 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Explainable and Fine-Grained 3D Grounding through Referring Textual Phrases
Paper and Code

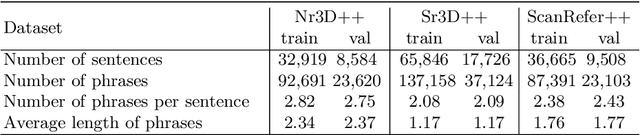
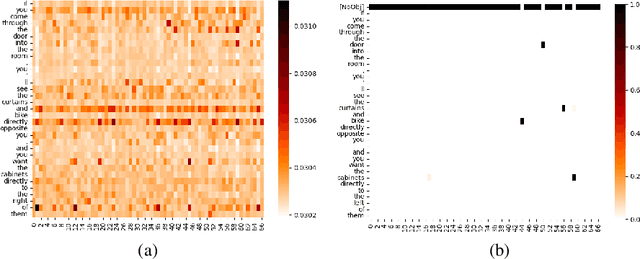
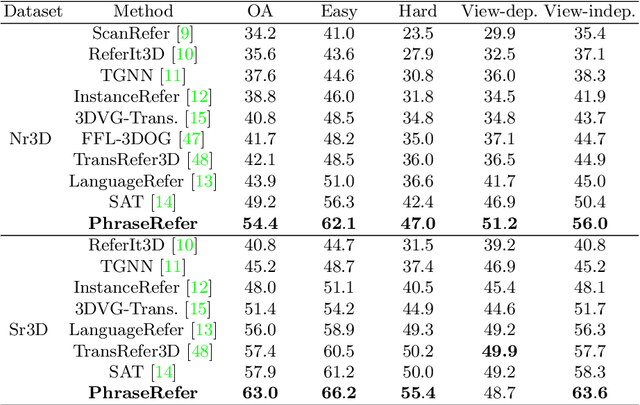
Recent progress on 3D scene understanding has explored visual grounding (3DVG) to localize a target object through a language description. However, existing methods only consider the dependency between the entire sentence and the target object, thus ignoring fine-grained relationships between contexts and non-target ones. In this paper, we extend 3DVG to a more reliable and explainable task, called 3D Phrase Aware Grounding (3DPAG). The 3DPAG task aims to localize the target object in the 3D scenes by explicitly identifying all phrase-related objects and then conducting reasoning according to contextual phrases. To tackle this problem, we label about 400K phrase-level annotations from 170K sentences in available 3DVG datasets, i.e., Nr3D, Sr3D and ScanRefer. By tapping on these developed datasets, we propose a novel framework, i.e., PhraseRefer, which conducts phrase-aware and object-level representation learning through phrase-object alignment optimization as well as phrase-specific pre-training. In our setting, we extend previous 3DVG methods to the phrase-aware scenario and provide metrics to measure the explainability of the 3DPAG task. Extensive results confirm that 3DPAG effectively boosts the 3DVG, and PhraseRefer achieves state-of-the-arts across three datasets, i.e., 63.0%, 54.4% and 55.5% overall accuracy on Sr3D, Nr3D and ScanRefer, respectively.