 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-based Visual Deformation Measurement
Feb 16, 2026Visual Deformation Measurement (VDM) aims to recover dense deformation fields by tracking surface motion from camera observations. Traditional image-based methods rely on minimal inter-frame motion to constrain the correspondence search space, which limits their applicability to highly dynamic scenes or necessitates high-speed cameras at the cost of prohibitive storage and computational overhead. We propose an event-frame fusion framework that exploits events for temporally dense motion cues and frames for spatially dense precise estimation. Revisiting the solid elastic modeling prior, we propose an Affine Invariant Simplicial (AIS) framework. It partitions the deformation field into linearized sub-regions with low-parametric representation, effectively mitigating motion ambiguities arising from sparse and noisy events. To speed up parameter searching and reduce error accumulation, a neighborhood-greedy optimization strategy is introduced, enabling well-converged sub-regions to guide their poorly-converged neighbors, effectively suppress local error accumulation in long-term dense tracking. To evaluate the proposed method, a benchmark dataset with temporally aligned event streams and frames is established, encompassing over 120 sequences spanning diverse deformation scenarios. Experimental results show that our method outperforms the state-of-the-art baseline by 1.6% in survival rate. Remarkably, it achieves this using only 18.9% of the data storage and processing resources of high-speed video methods.
Unbiased Gradient Estimation for Event Binning via Functional Backpropagation
Feb 13, 2026Event-based vision encodes dynamic scenes as asynchronous spatio-temporal spikes called events. To leverage conventional image processing pipelines, events are typically binned into frames. However, binning functions are discontinuous, which truncates gradients at the frame level and forces most event-based algorithms to rely solely on frame-based features. Attempts to directly learn from raw events avoid this restriction but instead suffer from biased gradient estimation due to the discontinuities of the binning operation, ultimately limiting their learning efficiency. To address this challenge, we propose a novel framework for unbiased gradient estimation of arbitrary binning functions by synthesizing weak derivatives during backpropagation while keeping the forward output unchanged. The key idea is to exploit integration by parts: lifting the target functions to functionals yields an integral form of the derivative of the binning function during backpropagation, where the cotangent function naturally arises. By reconstructing this cotangent function from the sampled cotangent vector, we compute weak derivatives that provably match long-range finite differences of both smooth and non-smooth targets. Experimentally, our method improves simple optimization-based egomotion estimation with 3.2\% lower RMS error and 1.57$\times$ faster convergence. On complex downstream tasks, we achieve 9.4\% lower EPE in self-supervised optical flow, and 5.1\% lower RMS error in SLAM, demonstrating broad benefits for event-based visual perception. Source code can be found at https://github.com/chjz1024/EventFBP.
Bidirectional Reward-Guided Diffusion for Real-World Image Super-Resolution
Feb 05, 2026Diffusion-based super-resolution can synthesize rich details, but models trained on synthetic paired data often fail on real-world LR images due to distribution shifts. We propose Bird-SR, a bidirectional reward-guided diffusion framework that formulates super-resolution as trajectory-level preference optimization via reward feedback learning (ReFL), jointly leveraging synthetic LR-HR pairs and real-world LR images. For structural fidelity easily affected in ReFL, the model is directly optimized on synthetic pairs at early diffusion steps, which also facilitates structure preservation for real-world inputs under smaller distribution gap in structure levels. For perceptual enhancement, quality-guided rewards are applied at later sampling steps to both synthetic and real LR images. To mitigate reward hacking, the rewards for synthetic results are formulated in a relative advantage space bounded by their clean counterparts, while real-world optimization is regularized via a semantic alignment constraint. Furthermore, to balance structural and perceptual learning, we adopt a dynamic fidelity-perception weighting strategy that emphasizes structure preservation at early stages and progressively shifts focus toward perceptual optimization at later diffusion steps. Extensive experiments on real-world SR benchmarks demonstrate that Bird-SR consistently outperforms state-of-the-art methods in perceptual quality while preserving structural consistency, validating its effectiveness for real-world super-resolution.
ArenaRL: Scaling RL for Open-Ended Agents via Tournament-based Relative Ranking
Jan 10, 2026Reinforcement learning has substantially improved the performance of LLM agents on tasks with verifiable outcomes, but it still struggles on open-ended agent tasks with vast solution spaces (e.g., complex travel planning). Due to the absence of objective ground-truth for these tasks, current RL algorithms largely rely on reward models that assign scalar scores to individual responses. We contend that such pointwise scoring suffers from an inherent discrimination collapse: the reward model struggles to distinguish subtle advantages among different trajectories, resulting in scores within a group being compressed into a narrow range. Consequently, the effective reward signal becomes dominated by noise from the reward model, leading to optimization stagnation. To address this, we propose ArenaRL, a reinforcement learning paradigm that shifts from pointwise scalar scoring to intra-group relative ranking. ArenaRL introduces a process-aware pairwise evaluation mechanism, employing multi-level rubrics to assign fine-grained relative scores to trajectories. Additionally, we construct an intra-group adversarial arena and devise a tournament-based ranking scheme to obtain stable advantage signals. Empirical results confirm that the built seeded single-elimination scheme achieves nearly equivalent advantage estimation accuracy to full pairwise comparisons with O(N^2) complexity, while operating with only O(N) complexity, striking an optimal balance between efficiency and precision. Furthermore, to address the lack of full-cycle benchmarks for open-ended agents, we build Open-Travel and Open-DeepResearch, two high-quality benchmarks featuring a comprehensive pipeline covering SFT, RL training, and multi-dimensional evaluation. Extensive experiments show that ArenaRL substantially outperforms standard RL baselines, enabling LLM agents to generate more robust solutions for complex real-world tasks.
OmniVaT: Single Domain Generalization for Multimodal Visual-Tactile Learning
Jan 01, 2026Visual-tactile learning (VTL) enables embodied agents to perceive the physical world by integrating visual (VIS) and tactile (TAC) sensors. However, VTL still suffers from modality discrepancies between VIS and TAC images, as well as domain gaps caused by non-standardized tactile sensors and inconsistent data collection procedures. We formulate these challenges as a new task, termed single domain generalization for multimodal VTL (SDG-VTL). In this paper, we propose an OmniVaT framework that, for the first time, successfully addresses this task. On the one hand, OmniVaT integrates a multimodal fractional Fourier adapter (MFFA) to map VIS and TAC embeddings into a unified embedding-frequency space, thereby effectively mitigating the modality gap without multi-domain training data or careful cross-modal fusion strategies. On the other hand, it also incorporates a discrete tree generation (DTG) module that obtains diverse and reliable multimodal fractional representations through a hierarchical tree structure, thereby enhancing its adaptivity to fluctuating domain shifts in unseen domains. Extensive experiments demonstrate the superior cross-domain generalization performance of OmniVaT on the SDG-VTL task.
FinPercep-RM: A Fine-grained Reward Model and Co-evolutionary Curriculum for RL-based Real-world Super-Resolution
Dec 27, 2025Reinforcement Learning with Human Feedback (RLHF) has proven effective in image generation field guided by reward models to align human preferences. Motivated by this, adapting RLHF for Image Super-Resolution (ISR) tasks has shown promise in optimizing perceptual quality with Image Quality Assessment (IQA) model as reward models. However, the traditional IQA model usually output a single global score, which are exceptionally insensitive to local and fine-grained distortions. This insensitivity allows ISR models to produce perceptually undesirable artifacts that yield spurious high scores, misaligning optimization objectives with perceptual quality and results in reward hacking. To address this, we propose a Fine-grained Perceptual Reward Model (FinPercep-RM) based on an Encoder-Decoder architecture. While providing a global quality score, it also generates a Perceptual Degradation Map that spatially localizes and quantifies local defects. We specifically introduce the FGR-30k dataset to train this model, consisting of diverse and subtle distortions from real-world super-resolution models. Despite the success of the FinPercep-RM model, its complexity introduces significant challenges in generator policy learning, leading to training instability. To address this, we propose a Co-evolutionary Curriculum Learning (CCL) mechanism, where both the reward model and the ISR model undergo synchronized curricula. The reward model progressively increases in complexity, while the ISR model starts with a simpler global reward for rapid convergence, gradually transitioning to the more complex model outputs. This easy-to-hard strategy enables stable training while suppressing reward hacking. Experiments validates the effectiveness of our method across ISR models in both global quality and local realism on RLHF methods.
Anchoring Values in Temporal and Group Dimensions for Flow Matching Model Alignment
Dec 13, 2025Group Relative Policy Optimization (GRPO) has proven highly effective in enhancing the alignment capabilities of Large Language Models (LLMs). However, current adaptations of GRPO for the flow matching-based image generation neglect a foundational conflict between its core principles and the distinct dynamics of the visual synthesis process. This mismatch leads to two key limitations: (i) Uniformly applying a sparse terminal reward across all timesteps impairs temporal credit assignment, ignoring the differing criticality of generation phases from early structure formation to late-stage tuning. (ii) Exclusive reliance on relative, intra-group rewards causes the optimization signal to fade as training converges, leading to the optimization stagnation when reward diversity is entirely depleted. To address these limitations, we propose Value-Anchored Group Policy Optimization (VGPO), a framework that redefines value estimation across both temporal and group dimensions. Specifically, VGPO transforms the sparse terminal reward into dense, process-aware value estimates, enabling precise credit assignment by modeling the expected cumulative reward at each generative stage. Furthermore, VGPO replaces standard group normalization with a novel process enhanced by absolute values to maintain a stable optimization signal even as reward diversity declines. Extensive experiments on three benchmarks demonstrate that VGPO achieves state-of-the-art image quality while simultaneously improving task-specific accuracy, effectively mitigating reward hacking. Project webpage: https://yawen-shao.github.io/VGPO/.
Beyond Randomness: Understand the Order of the Noise in Diffusion
Nov 11, 2025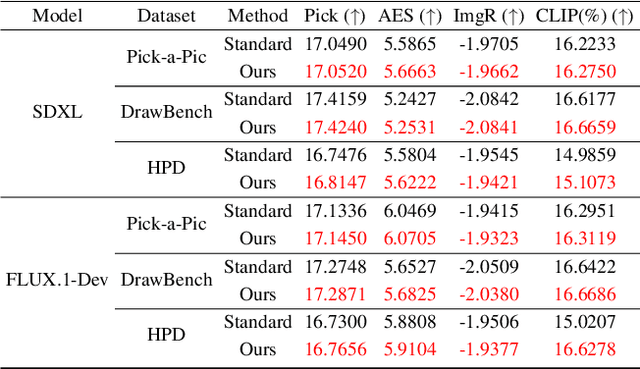


In text-driven content generation (T2C) diffusion model, semantic of generated content is mostly attributed to the process of text embedding and attention mechanism interaction. The initial noise of the generation process is typically characterized as a random element that contributes to the diversity of the generated content. Contrary to this view, this paper reveals that beneath the random surface of noise lies strong analyzable patterns. Specifically, this paper first conducts a comprehensive analysis of the impact of random noise on the model's generation. We found that noise not only contains rich semantic information, but also allows for the erasure of unwanted semantics from it in an extremely simple way based on information theory, and using the equivalence between the generation process of diffusion model and semantic injection to inject semantics into the cleaned noise. Then, we mathematically decipher these observations and propose a simple but efficient training-free and universal two-step "Semantic Erasure-Injection" process to modulate the initial noise in T2C diffusion model. Experimental results demonstrate that our method is consistently effective across various T2C models based on both DiT and UNet architectures and presents a novel perspective for optimizing the generation of diffusion model, providing a universal tool for consistent generation.
Latent Harmony: Synergistic Unified UHD Image Restoration via Latent Space Regularization and Controllable Refinement
Oct 09, 2025



Ultra-High Definition (UHD) image restoration faces a trade-off between computational efficiency and high-frequency detail retention. While Variational Autoencoders (VAEs) improve efficiency via latent-space processing, their Gaussian constraint often discards degradation-specific high-frequency information, hurting reconstruction fidelity. To overcome this, we propose Latent Harmony, a two-stage framework that redefines VAEs for UHD restoration by jointly regularizing the latent space and enforcing high-frequency-aware reconstruction.In Stage One, we introduce LH-VAE, which enhances semantic robustness through visual semantic constraints and progressive degradation perturbations, while latent equivariance strengthens high-frequency reconstruction.Stage Two jointly trains this refined VAE with a restoration model using High-Frequency Low-Rank Adaptation (HF-LoRA): an encoder LoRA guided by a fidelity-oriented high-frequency alignment loss to recover authentic details, and a decoder LoRA driven by a perception-oriented loss to synthesize realistic textures. Both LoRA modules are trained via alternating optimization with selective gradient propagation to preserve the pretrained latent structure.At inference, a tunable parameter {\alpha} enables flexible fidelity-perception trade-offs.Experiments show Latent Harmony achieves state-of-the-art performance across UHD and standard-resolution tasks, effectively balancing efficiency, perceptual quality, and reconstruction accuracy.
Fractional Spike Differential Equations Neural Network with Efficient Adjoint Parameters Training
Jul 22, 2025Spiking Neural Networks (SNNs) draw inspiration from biological neurons to create realistic models for brain-like computation, demonstrating effectiveness in processing temporal information with energy efficiency and biological realism. Most existing SNNs assume a single time constant for neuronal membrane voltage dynamics, modeled by first-order ordinary differential equations (ODEs) with Markovian characteristics. Consequently, the voltage state at any time depends solely on its immediate past value, potentially limiting network expressiveness. Real neurons, however, exhibit complex dynamics influenced by long-term correlations and fractal dendritic structures, suggesting non-Markovian behavior. Motivated by this, we propose the Fractional SPIKE Differential Equation neural network (fspikeDE), which captures long-term dependencies in membrane voltage and spike trains through fractional-order dynamics. These fractional dynamics enable more expressive temporal patterns beyond the capability of integer-order models. For efficient training of fspikeDE, we introduce a gradient descent algorithm that optimizes parameters by solving an augmented fractional-order ODE (FDE) backward in time using adjoint sensitivity methods. Extensive experiments on diverse image and graph datasets demonstrate that fspikeDE consistently outperforms traditional SNNs, achieving superior accuracy, comparable energy efficiency, reduced training memory usage, and enhanced robustness against noise. Our approach provides a novel open-sourced computational toolbox for fractional-order SNNs, widely applicable to various real-world tasks.