 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIMPLE: Simulation-Based Policy Learning and Evaluation for Humanoid Loco-manipulation
Jun 06, 2026Humanoid foundation models are advancing faster than we can evaluate them. While real-world testing is expensive and difficult to reproduce, existing simulation benchmarks focus primarily on table-top or wheeled robots. A scalable and reproducible benchmark for whole-body humanoid loco-manipulation remains an open problem. To this end, we present SIMPLE, a unified simulation testbed for humanoid policy learning and evaluation. SIMPLE couples the accurate contact-rich dynamics of MuJoCo with the photorealistic rendering of IsaacSim. It provides a large-scale environment comprising 60 diverse whole-body tasks, 50 indoor scenes, and over 1,000 object assets. To facilitate scalable data collection, the framework integrates two data generation pipelines: automated trajectory generation via motion planning and a low-latency VR teleoperation interface. We further integrate and benchmark mainstream humanoid policies at scale in SIMPLE, including lightweight imitation networks, large vision-language-action (VLA) models, and recent world action models (WAMs). Our experiments reveal a strong correlation between policy performance in simulation and the real world. Furthermore, we demonstrate that policies trained on data collected in SIMPLE can be transferred zero-shot to physical humanoid robots under similar settings, providing a robust and reproducible foundation for humanoid robotics research.
HumDex:Humanoid Dexterous Manipulation Made Easy
Mar 12, 2026This paper investigates humanoid whole-body dexterous manipulation, where the efficient collection of high-quality demonstration data remains a central bottleneck. Existing teleoperation systems often suffer from limited portability, occlusion, or insufficient precision, which hinders their applicability to complex whole-body tasks. To address these challenges, we introduce HumDex, a portable teleoperation system designed for humanoid whole-body dexterous manipulation. Our system leverages IMU-based motion tracking to address the portability-precision trade-off, enabling accurate full-body tracking while remaining easy to deploy. For dexterous hand control, we further introduce a learning-based retargeting method that generates smooth and natural hand motions without manual parameter tuning. Beyond teleoperation, HumDex enables efficient collection of human motion data. Building on this capability, we propose a two-stage imitation learning framework that first pre-trains on diverse human motion data to learn generalizable priors, and then fine-tunes on robot data to bridge the embodiment gap for precise execution. We demonstrate that this approach significantly improves generalization to new configurations, objects, and backgrounds with minimal data acquisition costs. The entire system is fully reproducible and open-sourced at https://github.com/physical-superintelligence-lab/HumDex.
CrayonRobo: Object-Centric Prompt-Driven Vision-Language-Action Model for Robotic Manipulation
May 04, 2025In robotic, task goals can be conveyed through various modalities, such as language, goal images, and goal videos. However, natural language can be ambiguous, while images or videos may offer overly detailed specifications. To tackle these challenges, we introduce CrayonRobo that leverages comprehensive multi-modal prompts that explicitly convey both low-level actions and high-level planning in a simple manner. Specifically, for each key-frame in the task sequence, our method allows for manual or automatic generation of simple and expressive 2D visual prompts overlaid on RGB images. These prompts represent the required task goals, such as the end-effector pose and the desired movement direction after contact. We develop a training strategy that enables the model to interpret these visual-language prompts and predict the corresponding contact poses and movement directions in SE(3) space. Furthermore, by sequentially executing all key-frame steps, the model can complete long-horizon tasks. This approach not only helps the model explicitly understand the task objectives but also enhances its robustness on unseen tasks by providing easily interpretable prompts. We evaluate our method in both simulated and real-world environments, demonstrating its robust manipulation capabilities.
3DWG: 3D Weakly Supervised Visual Grounding via Category and Instance-Level Alignment
May 03, 2025The 3D weakly-supervised visual grounding task aims to localize oriented 3D boxes in point clouds based on natural language descriptions without requiring annotations to guide model learning. This setting presents two primary challenges: category-level ambiguity and instance-level complexity. Category-level ambiguity arises from representing objects of fine-grained categories in a highly sparse point cloud format, making category distinction challenging. Instance-level complexity stems from multiple instances of the same category coexisting in a scene, leading to distractions during grounding. To address these challenges, we propose a novel weakly-supervised grounding approach that explicitly differentiates between categories and instances. In the category-level branch, we utilize extensive category knowledge from a pre-trained external detector to align object proposal features with sentence-level category features, thereby enhancing category awareness. In the instance-level branch, we utilize spatial relationship descriptions from language queries to refine object proposal features, ensuring clear differentiation among objects. These designs enable our model to accurately identify target-category objects while distinguishing instances within the same category. Compared to previous methods, our approach achieves state-of-the-art performance on three widely used benchmarks: Nr3D, Sr3D, and ScanRef.
MoLe-VLA: Dynamic Layer-skipping Vision Language Action Model via Mixture-of-Layers for Efficient Robot Manipulation
Mar 26, 2025Multimodal Large Language Models (MLLMs) excel in understanding complex language and visual data, enabling generalist robotic systems to interpret instructions and perform embodied tasks. Nevertheless, their real-world deployment is hindered by substantial computational and storage demands. Recent insights into the homogeneous patterns in the LLM layer have inspired sparsification techniques to address these challenges, such as early exit and token pruning. However, these methods often neglect the critical role of the final layers that encode the semantic information most relevant to downstream robotic tasks. Aligning with the recent breakthrough of the Shallow Brain Hypothesis (SBH) in neuroscience and the mixture of experts in model sparsification, we conceptualize each LLM layer as an expert and propose a Mixture-of-Layers Vision-Language-Action model (MoLe-VLA, or simply MoLe) architecture for dynamic LLM layer activation. We introduce a Spatial-Temporal Aware Router (STAR) for MoLe to selectively activate only parts of the layers based on the robot's current state, mimicking the brain's distinct signal pathways specialized for cognition and causal reasoning. Additionally, to compensate for the cognitive ability of LLMs lost in MoLe, we devise a Cognition Self-Knowledge Distillation (CogKD) framework. CogKD enhances the understanding of task demands and improves the generation of task-relevant action sequences by leveraging cognitive features. Extensive experiments conducted in both RLBench simulation and real-world environments demonstrate the superiority of MoLe-VLA in both efficiency and performance. Specifically, MoLe-VLA achieves an 8% improvement in the mean success rate across ten tasks while reducing computational costs by up to x5.6 compared to standard LLMs.
Graph-Guided Deformation for Point Cloud Completion
Nov 11, 2021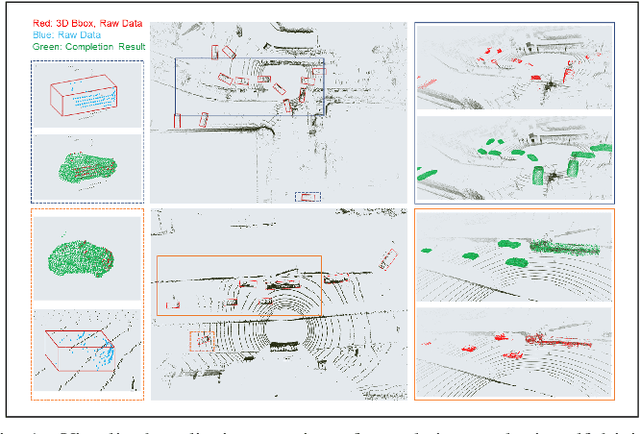
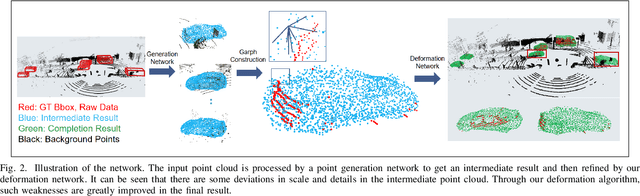
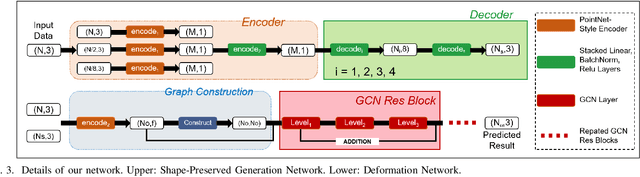

For a long time, the point cloud completion task has been regarded as a pure generation task. After obtaining the global shape code through the encoder, a complete point cloud is generated using the shape priorly learnt by the networks. However, such models are undesirably biased towards prior average objects and inherently limited to fit geometry details. In this paper, we propose a Graph-Guided Deformation Network, which respectively regards the input data and intermediate generation as controlling and supporting points, and models the optimization guided by a graph convolutional network(GCN) for the point cloud completion task. Our key insight is to simulate the least square Laplacian deformation process via mesh deformation methods, which brings adaptivity for modeling variation in geometry details. By this means, we also reduce the gap between the completion task and the mesh deformation algorithms. As far as we know, we are the first to refine the point cloud completion task by mimicing traditional graphics algorithms with GCN-guided deformation. We have conducted extensive experiments on both the simulated indoor dataset ShapeNet, outdoor dataset KITTI, and our self-collected autonomous driving dataset Pandar40. The results show that our method outperforms the existing state-of-the-art algorithms in the 3D point cloud completion task.