 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexGrasp-Zero: A Morphology-Aligned Policy for Zero-Shot Cross-Embodiment Dexterous Grasping
Mar 17, 2026To meet the demands of increasingly diverse dexterous hand hardware, it is crucial to develop a policy that enables zero-shot cross-embodiment grasping without redundant re-learning. Cross-embodiment alignment is challenging due to heterogeneous hand kinematics and physical constraints. Existing approaches typically predict intermediate motion targets and retarget them to each embodiment, which may introduce errors and violate embodiment-specific limits, hindering transfer across diverse hands. To overcome these limitations, we propose \textit{DexGrasp-Zero}, a policy that learns universal grasping skills from diverse embodiments, enabling zero-shot transfer to unseen hands. We first introduce a morphology-aligned graph representation that maps each hand's kinematic keypoints to anatomically grounded nodes and equips each node with tri-axial orthogonal motion primitives, enabling structural and semantic alignment across different morphologies. Relying on this graph-based representation, we design a \textit{Morphology-Aligned Graph Convolutional Network} (MAGCN) to encode the graph for policy learning. MAGCN incorporates a \textit{Physical Property Injection} mechanism that fuses hand-specific physical constraints into the graph features, enabling adaptive compensation for varying link lengths and actuation limits for precise and stable grasping. Our extensive simulation evaluations on the YCB dataset demonstrate that our policy, jointly trained on four heterogeneous hands (Allegro, Shadow, Schunk, Ability), achieves an 85\% zero-shot success rate on unseen hardware (LEAP, Inspire), outperforming the state-of-the-art method by 59.5\%. Real-world experiments further evaluate our policy on three robot platforms (LEAP, Inspire, Revo2), achieving an 82\% average success rate on unseen objects.
Event-based Visual Deformation Measurement
Feb 16, 2026Visual Deformation Measurement (VDM) aims to recover dense deformation fields by tracking surface motion from camera observations. Traditional image-based methods rely on minimal inter-frame motion to constrain the correspondence search space, which limits their applicability to highly dynamic scenes or necessitates high-speed cameras at the cost of prohibitive storage and computational overhead. We propose an event-frame fusion framework that exploits events for temporally dense motion cues and frames for spatially dense precise estimation. Revisiting the solid elastic modeling prior, we propose an Affine Invariant Simplicial (AIS) framework. It partitions the deformation field into linearized sub-regions with low-parametric representation, effectively mitigating motion ambiguities arising from sparse and noisy events. To speed up parameter searching and reduce error accumulation, a neighborhood-greedy optimization strategy is introduced, enabling well-converged sub-regions to guide their poorly-converged neighbors, effectively suppress local error accumulation in long-term dense tracking. To evaluate the proposed method, a benchmark dataset with temporally aligned event streams and frames is established, encompassing over 120 sequences spanning diverse deformation scenarios. Experimental results show that our method outperforms the state-of-the-art baseline by 1.6% in survival rate. Remarkably, it achieves this using only 18.9% of the data storage and processing resources of high-speed video methods.
Event-Based Eye Tracking. 2025 Event-based Vision Workshop
Apr 25, 2025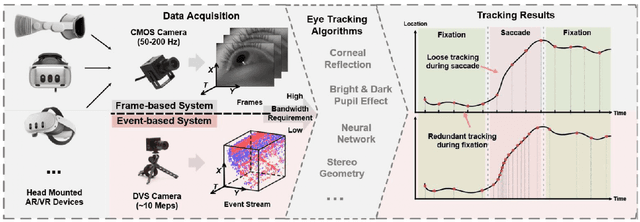
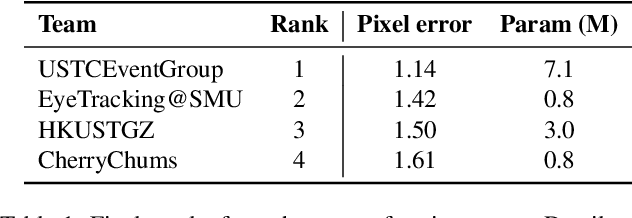
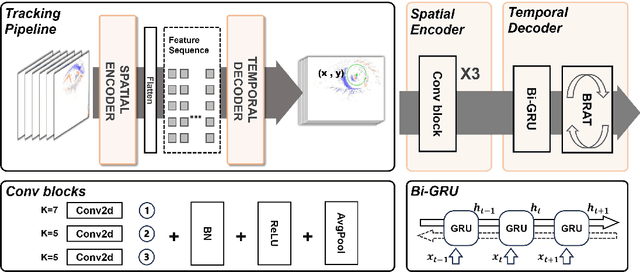

This survey serves as a review for the 2025 Event-Based Eye Tracking Challenge organized as part of the 2025 CVPR event-based vision workshop. This challenge focuses on the task of predicting the pupil center by processing event camera recorded eye movement. We review and summarize the innovative methods from teams rank the top in the challenge to advance future event-based eye tracking research. In each method, accuracy, model size, and number of operations are reported. In this survey, we also discuss event-based eye tracking from the perspective of hardware design.
MambaPupil: Bidirectional Selective Recurrent model for Event-based Eye tracking
Apr 18, 2024



Event-based eye tracking has shown great promise with the high temporal resolution and low redundancy provided by the event camera. However, the diversity and abruptness of eye movement patterns, including blinking, fixating, saccades, and smooth pursuit, pose significant challenges for eye localization. To achieve a stable event-based eye-tracking system, this paper proposes a bidirectional long-term sequence modeling and time-varying state selection mechanism to fully utilize contextual temporal information in response to the variability of eye movements. Specifically, the MambaPupil network is proposed, which consists of the multi-layer convolutional encoder to extract features from the event representations, a bidirectional Gated Recurrent Unit (GRU), and a Linear Time-Varying State Space Module (LTV-SSM), to selectively capture contextual correlation from the forward and backward temporal relationship. Furthermore, the Bina-rep is utilized as a compact event representation, and the tailor-made data augmentation, called as Event-Cutout, is proposed to enhance the model's robustness by applying spatial random masking to the event image. The evaluation on the ThreeET-plus benchmark shows the superior performance of the MambaPupil, which secured the 1st place in CVPR'2024 AIS Event-based Eye Tracking challenge.
Event-Based Eye Tracking. AIS 2024 Challenge Survey
Apr 17, 2024



This survey reviews the AIS 2024 Event-Based Eye Tracking (EET) Challenge. The task of the challenge focuses on processing eye movement recorded with event cameras and predicting the pupil center of the eye. The challenge emphasizes efficient eye tracking with event cameras to achieve good task accuracy and efficiency trade-off. During the challenge period, 38 participants registered for the Kaggle competition, and 8 teams submitted a challenge factsheet. The novel and diverse methods from the submitted factsheets are reviewed and analyzed in this survey to advance future event-based eye tracking research.
Event-based Asynchronous HDR Imaging by Temporal Incident Light Modulation
Mar 14, 2024



Dynamic Range (DR) is a pivotal characteristic of imaging systems. Current frame-based cameras struggle to achieve high dynamic range imaging due to the conflict between globally uniform exposure and spatially variant scene illumination. In this paper, we propose AsynHDR, a Pixel-Asynchronous HDR imaging system, based on key insights into the challenges in HDR imaging and the unique event-generating mechanism of Dynamic Vision Sensors (DVS). Our proposed AsynHDR system integrates the DVS with a set of LCD panels. The LCD panels modulate the irradiance incident upon the DVS by altering their transparency, thereby triggering the pixel-independent event streams. The HDR image is subsequently decoded from the event streams through our temporal-weighted algorithm. Experiments under standard test platform and several challenging scenes have verified the feasibility of the system in HDR imaging task.