diverse agent structures with limited generality and scalability. In this paper, we advocate for building LLM agents by incorporating insights from computer systems. Inspired by the von Neumann architecture, we propose a structured framework for LLM agentic systems, emphasizing modular design and universal principles. Specifically, this paper first provides a comprehensive review of LLM agents from the computer system perspective, then identifies key challenges and future directions inspired by computer system design, and finally explores the learning mechanisms for LLM agents beyond the computer system. The insights gained from this comparative analysis offer a foundation for systematic LLM agent design and advancement.
MMKE-Bench: A Multimodal Editing Benchmark for Diverse Visual Knowledge
Feb 27, 2025



Knowledge editing techniques have emerged as essential tools for updating the factual knowledge of large language models (LLMs) and multimodal models (LMMs), allowing them to correct outdated or inaccurate information without retraining from scratch. However, existing benchmarks for multimodal knowledge editing primarily focus on entity-level knowledge represented as simple triplets, which fail to capture the complexity of real-world multimodal information. To address this issue, we introduce MMKE-Bench, a comprehensive MultiModal Knowledge Editing Benchmark, designed to evaluate the ability of LMMs to edit diverse visual knowledge in real-world scenarios. MMKE-Bench addresses these limitations by incorporating three types of editing tasks: visual entity editing, visual semantic editing, and user-specific editing. Besides, MMKE-Bench uses free-form natural language to represent and edit knowledge, offering a more flexible and effective format. The benchmark consists of 2,940 pieces of knowledge and 8,363 images across 33 broad categories, with evaluation questions automatically generated and human-verified. We assess five state-of-the-art knowledge editing methods on three prominent LMMs, revealing that no method excels across all criteria, and that visual and user-specific edits are particularly challenging. MMKE-Bench sets a new standard for evaluating the robustness of multimodal knowledge editing techniques, driving progress in this rapidly evolving field.