 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Multi-Modal Coding for High-Quality 3D Generation
Aug 21, 20253D content inherently encompasses multi-modal characteristics and can be projected into different modalities (e.g., RGB images, RGBD, and point clouds). Each modality exhibits distinct advantages in 3D asset modeling: RGB images contain vivid 3D textures, whereas point clouds define fine-grained 3D geometries. However, most existing 3D-native generative architectures either operate predominantly within single-modality paradigms-thus overlooking the complementary benefits of multi-modality data-or restrict themselves to 3D structures, thereby limiting the scope of available training datasets. To holistically harness multi-modalities for 3D modeling, we present TriMM, the first feed-forward 3D-native generative model that learns from basic multi-modalities (e.g., RGB, RGBD, and point cloud). Specifically, 1) TriMM first introduces collaborative multi-modal coding, which integrates modality-specific features while preserving their unique representational strengths. 2) Furthermore, auxiliary 2D and 3D supervision are introduced to raise the robustness and performance of multi-modal coding. 3) Based on the embedded multi-modal code, TriMM employs a triplane latent diffusion model to generate 3D assets of superior quality, enhancing both the texture and the geometric detail. Extensive experiments on multiple well-known datasets demonstrate that TriMM, by effectively leveraging multi-modality, achieves competitive performance with models trained on large-scale datasets, despite utilizing a small amount of training data. Furthermore, we conduct additional experiments on recent RGB-D datasets, verifying the feasibility of incorporating other multi-modal datasets into 3D generation.
4DNeX: Feed-Forward 4D Generative Modeling Made Easy
Aug 18, 2025



We present 4DNeX, the first feed-forward framework for generating 4D (i.e., dynamic 3D) scene representations from a single image. In contrast to existing methods that rely on computationally intensive optimization or require multi-frame video inputs, 4DNeX enables efficient, end-to-end image-to-4D generation by fine-tuning a pretrained video diffusion model. Specifically, 1) to alleviate the scarcity of 4D data, we construct 4DNeX-10M, a large-scale dataset with high-quality 4D annotations generated using advanced reconstruction approaches. 2) we introduce a unified 6D video representation that jointly models RGB and XYZ sequences, facilitating structured learning of both appearance and geometry. 3) we propose a set of simple yet effective adaptation strategies to repurpose pretrained video diffusion models for 4D modeling. 4DNeX produces high-quality dynamic point clouds that enable novel-view video synthesis. Extensive experiments demonstrate that 4DNeX outperforms existing 4D generation methods in efficiency and generalizability, offering a scalable solution for image-to-4D modeling and laying the foundation for generative 4D world models that simulate dynamic scene evolution.
Reconstructing 4D Spatial Intelligence: A Survey
Jul 28, 2025



Reconstructing 4D spatial intelligence from visual observations has long been a central yet challenging task in computer vision, with broad real-world applications. These range from entertainment domains like movies, where the focus is often on reconstructing fundamental visual elements, to embodied AI, which emphasizes interaction modeling and physical realism. Fueled by rapid advances in 3D representations and deep learning architectures, the field has evolved quickly, outpacing the scope of previous surveys. Additionally, existing surveys rarely offer a comprehensive analysis of the hierarchical structure of 4D scene reconstruction. To address this gap, we present a new perspective that organizes existing methods into five progressive levels of 4D spatial intelligence: (1) Level 1 -- reconstruction of low-level 3D attributes (e.g., depth, pose, and point maps); (2) Level 2 -- reconstruction of 3D scene components (e.g., objects, humans, structures); (3) Level 3 -- reconstruction of 4D dynamic scenes; (4) Level 4 -- modeling of interactions among scene components; and (5) Level 5 -- incorporation of physical laws and constraints. We conclude the survey by discussing the key challenges at each level and highlighting promising directions for advancing toward even richer levels of 4D spatial intelligence. To track ongoing developments, we maintain an up-to-date project page: https://github.com/yukangcao/Awesome-4D-Spatial-Intelligence.
PhysX: Physical-Grounded 3D Asset Generation
Jul 16, 2025



3D modeling is moving from virtual to physical. Existing 3D generation primarily emphasizes geometries and textures while neglecting physical-grounded modeling. Consequently, despite the rapid development of 3D generative models, the synthesized 3D assets often overlook rich and important physical properties, hampering their real-world application in physical domains like simulation and embodied AI. As an initial attempt to address this challenge, we propose \textbf{PhysX}, an end-to-end paradigm for physical-grounded 3D asset generation. 1) To bridge the critical gap in physics-annotated 3D datasets, we present PhysXNet - the first physics-grounded 3D dataset systematically annotated across five foundational dimensions: absolute scale, material, affordance, kinematics, and function description. In particular, we devise a scalable human-in-the-loop annotation pipeline based on vision-language models, which enables efficient creation of physics-first assets from raw 3D assets.2) Furthermore, we propose \textbf{PhysXGen}, a feed-forward framework for physics-grounded image-to-3D asset generation, injecting physical knowledge into the pre-trained 3D structural space. Specifically, PhysXGen employs a dual-branch architecture to explicitly model the latent correlations between 3D structures and physical properties, thereby producing 3D assets with plausible physical predictions while preserving the native geometry quality. Extensive experiments validate the superior performance and promising generalization capability of our framework. All the code, data, and models will be released to facilitate future research in generative physical AI.
Light of Normals: Unified Feature Representation for Universal Photometric Stereo
Jun 24, 2025



Universal photometric stereo (PS) aims to recover high-quality surface normals from objects under arbitrary lighting conditions without relying on specific illumination models. Despite recent advances such as SDM-UniPS and Uni MS-PS, two fundamental challenges persist: 1) the deep coupling between varying illumination and surface normal features, where ambiguity in observed intensity makes it difficult to determine whether brightness variations stem from lighting changes or surface orientation; and 2) the preservation of high-frequency geometric details in complex surfaces, where intricate geometries create self-shadowing, inter-reflections, and subtle normal variations that conventional feature processing operations struggle to capture accurately.
Rethinking Cross-Modal Interaction in Multimodal Diffusion Transformers
Jun 09, 2025



Multimodal Diffusion Transformers (MM-DiTs) have achieved remarkable progress in text-driven visual generation. However, even state-of-the-art MM-DiT models like FLUX struggle with achieving precise alignment between text prompts and generated content. We identify two key issues in the attention mechanism of MM-DiT, namely 1) the suppression of cross-modal attention due to token imbalance between visual and textual modalities and 2) the lack of timestep-aware attention weighting, which hinder the alignment. To address these issues, we propose \textbf{Temperature-Adjusted Cross-modal Attention (TACA)}, a parameter-efficient method that dynamically rebalances multimodal interactions through temperature scaling and timestep-dependent adjustment. When combined with LoRA fine-tuning, TACA significantly enhances text-image alignment on the T2I-CompBench benchmark with minimal computational overhead. We tested TACA on state-of-the-art models like FLUX and SD3.5, demonstrating its ability to improve image-text alignment in terms of object appearance, attribute binding, and spatial relationships. Our findings highlight the importance of balancing cross-modal attention in improving semantic fidelity in text-to-image diffusion models. Our codes are publicly available at \href{https://github.com/Vchitect/TACA}
Unifying Appearance Codes and Bilateral Grids for Driving Scene Gaussian Splatting
Jun 06, 2025Neural rendering techniques, including NeRF and Gaussian Splatting (GS), rely on photometric consistency to produce high-quality reconstructions. However, in real-world scenarios, it is challenging to guarantee perfect photometric consistency in acquired images. Appearance codes have been widely used to address this issue, but their modeling capability is limited, as a single code is applied to the entire image. Recently, the bilateral grid was introduced to perform pixel-wise color mapping, but it is difficult to optimize and constrain effectively. In this paper, we propose a novel multi-scale bilateral grid that unifies appearance codes and bilateral grids. We demonstrate that this approach significantly improves geometric accuracy in dynamic, decoupled autonomous driving scene reconstruction, outperforming both appearance codes and bilateral grids. This is crucial for autonomous driving, where accurate geometry is important for obstacle avoidance and control. Our method shows strong results across four datasets: Waymo, NuScenes, Argoverse, and PandaSet. We further demonstrate that the improvement in geometry is driven by the multi-scale bilateral grid, which effectively reduces floaters caused by photometric inconsistency.
3D Scene Generation: A Survey
May 08, 2025

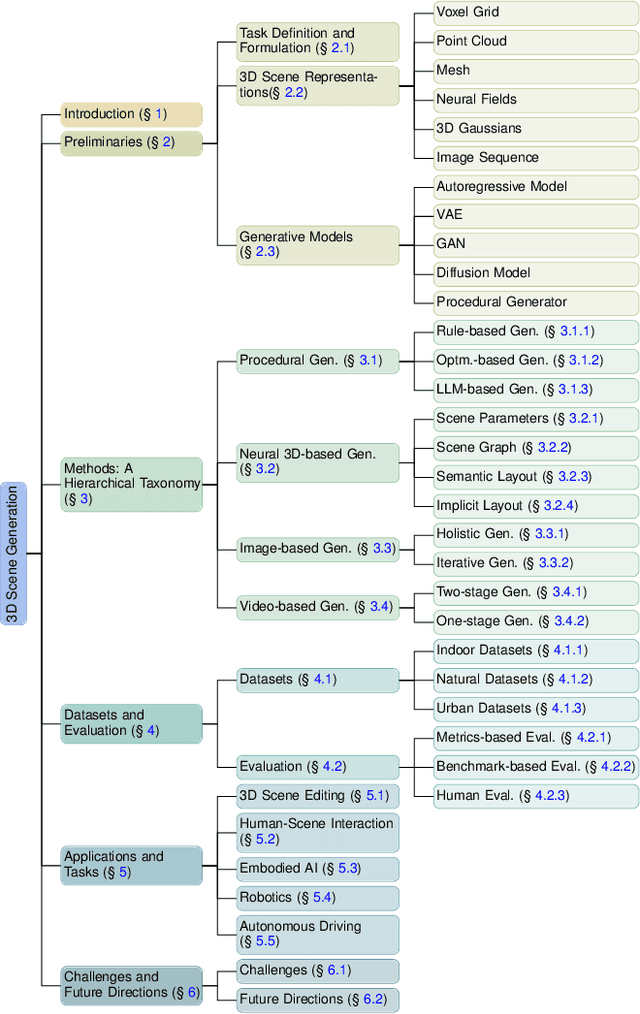
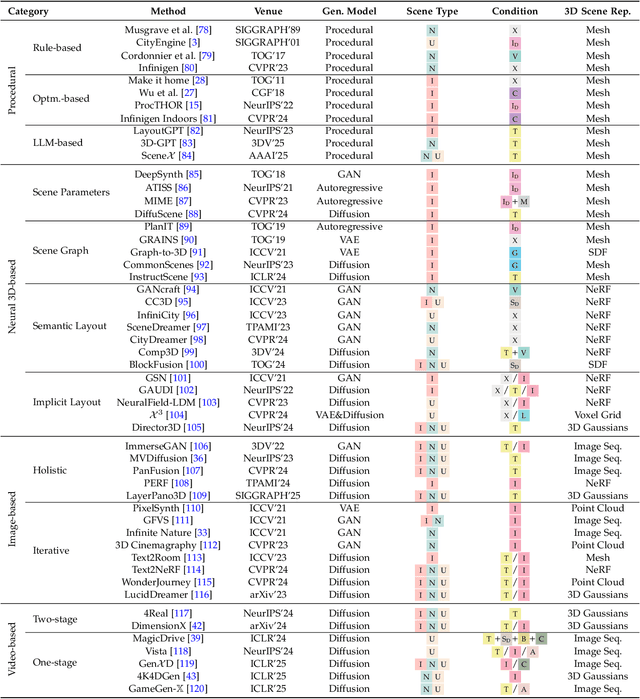
3D scene generation seeks to synthesize spatially structured, semantically meaningful, and photorealistic environments for applications such as immersive media, robotics, autonomous driving, and embodied AI. Early methods based on procedural rules offered scalability but limited diversity. Recent advances in deep generative models (e.g., GANs, diffusion models) and 3D representations (e.g., NeRF, 3D Gaussians) have enabled the learning of real-world scene distributions, improving fidelity, diversity, and view consistency. Recent advances like diffusion models bridge 3D scene synthesis and photorealism by reframing generation as image or video synthesis problems. This survey provides a systematic overview of state-of-the-art approaches, organizing them into four paradigms: procedural generation, neural 3D-based generation, image-based generation, and video-based generation. We analyze their technical foundations, trade-offs, and representative results, and review commonly used datasets, evaluation protocols, and downstream applications. We conclude by discussing key challenges in generation capacity, 3D representation, data and annotations, and evaluation, and outline promising directions including higher fidelity, physics-aware and interactive generation, and unified perception-generation models. This review organizes recent advances in 3D scene generation and highlights promising directions at the intersection of generative AI, 3D vision, and embodied intelligence. To track ongoing developments, we maintain an up-to-date project page: https://github.com/hzxie/Awesome-3D-Scene-Generation.
Free4D: Tuning-free 4D Scene Generation with Spatial-Temporal Consistency
Mar 26, 2025



We present Free4D, a novel tuning-free framework for 4D scene generation from a single image. Existing methods either focus on object-level generation, making scene-level generation infeasible, or rely on large-scale multi-view video datasets for expensive training, with limited generalization ability due to the scarcity of 4D scene data. In contrast, our key insight is to distill pre-trained foundation models for consistent 4D scene representation, which offers promising advantages such as efficiency and generalizability. 1) To achieve this, we first animate the input image using image-to-video diffusion models followed by 4D geometric structure initialization. 2) To turn this coarse structure into spatial-temporal consistent multiview videos, we design an adaptive guidance mechanism with a point-guided denoising strategy for spatial consistency and a novel latent replacement strategy for temporal coherence. 3) To lift these generated observations into consistent 4D representation, we propose a modulation-based refinement to mitigate inconsistencies while fully leveraging the generated information. The resulting 4D representation enables real-time, controllable rendering, marking a significant advancement in single-image-based 4D scene generation.
Fusion of Millimeter-wave Radar and Pulse Oximeter Data for Low-burden Diagnosis of Obstructive Sleep Apnea-Hypopnea Syndrome
Jan 25, 2025



Objective: The aim of the study is to develop a novel method for improved diagnosis of obstructive sleep apnea-hypopnea syndrome (OSAHS) in clinical or home settings, with the focus on achieving diagnostic performance comparable to the gold-standard polysomnography (PSG) with significantly reduced monitoring burden. Methods: We propose a method using millimeter-wave radar and pulse oximeter for OSAHS diagnosis (ROSA). It contains a sleep apnea-hypopnea events (SAE) detection network, which directly predicts the temporal localization of SAE, and a sleep staging network, which predicts the sleep stages throughout the night, based on radar signals. It also fuses oxygen saturation (SpO2) information from the pulse oximeter to adjust the score of SAE detected by radar. Results: Experimental results on a real-world dataset (>800 hours of overnight recordings, 100 subjects) demonstrated high agreement (ICC=0.9870) on apnea-hypopnea index (AHI) between ROSA and PSG. ROSA also exhibited excellent diagnostic performance, exceeding 90% in accuracy across AHI diagnostic thresholds of 5, 15 and 30 events/h. Conclusion: ROSA improves diagnostic accuracy by fusing millimeter-wave radar and pulse oximeter data. It provides a reliable and low-burden solution for OSAHS diagnosis. Significance: ROSA addresses the limitations of high complexity and monitoring burden associated with traditional PSG. The high accuracy and low burden of ROSA show its potential to improve the accessibility of OSAHS diagnosis among population.