 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Compressed Frame Sizes For Ultra-Fast Video Classification
Mar 13, 2024



Classifying videos into distinct categories, such as Sport and Music Video, is crucial for multimedia understanding and retrieval, especially when an immense volume of video content is being constantly generated. Traditional methods require video decompression to extract pixel-level features like color, texture, and motion, thereby increasing computational and storage demands. Moreover, these methods often suffer from performance degradation in low-quality videos. We present a novel approach that examines only the post-compression bitstream of a video to perform classification, eliminating the need for bitstream decoding. To validate our approach, we built a comprehensive data set comprising over 29,000 YouTube video clips, totaling 6,000 hours and spanning 11 distinct categories. Our evaluations indicate precision, accuracy, and recall rates consistently above 80%, many exceeding 90%, and some reaching 99%. The algorithm operates approximately 15,000 times faster than real-time for 30fps videos, outperforming traditional Dynamic Time Warping (DTW) algorithm by seven orders of magnitude.
Evaluating Membership Inference Attacks and Defenses in Federated Learning
Feb 09, 2024



Membership Inference Attacks (MIAs) pose a growing threat to privacy preservation in federated learning. The semi-honest attacker, e.g., the server, may determine whether a particular sample belongs to a target client according to the observed model information. This paper conducts an evaluation of existing MIAs and corresponding defense strategies. Our evaluation on MIAs reveals two important findings about the trend of MIAs. Firstly, combining model information from multiple communication rounds (Multi-temporal) enhances the overall effectiveness of MIAs compared to utilizing model information from a single epoch. Secondly, incorporating models from non-target clients (Multi-spatial) significantly improves the effectiveness of MIAs, particularly when the clients' data is homogeneous. This highlights the importance of considering the temporal and spatial model information in MIAs. Next, we assess the effectiveness via privacy-utility tradeoff for two type defense mechanisms against MIAs: Gradient Perturbation and Data Replacement. Our results demonstrate that Data Replacement mechanisms achieve a more optimal balance between preserving privacy and maintaining model utility. Therefore, we recommend the adoption of Data Replacement methods as a defense strategy against MIAs. Our code is available in https://github.com/Liar-Mask/FedMIA.
A Theoretical Analysis of Efficiency Constrained Utility-Privacy Bi-Objective Optimization in Federated Learning
Dec 27, 2023



Federated learning (FL) enables multiple clients to collaboratively learn a shared model without sharing their individual data. Concerns about utility, privacy, and training efficiency in FL have garnered significant research attention. Differential privacy has emerged as a prevalent technique in FL, safeguarding the privacy of individual user data while impacting utility and training efficiency. Within Differential Privacy Federated Learning (DPFL), previous studies have primarily focused on the utility-privacy trade-off, neglecting training efficiency, which is crucial for timely completion. Moreover, differential privacy achieves privacy by introducing controlled randomness (noise) on selected clients in each communication round. Previous work has mainly examined the impact of noise level ($\sigma$) and communication rounds ($T$) on the privacy-utility dynamic, overlooking other influential factors like the sample ratio ($q$, the proportion of selected clients). This paper systematically formulates an efficiency-constrained utility-privacy bi-objective optimization problem in DPFL, focusing on $\sigma$, $T$, and $q$. We provide a comprehensive theoretical analysis, yielding analytical solutions for the Pareto front. Extensive empirical experiments verify the validity and efficacy of our analysis, offering valuable guidance for low-cost parameter design in DPFL.
Improving Language Model-Based Zero-Shot Text-to-Speech Synthesis with Multi-Scale Acoustic Prompts
Sep 22, 2023Zero-shot text-to-speech (TTS) synthesis aims to clone any unseen speaker's voice without adaptation parameters. By quantizing speech waveform into discrete acoustic tokens and modeling these tokens with the language model, recent language model-based TTS models show zero-shot speaker adaptation capabilities with only a 3-second acoustic prompt of an unseen speaker. However, they are limited by the length of the acoustic prompt, which makes it difficult to clone personal speaking style. In this paper, we propose a novel zero-shot TTS model with the multi-scale acoustic prompts based on a neural codec language model VALL-E. A speaker-aware text encoder is proposed to learn the personal speaking style at the phoneme-level from the style prompt consisting of multiple sentences. Following that, a VALL-E based acoustic decoder is utilized to model the timbre from the timbre prompt at the frame-level and generate speech. The experimental results show that our proposed method outperforms baselines in terms of naturalness and speaker similarity, and can achieve better performance by scaling out to a longer style prompt.
Judging a video by its bitstream cover
Sep 14, 2023Classifying videos into distinct categories, such as Sport and Music Video, is crucial for multimedia understanding and retrieval, especially in an age where an immense volume of video content is constantly being generated. Traditional methods require video decompression to extract pixel-level features like color, texture, and motion, thereby increasing computational and storage demands. Moreover, these methods often suffer from performance degradation in low-quality videos. We present a novel approach that examines only the post-compression bitstream of a video to perform classification, eliminating the need for bitstream. We validate our approach using a custom-built data set comprising over 29,000 YouTube video clips, totaling 6,000 hours and spanning 11 distinct categories. Our preliminary evaluations indicate precision, accuracy, and recall rates well over 80%. The algorithm operates approximately 15,000 times faster than real-time for 30fps videos, outperforming traditional Dynamic Time Warping (DTW) algorithm by six orders of magnitude.
Prompt-enhanced Hierarchical Transformer Elevating Cardiopulmonary Resuscitation Instruction via Temporal Action Segmentation
Aug 31, 2023



The vast majority of people who suffer unexpected cardiac arrest are performed cardiopulmonary resuscitation (CPR) by passersby in a desperate attempt to restore life, but endeavors turn out to be fruitless on account of disqualification. Fortunately, many pieces of research manifest that disciplined training will help to elevate the success rate of resuscitation, which constantly desires a seamless combination of novel techniques to yield further advancement. To this end, we collect a custom CPR video dataset in which trainees make efforts to behave resuscitation on mannequins independently in adherence to approved guidelines, thereby devising an auxiliary toolbox to assist supervision and rectification of intermediate potential issues via modern deep learning methodologies. Our research empirically views this problem as a temporal action segmentation (TAS) task in computer vision, which aims to segment an untrimmed video at a frame-wise level. Here, we propose a Prompt-enhanced hierarchical Transformer (PhiTrans) that integrates three indispensable modules, including a textual prompt-based Video Features Extractor (VFE), a transformer-based Action Segmentation Executor (ASE), and a regression-based Prediction Refinement Calibrator (PRC). The backbone of the model preferentially derives from applications in three approved public datasets (GTEA, 50Salads, and Breakfast) collected for TAS tasks, which accounts for the excavation of the segmentation pipeline on the CPR dataset. In general, we unprecedentedly probe into a feasible pipeline that genuinely elevates the CPR instruction qualification via action segmentation in conjunction with cutting-edge deep learning techniques. Associated experiments advocate our implementation with multiple metrics surpassing 91.0%.
Optimizing Privacy, Utility and Efficiency in Constrained Multi-Objective Federated Learning
May 09, 2023Conventionally, federated learning aims to optimize a single objective, typically the utility. However, for a federated learning system to be trustworthy, it needs to simultaneously satisfy multiple/many objectives, such as maximizing model performance, minimizing privacy leakage and training cost, and being robust to malicious attacks. Multi-Objective Optimization (MOO) aiming to optimize multiple conflicting objectives at the same time is quite suitable for solving the optimization problem of Trustworthy Federated Learning (TFL). In this paper, we unify MOO and TFL by formulating the problem of constrained multi-objective federated learning (CMOFL). Under this formulation, existing MOO algorithms can be adapted to TFL straightforwardly. Different from existing CMOFL works focusing on utility, efficiency, fairness, and robustness, we consider optimizing privacy leakage along with utility loss and training cost, the three primary objectives of a TFL system. We develop two improved CMOFL algorithms based on NSGA-II and PSL, respectively, for effectively and efficiently finding Pareto optimal solutions, and we provide theoretical analysis on their convergence. We design specific measurements of privacy leakage, utility loss, and training cost for three privacy protection mechanisms: Randomization, BatchCrypt (An efficient version of homomorphic encryption), and Sparsification. Empirical experiments conducted under each of the three protection mechanisms demonstrate the effectiveness of our proposed algorithms.
Efficient Semantic Segmentation by Altering Resolutions for Compressed Videos
Mar 13, 2023



Video semantic segmentation (VSS) is a computationally expensive task due to the per-frame prediction for videos of high frame rates. In recent work, compact models or adaptive network strategies have been proposed for efficient VSS. However, they did not consider a crucial factor that affects the computational cost from the input side: the input resolution. In this paper, we propose an altering resolution framework called AR-Seg for compressed videos to achieve efficient VSS. AR-Seg aims to reduce the computational cost by using low resolution for non-keyframes. To prevent the performance degradation caused by downsampling, we design a Cross Resolution Feature Fusion (CReFF) module, and supervise it with a novel Feature Similarity Training (FST) strategy. Specifically, CReFF first makes use of motion vectors stored in a compressed video to warp features from high-resolution keyframes to low-resolution non-keyframes for better spatial alignment, and then selectively aggregates the warped features with local attention mechanism. Furthermore, the proposed FST supervises the aggregated features with high-resolution features through an explicit similarity loss and an implicit constraint from the shared decoding layer. Extensive experiments on CamVid and Cityscapes show that AR-Seg achieves state-of-the-art performance and is compatible with different segmentation backbones. On CamVid, AR-Seg saves 67% computational cost (measured in GFLOPs) with the PSPNet18 backbone while maintaining high segmentation accuracy. Code: https://github.com/THU-LYJ-Lab/AR-Seg.
Channel-Aware Ordered Successive Relaying with Finite-Blocklength Coding
Oct 26, 2022



Successive relaying can improve the transmission rate by allowing the source and relays to transmit messages simultaneously, but it may cause severe inter-relay interference (IRI). IRI cancellation schemes have been proposed to mitigate IRI. However, interference cancellation methods have a high risk of error propagation, resulting in a severe transmission rate loss in finite blocklength regimes. Thus, jointly decoding for successive relaying with finite-blocklength coding (FBC) remains a challenge. In this paper, we present an optimized channel-aware ordered successive relaying protocol with finite-blocklength coding (CAO-SIR-FBC), which can recover the rate loss by carefully adapting the relay transmission order and rate. We analyze the average throughput of the CAO-SIR-FBC method, based on which a closed-form expression in a high signal-to-noise regime (SNR) is presented. Average throughput analysis and simulations show that CAO-SIR-FBC outperforms conventional two-timeslot half-duplex relaying in terms of spectral efficiency.
Neuro-Symbolic Learning: Principles and Applications in Ophthalmology
Jul 31, 2022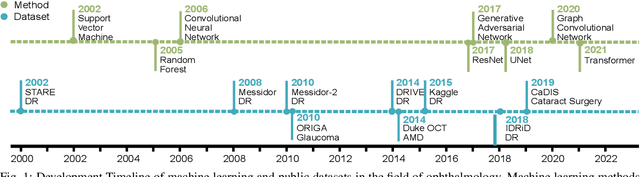
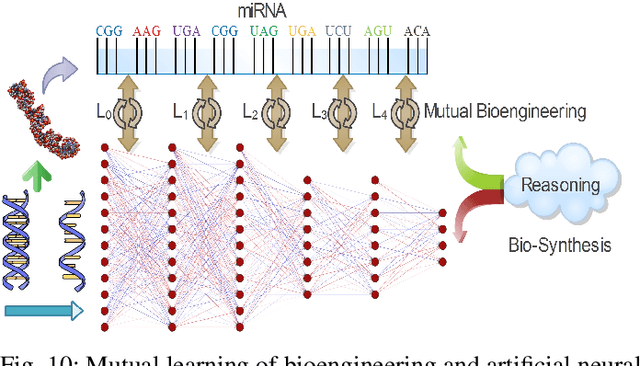
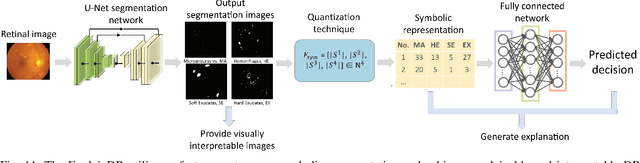
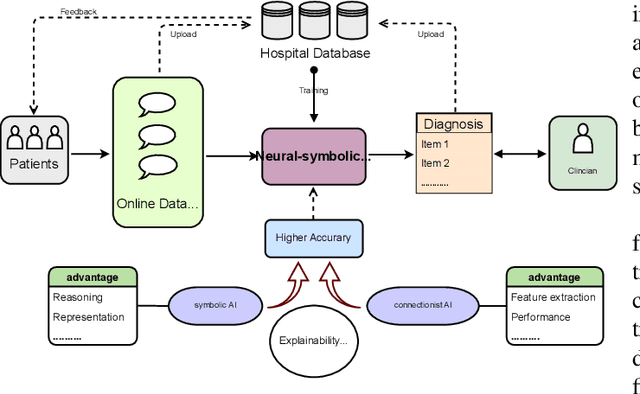
Neural networks have been rapidly expanding in recent years, with novel strategies and applications. However, challenges such as interpretability, explainability, robustness, safety, trust, and sensibility remain unsolved in neural network technologies, despite the fact that they will unavoidably be addressed for critical applications. Attempts have been made to overcome the challenges in neural network computing by representing and embedding domain knowledge in terms of symbolic representations. Thus, the neuro-symbolic learning (NeSyL) notion emerged, which incorporates aspects of symbolic representation and bringing common sense into neural networks (NeSyL). In domains where interpretability, reasoning, and explainability are crucial, such as video and image captioning, question-answering and reasoning, health informatics, and genomics, NeSyL has shown promising outcomes. This review presents a comprehensive survey on the state-of-the-art NeSyL approaches, their principles, advances in machine and deep learning algorithms, applications such as opthalmology, and most importantly, future perspectives of this emerging field.