 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Autoregressive Diffusion: Global Memory Meets Local Attention
Nov 17, 2025
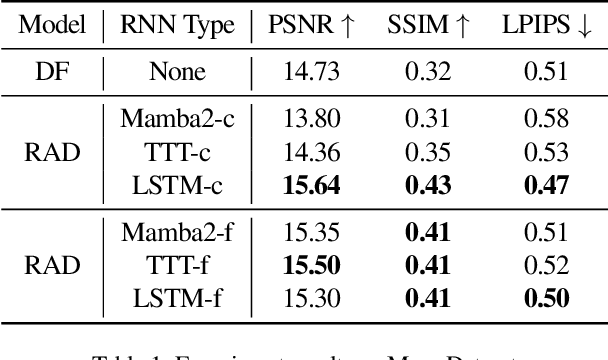

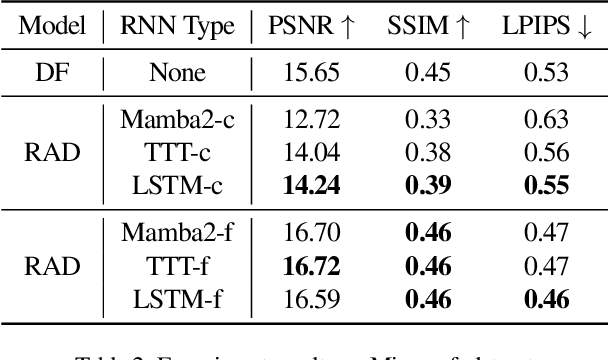
Recent advancements in video generation have demonstrated the potential of using video diffusion models as world models, with autoregressive generation of infinitely long videos through masked conditioning. However, such models, usually with local full attention, lack effective memory compression and retrieval for long-term generation beyond the window size, leading to issues of forgetting and spatiotemporal inconsistencies. To enhance the retention of historical information within a fixed memory budget, we introduce a recurrent neural network (RNN) into the diffusion transformer framework. Specifically, a diffusion model incorporating LSTM with attention achieves comparable performance to state-of-the-art RNN blocks, such as TTT and Mamba2. Moreover, existing diffusion-RNN approaches often suffer from performance degradation due to training-inference gap or the lack of overlap across windows. To address these limitations, we propose a novel Recurrent Autoregressive Diffusion (RAD) framework, which executes frame-wise autoregression for memory update and retrieval, consistently across training and inference time. Experiments on Memory Maze and Minecraft datasets demonstrate the superiority of RAD for long video generation, highlighting the efficiency of LSTM in sequence modeling.
Learning World Models for Interactive Video Generation
May 28, 2025Foundational world models must be both interactive and preserve spatiotemporal coherence for effective future planning with action choices. However, present models for long video generation have limited inherent world modeling capabilities due to two main challenges: compounding errors and insufficient memory mechanisms. We enhance image-to-video models with interactive capabilities through additional action conditioning and autoregressive framework, and reveal that compounding error is inherently irreducible in autoregressive video generation, while insufficient memory mechanism leads to incoherence of world models. We propose video retrieval augmented generation (VRAG) with explicit global state conditioning, which significantly reduces long-term compounding errors and increases spatiotemporal consistency of world models. In contrast, naive autoregressive generation with extended context windows and retrieval-augmented generation prove less effective for video generation, primarily due to the limited in-context learning capabilities of current video models. Our work illuminates the fundamental challenges in video world models and establishes a comprehensive benchmark for improving video generation models with internal world modeling capabilities.
Scalable Defense against In-the-wild Jailbreaking Attacks with Safety Context Retrieval
May 21, 2025Large Language Models (LLMs) are known to be vulnerable to jailbreaking attacks, wherein adversaries exploit carefully engineered prompts to induce harmful or unethical responses. Such threats have raised critical concerns about the safety and reliability of LLMs in real-world deployment. While existing defense mechanisms partially mitigate such risks, subsequent advancements in adversarial techniques have enabled novel jailbreaking methods to circumvent these protections, exposing the limitations of static defense frameworks. In this work, we explore defending against evolving jailbreaking threats through the lens of context retrieval. First, we conduct a preliminary study demonstrating that even a minimal set of safety-aligned examples against a particular jailbreak can significantly enhance robustness against this attack pattern. Building on this insight, we further leverage the retrieval-augmented generation (RAG) techniques and propose Safety Context Retrieval (SCR), a scalable and robust safeguarding paradigm for LLMs against jailbreaking. Our comprehensive experiments demonstrate how SCR achieves superior defensive performance against both established and emerging jailbreaking tactics, contributing a new paradigm to LLM safety. Our code will be available upon publication.
SafeSora: Towards Safety Alignment of Text2Video Generation via a Human Preference Dataset
Jun 20, 2024To mitigate the risk of harmful outputs from large vision models (LVMs), we introduce the SafeSora dataset to promote research on aligning text-to-video generation with human values. This dataset encompasses human preferences in text-to-video generation tasks along two primary dimensions: helpfulness and harmlessness. To capture in-depth human preferences and facilitate structured reasoning by crowdworkers, we subdivide helpfulness into 4 sub-dimensions and harmlessness into 12 sub-categories, serving as the basis for pilot annotations. The SafeSora dataset includes 14,711 unique prompts, 57,333 unique videos generated by 4 distinct LVMs, and 51,691 pairs of preference annotations labeled by humans. We further demonstrate the utility of the SafeSora dataset through several applications, including training the text-video moderation model and aligning LVMs with human preference by fine-tuning a prompt augmentation module or the diffusion model. These applications highlight its potential as the foundation for text-to-video alignment research, such as human preference modeling and the development and validation of alignment algorithms.