 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDB-3DME: From Dataset to Benchmark for Human-aligned Automatic 3D Mesh Evaluation
Jun 08, 2026Recent advances in 3D generation have led to substantial improvements in realism, controllability, and efficiency, yet the evaluation of 3D assets remains underexplored. Existing evaluation paradigms, including human evaluation, learned metrics, and vision-language models (VLMs) as judges, suffer from limitations in cost, scalability, resolution handling, or task-specific alignment. In this work, we focus on 3D mesh evaluation and introduce DB-3DME, the Dataset and Benchmark for 3D Mesh Evaluation. DB-3DME contains 2,619 synthetic 3D meshes paired with human ratings on Geometry and Prompt Adherence. Using this dataset, we systematically benchmark state-of-the-art VLMs and identify visual encoding of 3D representations as a key factor for human-aligned evaluation performance. Motivated by this finding, we fine-tune an open-weight VLM, Qwen-2.5-VL-7B, for 3D mesh evaluation by adapting the visual encoder while freezing the language model. The fine-tuned model substantially outperforms existing pre-trained VLMs across multiple evaluation dimensions, establishing a new benchmark for automatic 3D mesh evaluation. We publicly release the benchmark dataset on GitHub and Hugging Face to facilitate future research.
SIMPLE: Simulation-Based Policy Learning and Evaluation for Humanoid Loco-manipulation
Jun 06, 2026Humanoid foundation models are advancing faster than we can evaluate them. While real-world testing is expensive and difficult to reproduce, existing simulation benchmarks focus primarily on table-top or wheeled robots. A scalable and reproducible benchmark for whole-body humanoid loco-manipulation remains an open problem. To this end, we present SIMPLE, a unified simulation testbed for humanoid policy learning and evaluation. SIMPLE couples the accurate contact-rich dynamics of MuJoCo with the photorealistic rendering of IsaacSim. It provides a large-scale environment comprising 60 diverse whole-body tasks, 50 indoor scenes, and over 1,000 object assets. To facilitate scalable data collection, the framework integrates two data generation pipelines: automated trajectory generation via motion planning and a low-latency VR teleoperation interface. We further integrate and benchmark mainstream humanoid policies at scale in SIMPLE, including lightweight imitation networks, large vision-language-action (VLA) models, and recent world action models (WAMs). Our experiments reveal a strong correlation between policy performance in simulation and the real world. Furthermore, we demonstrate that policies trained on data collected in SIMPLE can be transferred zero-shot to physical humanoid robots under similar settings, providing a robust and reproducible foundation for humanoid robotics research.
The Price of Agreement: Measuring LLM Sycophancy in Agentic Financial Applications
Apr 27, 2026Given the increased use of LLMs in financial systems today, it becomes important to evaluate the safety and robustness of such systems. One failure mode that LLMs frequently display in general domain settings is that of sycophancy. That is, models prioritize agreement with expressed user beliefs over correctness, leading to decreased accuracy and trust. In this work, we focus on evaluating sycophancy that LLMs display in agentic financial tasks. Our findings are three-fold: first, we find the models show only low to modest drops in performance in the face of user rebuttals or contradictions to the reference answer, which distinguishes sycophancy that models display in financial agentic settings from findings in prior work. Second, we introduce a suite of tasks to test for sycophancy by user preference information that contradicts the reference answer and find that most models fail in the presence of such inputs. Lastly, we benchmark different modes of recovery such as input filtering with a pretrained LLM.
NTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
$Ψ_0$: An Open Foundation Model Towards Universal Humanoid Loco-Manipulation
Mar 12, 2026We introduce $Ψ_0$ (Psi-Zero), an open foundation model to address challenging humanoid loco-manipulation tasks. While existing approaches often attempt to address this fundamental problem by co-training on large and diverse human and humanoid data, we argue that this strategy is suboptimal due to the fundamental kinematic and motion disparities between humans and humanoid robots. Therefore, data efficiency and model performance remain unsatisfactory despite the considerable data volume. To address this challenge, \ours\;decouples the learning process to maximize the utility of heterogeneous data sources. Specifically, we propose a staged training paradigm with different learning objectives: First, we autoregressively pre-train a VLM backbone on large-scale egocentric human videos to acquire generalizable visual-action representations. Then, we post-train a flow-based action expert on high-quality humanoid robot data to learn precise robot joint control. Our research further identifies a critical yet often overlooked data recipe: in contrast to approaches that scale with noisy Internet clips or heterogeneous cross-embodiment robot datasets, we demonstrate that pre-training on high-quality egocentric human manipulation data followed by post-training on domain-specific real-world humanoid trajectories yields superior performance. Extensive real-world experiments demonstrate that \ours\ achieves the best performance using only about 800 hours of human video data and 30 hours of real-world robot data, outperforming baselines pre-trained on more than 10$\times$ as much data by over 40\% in overall success rate across multiple tasks. We will open-source the entire ecosystem to the community, including a data processing and training pipeline, a humanoid foundation model, and a real-time action inference engine.
Dynamic Prior Thompson Sampling for Cold-Start Exploration in Recommender Systems
Feb 01, 2026Cold-start exploration is a core challenge in large-scale recommender systems: new or data-sparse items must receive traffic to estimate value, but over-exploration harms users and wastes impressions. In practice, Thompson Sampling (TS) is often initialized with a uniform Beta(1,1) prior, implicitly assuming a 50% success rate for unseen items. When true base rates are far lower, this optimistic prior systematically over-allocates to weak items. The impact is amplified by batched policy updates and pipeline latency: for hours, newly launched items can remain effectively "no data," so the prior dominates allocation before feedback is incorporated. We propose Dynamic Prior Thompson Sampling, a prior design that directly controls the probability that a new arm outcompetes the incumbent winner. Our key contribution is a closed-form quadratic solution for the prior mean that enforces P(X_j > Y_k) = epsilon at introduction time, making exploration intensity predictable and tunable while preserving TS Bayesian updates. Across Monte Carlo validation, offline batched simulations, and a large-scale online experiment on a thumbnail personalization system serving millions of users, dynamic priors deliver precise exploration control and improved efficiency versus a uniform-prior baseline.
CoPHo: Classifier-guided Conditional Topology Generation with Persistent Homology
Dec 17, 2025The structure of topology underpins much of the research on performance and robustness, yet available topology data are typically scarce, necessitating the generation of synthetic graphs with desired properties for testing or release. Prior diffusion-based approaches either embed conditions into the diffusion model, requiring retraining for each attribute and hindering real-time applicability, or use classifier-based guidance post-training, which does not account for topology scale and practical constraints. In this paper, we show from a discrete perspective that gradients from a pre-trained graph-level classifier can be incorporated into the discrete reverse diffusion posterior to steer generation toward specified structural properties. Based on this insight, we propose Classifier-guided Conditional Topology Generation with Persistent Homology (CoPHo), which builds a persistent homology filtration over intermediate graphs and interprets features as guidance signals that steer generation toward the desired properties at each denoising step. Experiments on four generic/network datasets demonstrate that CoPHo outperforms existing methods at matching target metrics, and we further validate its transferability on the QM9 molecular dataset.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Can LLMs Grasp Implicit Cultural Values? Benchmarking LLMs' Metacognitive Cultural Intelligence with CQ-Bench
Apr 01, 2025Cultural Intelligence (CQ) refers to the ability to understand unfamiliar cultural contexts-a crucial skill for large language models (LLMs) to effectively engage with globally diverse users. While existing research often focuses on explicitly stated cultural norms, such approaches fail to capture the subtle, implicit values that underlie real-world conversations. To address this gap, we introduce CQ-Bench, a benchmark specifically designed to assess LLMs' capability to infer implicit cultural values from natural conversational contexts. We generate a multi-character conversation-based stories dataset using values from the World Value Survey and GlobalOpinions datasets, with topics including ethical, religious, social, and political. Our dataset construction pipeline includes rigorous validation procedures-incorporation, consistency, and implicitness checks-using GPT-4o, with 98.2% human-model agreement in the final validation. Our benchmark consists of three tasks of increasing complexity: attitude detection, value selection, and value extraction. We find that while o1 and Deepseek-R1 models reach human-level performance in value selection (0.809 and 0.814), they still fall short in nuanced attitude detection, with F1 scores of 0.622 and 0.635, respectively. In the value extraction task, GPT-4o-mini and o3-mini score 0.602 and 0.598, highlighting the difficulty of open-ended cultural reasoning. Notably, fine-tuning smaller models (e.g., LLaMA-3.2-3B) on only 500 culturally rich examples improves performance by over 10%, even outperforming stronger baselines (o3-mini) in some cases. Using CQ-Bench, we provide insights into the current challenges in LLMs' CQ research and suggest practical pathways for enhancing LLMs' cross-cultural reasoning abilities.
LEDiT: Your Length-Extrapolatable Diffusion Transformer without Positional Encoding
Mar 07, 2025

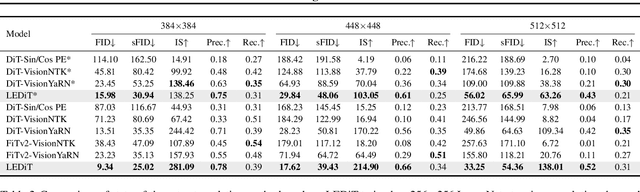

Diffusion transformers(DiTs) struggle to generate images at resolutions higher than their training resolutions. The primary obstacle is that the explicit positional encodings(PE), such as RoPE, need extrapolation which degrades performance when the inference resolution differs from training. In this paper, we propose a Length-Extrapolatable Diffusion Transformer(LEDiT), a simple yet powerful architecture to overcome this limitation. LEDiT needs no explicit PEs, thereby avoiding extrapolation. The key innovations of LEDiT are introducing causal attention to implicitly impart global positional information to tokens, while enhancing locality to precisely distinguish adjacent tokens. Experiments on 256x256 and 512x512 ImageNet show that LEDiT can scale the inference resolution to 512x512 and 1024x1024, respectively, while achieving better image quality compared to current state-of-the-art length extrapolation methods(NTK-aware, YaRN). Moreover, LEDiT achieves strong extrapolation performance with just 100K steps of fine-tuning on a pretrained DiT, demonstrating its potential for integration into existing text-to-image DiTs. Project page: https://shenzhang2145.github.io/ledit/