 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward User Preference Alignment in LLM Recommendation via Explicit Context Feedback
May 27, 2026Traditional recommender systems (RecSys) primarily infer user preferences from implicit signals (such as clicks, watches, and purchases), often neglecting the rich explicit contextual feedback users provide through verbal text, like comments and reviews. This explicit context feedback captures the nuanced reasons behind user decisions regarding their preferences. In addition, it offers critical heterogeneous information for user preference alignment and more explainable recommendations. Overlooking such signals can lead to misaligned user preferences and further reinforce filter bubbles, as algorithms fail to understand the "semantic context" behind user choices. Recent advances in Large Language Models (LLMs) present new opportunities to harness user-generated content for more accurate and diverse recommendations, yet current LLM-based recommendations still focus on using item meta-data and underutilize this resource. In this paper, we advocate for prioritizing explicit context feedback in the next generation of LLM-based RecSys. We review the evolution of recommendation paradigms, highlight the value of context-rich feedback, call for new benchmarks and metrics, and introduce frameworks for integrating explicit user signals into scalable LLM-driven RecSys. Centering on user-preference modeling, we aim to foster more personalized, transparent, and explainable RecSys online platforms.
PCodeTrans: Translate Decompiled Pseudocode to Compilable and Executable Equivalent
Mar 16, 2026Decompilation is foundational to binary analysis, yet conventional tools prioritize human readability over strict recompilability and verifiable runtime correctness. While recent LLM-based approaches attempt to refine decompiled pseudocode, they typically either optimize solely for readability or rely on static analysis for evaluation. This makes them prone to "semantic hallucinations" that compromise accuracy and fail to resolve actual runtime failures. For critical tasks like software modernization and vulnerability remediation, recovered code must not only compile but replicate the original binary's behavior. We present PCodeTrans, a feedback-driven framework that bridges the gap between decompilation, recompilation, and rigorous function-level dynamic validation. After extracting a minimal yet coherent context to guarantee recompilability, PCodeTrans employs an in situ substitutable engine to hot-swap the compiled function directly into the unmodified binary, natively preserving its authentic execution context and global dependencies. Guided by fine-grained differential tracing, PCodeTrans generates precise runtime feedback to iteratively guide an LLM in repairing semantic discrepancies. Evaluated on Coreutils and Binutils, PCodeTrans achieves unprecedented recovery performance when rectifying raw Hex-Rays outputs, attaining 100% function-level compilability on unstripped binaries alongside 99.55% and 99.89% test-validated behavioral consistency, respectively. In doing so, it resolves 76.56% and 79.74% of logic errors exposed by official test suites. Exhibiting exceptional resilience, PCodeTrans maintains over 96% behavioral consistency even on fully stripped binaries. By significantly outperforming all existing baselines, PCodeTrans paves a practical path to reliably translate decompiled pseudocode into compilable and executable equivalents.
SecCodeBench-V2 Technical Report
Feb 17, 2026We introduce SecCodeBench-V2, a publicly released benchmark for evaluating Large Language Model (LLM) copilots' capabilities of generating secure code. SecCodeBench-V2 comprises 98 generation and fix scenarios derived from Alibaba Group's industrial productions, where the underlying security issues span 22 common CWE (Common Weakness Enumeration) categories across five programming languages: Java, C, Python, Go, and Node.js. SecCodeBench-V2 adopts a function-level task formulation: each scenario provides a complete project scaffold and requires the model to implement or patch a designated target function under fixed interfaces and dependencies. For each scenario, SecCodeBench-V2 provides executable proof-of-concept (PoC) test cases for both functional validation and security verification. All test cases are authored and double-reviewed by security experts, ensuring high fidelity, broad coverage, and reliable ground truth. Beyond the benchmark itself, we build a unified evaluation pipeline that assesses models primarily via dynamic execution. For most scenarios, we compile and run model-generated artifacts in isolated environments and execute PoC test cases to validate both functional correctness and security properties. For scenarios where security issues cannot be adjudicated with deterministic test cases, we additionally employ an LLM-as-a-judge oracle. To summarize performance across heterogeneous scenarios and difficulty levels, we design a Pass@K-based scoring protocol with principled aggregation over scenarios and severity, enabling holistic and comparable evaluation across models. Overall, SecCodeBench-V2 provides a rigorous and reproducible foundation for assessing the security posture of AI coding assistants, with results and artifacts released at https://alibaba.github.io/sec-code-bench. The benchmark is publicly available at https://github.com/alibaba/sec-code-bench.
Event-based Visual Deformation Measurement
Feb 16, 2026Visual Deformation Measurement (VDM) aims to recover dense deformation fields by tracking surface motion from camera observations. Traditional image-based methods rely on minimal inter-frame motion to constrain the correspondence search space, which limits their applicability to highly dynamic scenes or necessitates high-speed cameras at the cost of prohibitive storage and computational overhead. We propose an event-frame fusion framework that exploits events for temporally dense motion cues and frames for spatially dense precise estimation. Revisiting the solid elastic modeling prior, we propose an Affine Invariant Simplicial (AIS) framework. It partitions the deformation field into linearized sub-regions with low-parametric representation, effectively mitigating motion ambiguities arising from sparse and noisy events. To speed up parameter searching and reduce error accumulation, a neighborhood-greedy optimization strategy is introduced, enabling well-converged sub-regions to guide their poorly-converged neighbors, effectively suppress local error accumulation in long-term dense tracking. To evaluate the proposed method, a benchmark dataset with temporally aligned event streams and frames is established, encompassing over 120 sequences spanning diverse deformation scenarios. Experimental results show that our method outperforms the state-of-the-art baseline by 1.6% in survival rate. Remarkably, it achieves this using only 18.9% of the data storage and processing resources of high-speed video methods.
DecompileBench: A Comprehensive Benchmark for Evaluating Decompilers in Real-World Scenarios
May 16, 2025Decompilers are fundamental tools for critical security tasks, from vulnerability discovery to malware analysis, yet their evaluation remains fragmented. Existing approaches primarily focus on syntactic correctness through synthetic micro-benchmarks or subjective human ratings, failing to address real-world requirements for semantic fidelity and analyst usability. We present DecompileBench, the first comprehensive framework that enables effective evaluation of decompilers in reverse engineering workflows through three key components: \textit{real-world function extraction} (comprising 23,400 functions from 130 real-world programs), \textit{runtime-aware validation}, and \textit{automated human-centric assessment} using LLM-as-Judge to quantify the effectiveness of decompilers in reverse engineering workflows. Through a systematic comparison between six industrial-strength decompilers and six recent LLM-powered approaches, we demonstrate that LLM-based methods surpass commercial tools in code understandability despite 52.2% lower functionality correctness. These findings highlight the potential of LLM-based approaches to transform human-centric reverse engineering. We open source \href{https://github.com/Jennieett/DecompileBench}{DecompileBench} to provide a framework to advance research on decompilers and assist security experts in making informed tool selections based on their specific requirements.
DreamBench++: A Human-Aligned Benchmark for Personalized Image Generation
Jun 24, 2024



Personalized image generation holds great promise in assisting humans in everyday work and life due to its impressive function in creatively generating personalized content. However, current evaluations either are automated but misalign with humans or require human evaluations that are time-consuming and expensive. In this work, we present DreamBench++, a human-aligned benchmark automated by advanced multimodal GPT models. Specifically, we systematically design the prompts to let GPT be both human-aligned and self-aligned, empowered with task reinforcement. Further, we construct a comprehensive dataset comprising diverse images and prompts. By benchmarking 7 modern generative models, we demonstrate that DreamBench++ results in significantly more human-aligned evaluation, helping boost the community with innovative findings.
A density peaks clustering algorithm with sparse search and K-d tree
Mar 02, 2022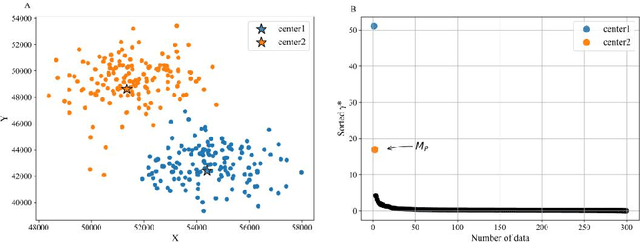
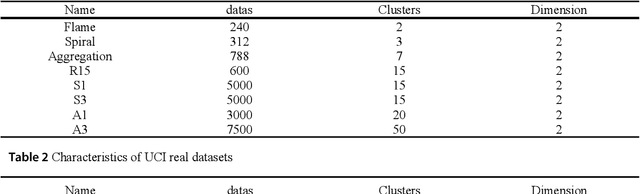
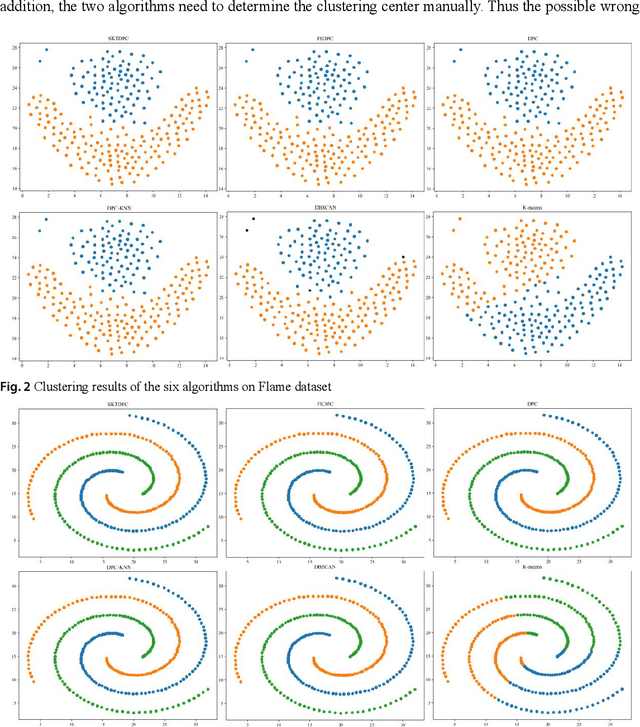
Density peaks clustering has become a nova of clustering algorithm because of its simplicity and practicality. However, there is one main drawback: it is time-consuming due to its high computational complexity. Herein, a density peaks clustering algorithm with sparse search and K-d tree is developed to solve this problem. Firstly, a sparse distance matrix is calculated by using K-d tree to replace the original full rank distance matrix, so as to accelerate the calculation of local density. Secondly, a sparse search strategy is proposed to accelerate the computation of relative-separation with the intersection between the set of k nearest neighbors and the set consisting of the data points with larger local density for any data point. Furthermore, a second-order difference method for decision values is adopted to determine the cluster centers adaptively. Finally, experiments are carried out on datasets with different distribution characteristics, by comparing with other five typical clustering algorithms. It is proved that the algorithm can effectively reduce the computational complexity. Especially for larger datasets, the efficiency is elevated more remarkably. Moreover, the clustering accuracy is also improved to a certain extent. Therefore, it can be concluded that the overall performance of the newly proposed algorithm is excellent.
ComplexFace: a Multi-Representation Approach for Image Classification with Small Dataset
Feb 21, 2019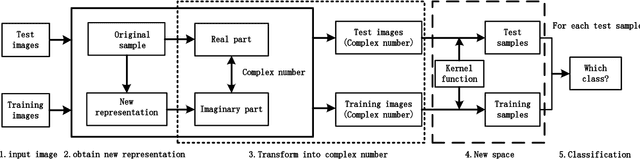



State-of-the-art face recognition algorithms are able to achieve good performance when sufficient training images are provided. Unfortunately, the number of facial images is limited in some real face recognition applications. In this paper, we propose ComplexFace, a novel and effective algorithm for face recognition with limited samples using complex number based data augmentation. The algorithm first generates new representations from original samples and then fuse both into complex numbers, which avoids the difficulty of weight setting in other fusion approaches. A test sample can then be expressed by the linear combination of all the training samples, which mapped the sample to the new representation space for classification by the kernel function. The collaborative representation based classifier is then built to make predictions. Extensive experiments on the Georgia Tech (GT) face database and the ORL face database show that our algorithm significantly outperforms existing methods: the average errors of previous approaches ranging from 31.66% to 41.75% are reduced to 14.54% over the GT database; the average errors of previous approaches ranging from 5.21% to 10.99% are reduced to 1.67% over the ORL database. In other words, our algorithm has decreased the average errors by up to 84.80% on the ORL database.
A Deep Learning Algorithm for One-step Contour Aware Nuclei Segmentation of Histopathological Images
Mar 07, 2018
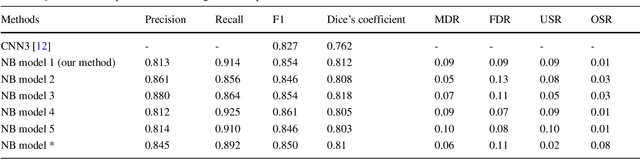
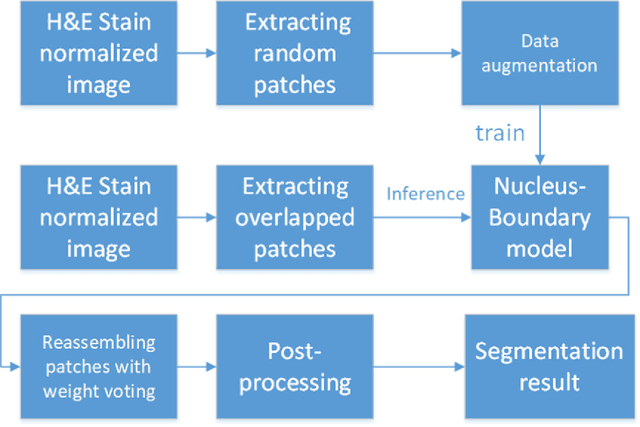
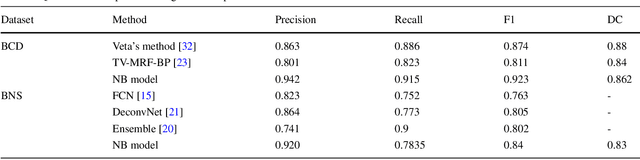
This paper addresses the task of nuclei segmentation in high-resolution histopathological images. We propose an auto- matic end-to-end deep neural network algorithm for segmenta- tion of individual nuclei. A nucleus-boundary model is introduced to predict nuclei and their boundaries simultaneously using a fully convolutional neural network. Given a color normalized image, the model directly outputs an estimated nuclei map and a boundary map. A simple, fast and parameter-free post-processing procedure is performed on the estimated nuclei map to produce the final segmented nuclei. An overlapped patch extraction and assembling method is also designed for seamless prediction of nuclei in large whole-slide images. We also show the effectiveness of data augmentation methods for nuclei segmentation task. Our experiments showed our method outperforms prior state-of-the- art methods. Moreover, it is efficient that one 1000X1000 image can be segmented in less than 5 seconds. This makes it possible to precisely segment the whole-slide image in acceptable time