 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARIO: A Mixed Annotation Framework For Polyp Segmentation
Jan 19, 2025



Existing polyp segmentation models are limited by high labeling costs and the small size of datasets. Additionally, vast polyp datasets remain underutilized because these models typically rely on a single type of annotation. To address this dilemma, we introduce MARIO, a mixed supervision model designed to accommodate various annotation types, significantly expanding the range of usable data. MARIO learns from underutilized datasets by incorporating five forms of supervision: pixel-level, box-level, polygon-level, scribblelevel, and point-level. Each form of supervision is associated with a tailored loss that effectively leverages the supervision labels while minimizing the noise. This allows MARIO to move beyond the constraints of relying on a single annotation type. Furthermore, MARIO primarily utilizes dataset with weak and cheap annotations, reducing the dependence on large-scale, fully annotated ones. Experimental results across five benchmark datasets demonstrate that MARIO consistently outperforms existing methods, highlighting its efficacy in balancing trade-offs between different forms of supervision and maximizing polyp segmentation performance
Quantization Meets Reasoning: Exploring LLM Low-Bit Quantization Degradation for Mathematical Reasoning
Jan 06, 2025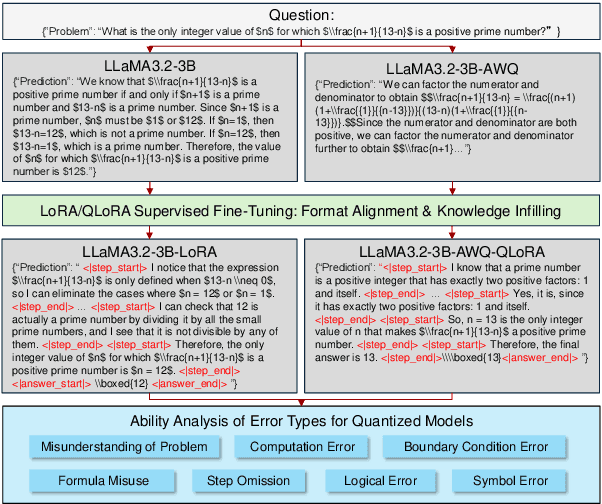
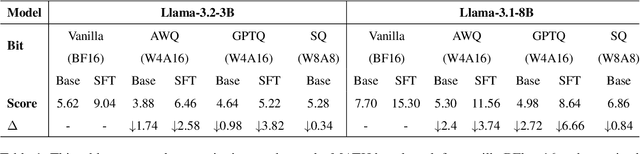

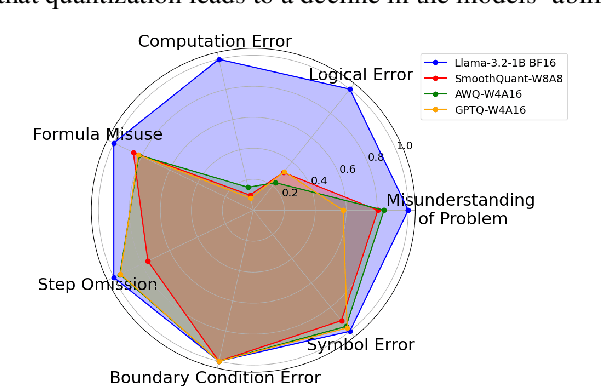
Large language models have achieved significant advancements in complex mathematical reasoning benchmarks, such as MATH. However, their substantial computational requirements present challenges for practical deployment. Model quantization has emerged as an effective strategy to reduce memory usage and computational costs by employing lower precision and bit-width representations. In this study, we systematically evaluate the impact of quantization on mathematical reasoning tasks. We introduce a multidimensional evaluation framework that qualitatively assesses specific capability dimensions and conduct quantitative analyses on the step-by-step outputs of various quantization methods. Our results demonstrate that quantization differentially affects numerical computation and reasoning planning abilities, identifying key areas where quantized models experience performance degradation.
Towards Multimodal Metaphor Understanding: A Chinese Dataset and Model for Metaphor Mapping Identification
Jan 05, 2025



Metaphors play a crucial role in human communication, yet their comprehension remains a significant challenge for natural language processing (NLP) due to the cognitive complexity involved. According to Conceptual Metaphor Theory (CMT), metaphors map a target domain onto a source domain, and understanding this mapping is essential for grasping the nature of metaphors. While existing NLP research has focused on tasks like metaphor detection and sentiment analysis of metaphorical expressions, there has been limited attention to the intricate process of identifying the mappings between source and target domains. Moreover, non-English multimodal metaphor resources remain largely neglected in the literature, hindering a deeper understanding of the key elements involved in metaphor interpretation. To address this gap, we developed a Chinese multimodal metaphor advertisement dataset (namely CM3D) that includes annotations of specific target and source domains. This dataset aims to foster further research into metaphor comprehension, particularly in non-English languages. Furthermore, we propose a Chain-of-Thought (CoT) Prompting-based Metaphor Mapping Identification Model (CPMMIM), which simulates the human cognitive process for identifying these mappings. Drawing inspiration from CoT reasoning and Bi-Level Optimization (BLO), we treat the task as a hierarchical identification problem, enabling more accurate and interpretable metaphor mapping. Our experimental results demonstrate the effectiveness of CPMMIM, highlighting its potential for advancing metaphor comprehension in NLP. Our dataset and code are both publicly available to encourage further advancements in this field.
V$^2$-SfMLearner: Learning Monocular Depth and Ego-motion for Multimodal Wireless Capsule Endoscopy
Dec 23, 2024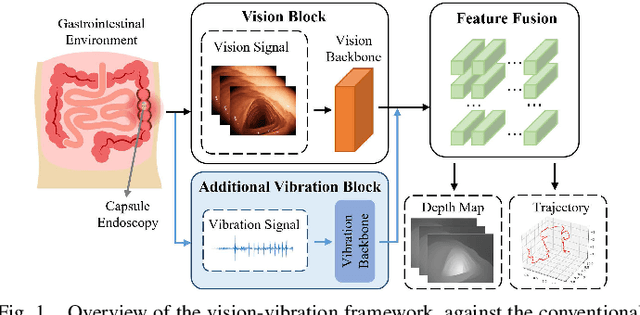
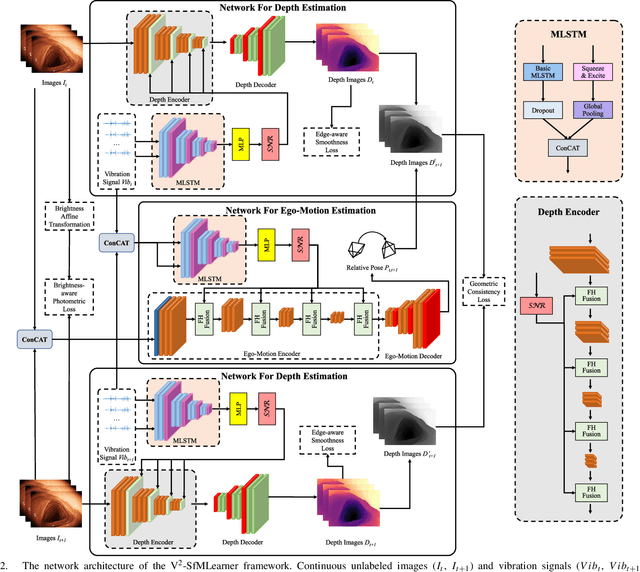
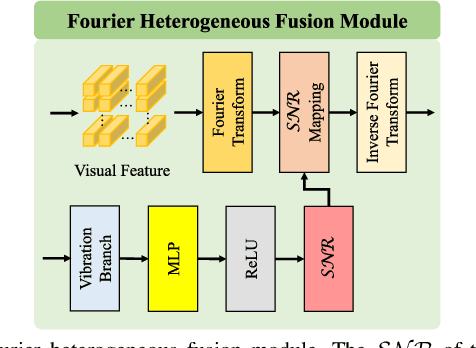
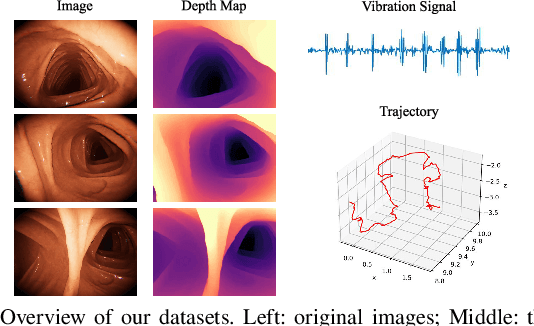
Deep learning can predict depth maps and capsule ego-motion from capsule endoscopy videos, aiding in 3D scene reconstruction and lesion localization. However, the collisions of the capsule endoscopies within the gastrointestinal tract cause vibration perturbations in the training data. Existing solutions focus solely on vision-based processing, neglecting other auxiliary signals like vibrations that could reduce noise and improve performance. Therefore, we propose V$^2$-SfMLearner, a multimodal approach integrating vibration signals into vision-based depth and capsule motion estimation for monocular capsule endoscopy. We construct a multimodal capsule endoscopy dataset containing vibration and visual signals, and our artificial intelligence solution develops an unsupervised method using vision-vibration signals, effectively eliminating vibration perturbations through multimodal learning. Specifically, we carefully design a vibration network branch and a Fourier fusion module, to detect and mitigate vibration noises. The fusion framework is compatible with popular vision-only algorithms. Extensive validation on the multimodal dataset demonstrates superior performance and robustness against vision-only algorithms. Without the need for large external equipment, our V$^2$-SfMLearner has the potential for integration into clinical capsule robots, providing real-time and dependable digestive examination tools. The findings show promise for practical implementation in clinical settings, enhancing the diagnostic capabilities of doctors.
Adaptive Pruning for Large Language Models with Structural Importance Awareness
Dec 19, 2024



The recent advancements in large language models (LLMs) have significantly improved language understanding and generation capabilities. However, it is difficult to deploy LLMs on resource-constrained edge devices due to their high computational and storage resource demands. To address this issue, we propose a novel LLM model pruning method, namely structurally-aware adaptive pruning (SAAP), to significantly reduce the computational and memory costs while maintaining model performance. We first define an adaptive importance fusion metric to evaluate the importance of all coupled structures in LLMs by considering their homoscedastic uncertainty. Then, we rank the importance of all modules to determine the specific layers that should be pruned to meet particular performance requirements. Furthermore, we develop a new group fine-tuning strategy to improve the inference efficiency of LLMs. Finally, we evaluate the proposed SAAP method on multiple LLMs across two common tasks, i.e., zero-shot classification and text generation. Experimental results show that our SAAP method outperforms several state-of-the-art baseline methods, achieving 2.17%, 2.37%, and 2.39% accuracy gains on LLaMA-7B, Vicuna-7B, and LLaMA-13B. Additionally, SAAP improves the token generation speed by 5%, showcasing its practical advantages in resource-constrained scenarios.
Consistency of Compositional Generalization across Multiple Levels
Dec 18, 2024



Compositional generalization is the capability of a model to understand novel compositions composed of seen concepts. There are multiple levels of novel compositions including phrase-phrase level, phrase-word level, and word-word level. Existing methods achieve promising compositional generalization, but the consistency of compositional generalization across multiple levels of novel compositions remains unexplored. The consistency refers to that a model should generalize to a phrase-phrase level novel composition, and phrase-word/word-word level novel compositions that can be derived from it simultaneously. In this paper, we propose a meta-learning based framework, for achieving consistent compositional generalization across multiple levels. The basic idea is to progressively learn compositions from simple to complex for consistency. Specifically, we divide the original training set into multiple validation sets based on compositional complexity, and introduce multiple meta-weight-nets to generate sample weights for samples in different validation sets. To fit the validation sets in order of increasing compositional complexity, we optimize the parameters of each meta-weight-net independently and sequentially in a multilevel optimization manner. We build a GQA-CCG dataset to quantitatively evaluate the consistency. Experimental results on visual question answering and temporal video grounding, demonstrate the effectiveness of the proposed framework. We release GQA-CCG at https://github.com/NeverMoreLCH/CCG.
An Efficient Occupancy World Model via Decoupled Dynamic Flow and Image-assisted Training
Dec 18, 2024



The field of autonomous driving is experiencing a surge of interest in world models, which aim to predict potential future scenarios based on historical observations. In this paper, we introduce DFIT-OccWorld, an efficient 3D occupancy world model that leverages decoupled dynamic flow and image-assisted training strategy, substantially improving 4D scene forecasting performance. To simplify the training process, we discard the previous two-stage training strategy and innovatively reformulate the occupancy forecasting problem as a decoupled voxels warping process. Our model forecasts future dynamic voxels by warping existing observations using voxel flow, whereas static voxels are easily obtained through pose transformation. Moreover, our method incorporates an image-assisted training paradigm to enhance prediction reliability. Specifically, differentiable volume rendering is adopted to generate rendered depth maps through predicted future volumes, which are adopted in render-based photometric consistency. Experiments demonstrate the effectiveness of our approach, showcasing its state-of-the-art performance on the nuScenes and OpenScene benchmarks for 4D occupancy forecasting, end-to-end motion planning and point cloud forecasting. Concretely, it achieves state-of-the-art performances compared to existing 3D world models while incurring substantially lower computational costs.
LLMs are Also Effective Embedding Models: An In-depth Overview
Dec 17, 2024



Large language models (LLMs) have revolutionized natural language processing by achieving state-of-the-art performance across various tasks. Recently, their effectiveness as embedding models has gained attention, marking a paradigm shift from traditional encoder-only models like ELMo and BERT to decoder-only, large-scale LLMs such as GPT, LLaMA, and Mistral. This survey provides an in-depth overview of this transition, beginning with foundational techniques before the LLM era, followed by LLM-based embedding models through two main strategies to derive embeddings from LLMs. 1) Direct prompting: We mainly discuss the prompt designs and the underlying rationale for deriving competitive embeddings. 2) Data-centric tuning: We cover extensive aspects that affect tuning an embedding model, including model architecture, training objectives, data constructions, etc. Upon the above, we also cover advanced methods, such as handling longer texts, and multilingual and cross-modal data. Furthermore, we discuss factors affecting choices of embedding models, such as performance/efficiency comparisons, dense vs sparse embeddings, pooling strategies, and scaling law. Lastly, the survey highlights the limitations and challenges in adapting LLMs for embeddings, including cross-task embedding quality, trade-offs between efficiency and accuracy, low-resource, long-context, data bias, robustness, etc. This survey serves as a valuable resource for researchers and practitioners by synthesizing current advancements, highlighting key challenges, and offering a comprehensive framework for future work aimed at enhancing the effectiveness and efficiency of LLMs as embedding models.
A Survey of Calibration Process for Black-Box LLMs
Dec 17, 2024



Large Language Models (LLMs) demonstrate remarkable performance in semantic understanding and generation, yet accurately assessing their output reliability remains a significant challenge. While numerous studies have explored calibration techniques, they primarily focus on White-Box LLMs with accessible parameters. Black-Box LLMs, despite their superior performance, pose heightened requirements for calibration techniques due to their API-only interaction constraints. Although recent researches have achieved breakthroughs in black-box LLMs calibration, a systematic survey of these methodologies is still lacking. To bridge this gap, we presents the first comprehensive survey on calibration techniques for black-box LLMs. We first define the Calibration Process of LLMs as comprising two interrelated key steps: Confidence Estimation and Calibration. Second, we conduct a systematic review of applicable methods within black-box settings, and provide insights on the unique challenges and connections in implementing these key steps. Furthermore, we explore typical applications of Calibration Process in black-box LLMs and outline promising future research directions, providing new perspectives for enhancing reliability and human-machine alignment. This is our GitHub link: https://github.com/LiangruXie/Calibration-Process-in-Black-Box-LLMs
Diffusion-Enhanced Test-time Adaptation with Text and Image Augmentation
Dec 12, 2024Existing test-time prompt tuning (TPT) methods focus on single-modality data, primarily enhancing images and using confidence ratings to filter out inaccurate images. However, while image generation models can produce visually diverse images, single-modality data enhancement techniques still fail to capture the comprehensive knowledge provided by different modalities. Additionally, we note that the performance of TPT-based methods drops significantly when the number of augmented images is limited, which is not unusual given the computational expense of generative augmentation. To address these issues, we introduce IT3A, a novel test-time adaptation method that utilizes a pre-trained generative model for multi-modal augmentation of each test sample from unknown new domains. By combining augmented data from pre-trained vision and language models, we enhance the ability of the model to adapt to unknown new test data. Additionally, to ensure that key semantics are accurately retained when generating various visual and text enhancements, we employ cosine similarity filtering between the logits of the enhanced images and text with the original test data. This process allows us to filter out some spurious augmentation and inadequate combinations. To leverage the diverse enhancements provided by the generation model across different modals, we have replaced prompt tuning with an adapter for greater flexibility in utilizing text templates. Our experiments on the test datasets with distribution shifts and domain gaps show that in a zero-shot setting, IT3A outperforms state-of-the-art test-time prompt tuning methods with a 5.50% increase in accuracy.
* Accepted by International Journal of Computer Vision