 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIMPLE: Simulation-Based Policy Learning and Evaluation for Humanoid Loco-manipulation
Jun 06, 2026Humanoid foundation models are advancing faster than we can evaluate them. While real-world testing is expensive and difficult to reproduce, existing simulation benchmarks focus primarily on table-top or wheeled robots. A scalable and reproducible benchmark for whole-body humanoid loco-manipulation remains an open problem. To this end, we present SIMPLE, a unified simulation testbed for humanoid policy learning and evaluation. SIMPLE couples the accurate contact-rich dynamics of MuJoCo with the photorealistic rendering of IsaacSim. It provides a large-scale environment comprising 60 diverse whole-body tasks, 50 indoor scenes, and over 1,000 object assets. To facilitate scalable data collection, the framework integrates two data generation pipelines: automated trajectory generation via motion planning and a low-latency VR teleoperation interface. We further integrate and benchmark mainstream humanoid policies at scale in SIMPLE, including lightweight imitation networks, large vision-language-action (VLA) models, and recent world action models (WAMs). Our experiments reveal a strong correlation between policy performance in simulation and the real world. Furthermore, we demonstrate that policies trained on data collected in SIMPLE can be transferred zero-shot to physical humanoid robots under similar settings, providing a robust and reproducible foundation for humanoid robotics research.
$Ψ_0$: An Open Foundation Model Towards Universal Humanoid Loco-Manipulation
Mar 12, 2026We introduce $Ψ_0$ (Psi-Zero), an open foundation model to address challenging humanoid loco-manipulation tasks. While existing approaches often attempt to address this fundamental problem by co-training on large and diverse human and humanoid data, we argue that this strategy is suboptimal due to the fundamental kinematic and motion disparities between humans and humanoid robots. Therefore, data efficiency and model performance remain unsatisfactory despite the considerable data volume. To address this challenge, \ours\;decouples the learning process to maximize the utility of heterogeneous data sources. Specifically, we propose a staged training paradigm with different learning objectives: First, we autoregressively pre-train a VLM backbone on large-scale egocentric human videos to acquire generalizable visual-action representations. Then, we post-train a flow-based action expert on high-quality humanoid robot data to learn precise robot joint control. Our research further identifies a critical yet often overlooked data recipe: in contrast to approaches that scale with noisy Internet clips or heterogeneous cross-embodiment robot datasets, we demonstrate that pre-training on high-quality egocentric human manipulation data followed by post-training on domain-specific real-world humanoid trajectories yields superior performance. Extensive real-world experiments demonstrate that \ours\ achieves the best performance using only about 800 hours of human video data and 30 hours of real-world robot data, outperforming baselines pre-trained on more than 10$\times$ as much data by over 40\% in overall success rate across multiple tasks. We will open-source the entire ecosystem to the community, including a data processing and training pipeline, a humanoid foundation model, and a real-time action inference engine.
SocioVerse: A World Model for Social Simulation Powered by LLM Agents and A Pool of 10 Million Real-World Users
Apr 14, 2025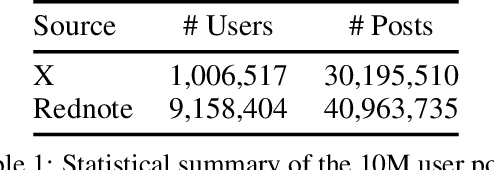
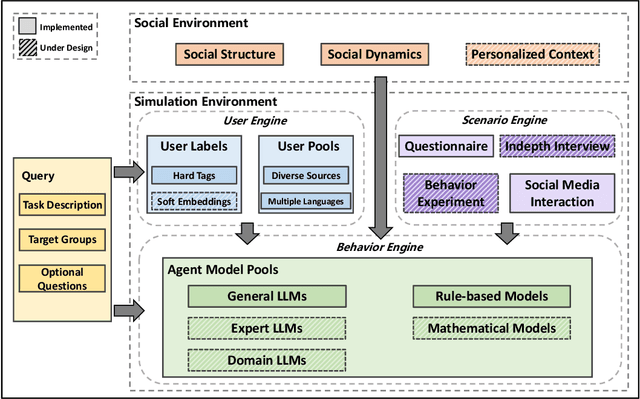

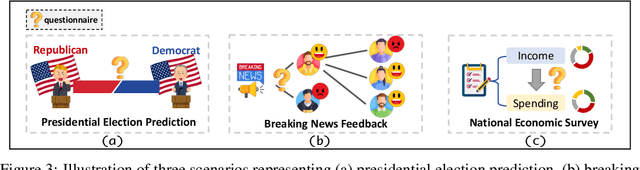
Social simulation is transforming traditional social science research by modeling human behavior through interactions between virtual individuals and their environments. With recent advances in large language models (LLMs), this approach has shown growing potential in capturing individual differences and predicting group behaviors. However, existing methods face alignment challenges related to the environment, target users, interaction mechanisms, and behavioral patterns. To this end, we introduce SocioVerse, an LLM-agent-driven world model for social simulation. Our framework features four powerful alignment components and a user pool of 10 million real individuals. To validate its effectiveness, we conducted large-scale simulation experiments across three distinct domains: politics, news, and economics. Results demonstrate that SocioVerse can reflect large-scale population dynamics while ensuring diversity, credibility, and representativeness through standardized procedures and minimal manual adjustments.
AgentSense: Benchmarking Social Intelligence of Language Agents through Interactive Scenarios
Oct 25, 2024



Large language models (LLMs) are increasingly leveraged to empower autonomous agents to simulate human beings in various fields of behavioral research. However, evaluating their capacity to navigate complex social interactions remains a challenge. Previous studies face limitations due to insufficient scenario diversity, complexity, and a single-perspective focus. To this end, we introduce AgentSense: Benchmarking Social Intelligence of Language Agents through Interactive Scenarios. Drawing on Dramaturgical Theory, AgentSense employs a bottom-up approach to create 1,225 diverse social scenarios constructed from extensive scripts. We evaluate LLM-driven agents through multi-turn interactions, emphasizing both goal completion and implicit reasoning. We analyze goals using ERG theory and conduct comprehensive experiments. Our findings highlight that LLMs struggle with goals in complex social scenarios, especially high-level growth needs, and even GPT-4o requires improvement in private information reasoning.
AI-Press: A Multi-Agent News Generating and Feedback Simulation System Powered by Large Language Models
Oct 10, 2024



The rise of various social platforms has transformed journalism. The growing demand for news content has led to the increased use of large language models (LLMs) in news production due to their speed and cost-effectiveness. However, LLMs still encounter limitations in professionalism and ethical judgment in news generation. Additionally, predicting public feedback is usually difficult before news is released. To tackle these challenges, we introduce AI-Press, an automated news drafting and polishing system based on multi-agent collaboration and Retrieval-Augmented Generation. We develop a feedback simulation system that generates public feedback considering demographic distributions. Through extensive quantitative and qualitative evaluations, our system shows significant improvements in news-generating capabilities and verifies the effectiveness of public feedback simulation.