 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Model based Sequential Keyframe Extraction for Video Summarization
Jan 10, 2024Keyframe extraction aims to sum up a video's semantics with the minimum number of its frames. This paper puts forward a Large Model based Sequential Keyframe Extraction for video summarization, dubbed LMSKE, which contains three stages as below. First, we use the large model "TransNetV21" to cut the video into consecutive shots, and employ the large model "CLIP2" to generate each frame's visual feature within each shot; Second, we develop an adaptive clustering algorithm to yield candidate keyframes for each shot, with each candidate keyframe locating nearest to a cluster center; Third, we further reduce the above candidate keyframes via redundancy elimination within each shot, and finally concatenate them in accordance with the sequence of shots as the final sequential keyframes. To evaluate LMSKE, we curate a benchmark dataset and conduct rich experiments, whose results exhibit that LMSKE performs much better than quite a few SOTA competitors with average F1 of 0.5311, average fidelity of 0.8141, and average compression ratio of 0.9922.
Causal Inference from Text: Unveiling Interactions between Variables
Nov 23, 2023Adjusting for latent covariates is crucial for estimating causal effects from observational textual data. Most existing methods only account for confounding covariates that affect both treatment and outcome, potentially leading to biased causal effects. This bias arises from insufficient consideration of non-confounding covariates, which are relevant only to either the treatment or the outcome. In this work, we aim to mitigate the bias by unveiling interactions between different variables to disentangle the non-confounding covariates when estimating causal effects from text. The disentangling process ensures covariates only contribute to their respective objectives, enabling independence between variables. Additionally, we impose a constraint to balance representations from the treatment group and control group to alleviate selection bias. We conduct experiments on two different treatment factors under various scenarios, and the proposed model significantly outperforms recent strong baselines. Furthermore, our thorough analysis on earnings call transcripts demonstrates that our model can effectively disentangle the variables, and further investigations into real-world scenarios provide guidance for investors to make informed decisions.
The Mystery and Fascination of LLMs: A Comprehensive Survey on the Interpretation and Analysis of Emergent Abilities
Nov 01, 2023

Understanding emergent abilities, such as in-context learning (ICL) and chain-of-thought (CoT) prompting in large language models (LLMs), is of utmost importance. This importance stems not only from the better utilization of these capabilities across various tasks, but also from the proactive identification and mitigation of potential risks, including concerns of truthfulness, bias, and toxicity, that may arise alongside these capabilities. In this paper, we present a thorough survey on the interpretation and analysis of emergent abilities of LLMs. First, we provide a concise introduction to the background and definition of emergent abilities. Then, we give an overview of advancements from two perspectives: 1) a macro perspective, emphasizing studies on the mechanistic interpretability and delving into the mathematical foundations behind emergent abilities; and 2) a micro-perspective, concerning studies that focus on empirical interpretability by examining factors associated with these abilities. We conclude by highlighting the challenges encountered and suggesting potential avenues for future research. We believe that our work establishes the basis for further exploration into the interpretation of emergent abilities.
RoboCat: A Self-Improving Foundation Agent for Robotic Manipulation
Jun 20, 2023



The ability to leverage heterogeneous robotic experience from different robots and tasks to quickly master novel skills and embodiments has the potential to transform robot learning. Inspired by recent advances in foundation models for vision and language, we propose a foundation agent for robotic manipulation. This agent, named RoboCat, is a visual goal-conditioned decision transformer capable of consuming multi-embodiment action-labelled visual experience. This data spans a large repertoire of motor control skills from simulated and real robotic arms with varying sets of observations and actions. With RoboCat, we demonstrate the ability to generalise to new tasks and robots, both zero-shot as well as through adaptation using only 100--1000 examples for the target task. We also show how a trained model itself can be used to generate data for subsequent training iterations, thus providing a basic building block for an autonomous improvement loop. We investigate the agent's capabilities, with large-scale evaluations both in simulation and on three different real robot embodiments. We find that as we grow and diversify its training data, RoboCat not only shows signs of cross-task transfer, but also becomes more efficient at adapting to new tasks.
Distilling ChatGPT for Explainable Automated Student Answer Assessment
May 22, 2023



Assessing student answers and providing valuable feedback is crucial for effective learning, but it can be a time-consuming task. Traditional methods of automating student answer assessment through text classification often suffer from issues such as lack of trustworthiness, transparency, and the ability to provide a rationale for the automated assessment process. These limitations hinder their usefulness in practice. In this paper, we explore using ChatGPT, a cutting-edge large language model, for the concurrent tasks of student answer scoring and rationale generation under both the zero-shot and few-shot settings. We introduce a critic module which automatically filters incorrect outputs from ChatGPT and utilizes the remaining ChtaGPT outputs as noisy labelled data to fine-tune a smaller language model, enabling it to perform student answer scoring and rationale generation. Moreover, by drawing multiple samples from ChatGPT outputs, we are able to compute predictive confidence scores, which in turn can be used to identify corrupted data and human label errors in the training set. Our experimental results demonstrate that despite being a few orders of magnitude smaller than ChatGPT, the fine-tuned language model achieves better performance in student answer scoring. Furthermore, it generates more detailed and comprehensible assessments than traditional text classification methods. Our approach provides a viable solution to achieve explainable automated assessment in education.
Lossless Adaptation of Pretrained Vision Models For Robotic Manipulation
Apr 13, 2023



Recent works have shown that large models pretrained on common visual learning tasks can provide useful representations for a wide range of specialized perception problems, as well as a variety of robotic manipulation tasks. While prior work on robotic manipulation has predominantly used frozen pretrained features, we demonstrate that in robotics this approach can fail to reach optimal performance, and that fine-tuning of the full model can lead to significantly better results. Unfortunately, fine-tuning disrupts the pretrained visual representation, and causes representational drift towards the fine-tuned task thus leading to a loss of the versatility of the original model. We introduce "lossless adaptation" to address this shortcoming of classical fine-tuning. We demonstrate that appropriate placement of our parameter efficient adapters can significantly reduce the performance gap between frozen pretrained representations and full end-to-end fine-tuning without changes to the original representation and thus preserving original capabilities of the pretrained model. We perform a comprehensive investigation across three major model architectures (ViTs, NFNets, and ResNets), supervised (ImageNet-1K classification) and self-supervised pretrained weights (CLIP, BYOL, Visual MAE) in 3 task domains and 35 individual tasks, and demonstrate that our claims are strongly validated in various settings.
How to Spend Your Robot Time: Bridging Kickstarting and Offline Reinforcement Learning for Vision-based Robotic Manipulation
May 06, 2022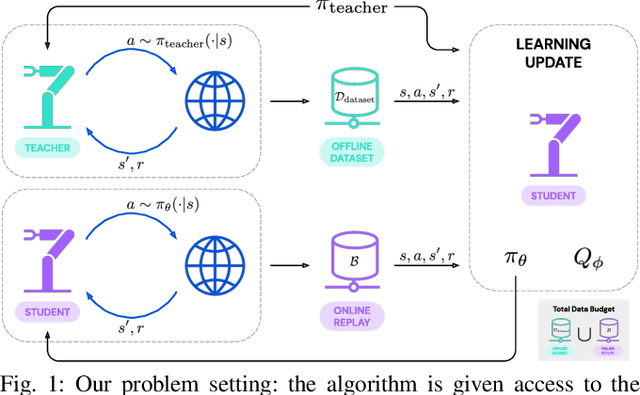

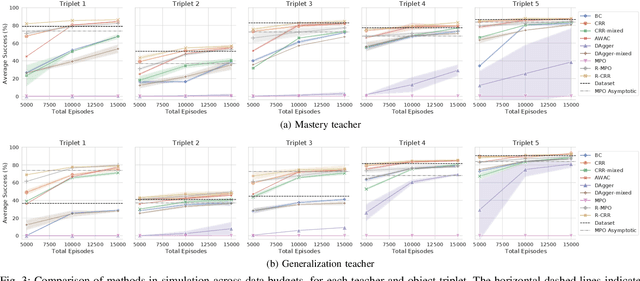
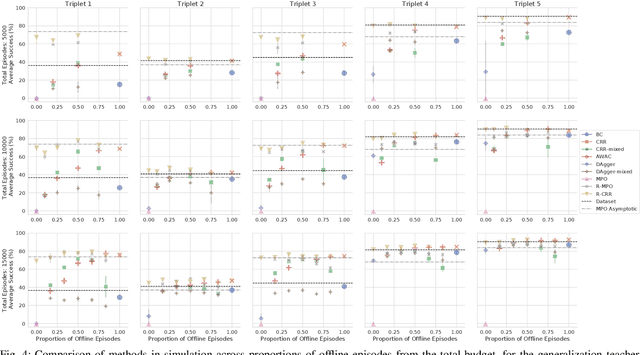
Reinforcement learning (RL) has been shown to be effective at learning control from experience. However, RL typically requires a large amount of online interaction with the environment. This limits its applicability to real-world settings, such as in robotics, where such interaction is expensive. In this work we investigate ways to minimize online interactions in a target task, by reusing a suboptimal policy we might have access to, for example from training on related prior tasks, or in simulation. To this end, we develop two RL algorithms that can speed up training by using not only the action distributions of teacher policies, but also data collected by such policies on the task at hand. We conduct a thorough experimental study of how to use suboptimal teachers on a challenging robotic manipulation benchmark on vision-based stacking with diverse objects. We compare our methods to offline, online, offline-to-online, and kickstarting RL algorithms. By doing so, we find that training on data from both the teacher and student, enables the best performance for limited data budgets. We examine how to best allocate a limited data budget -- on the target task -- between the teacher and the student policy, and report experiments using varying budgets, two teachers with different degrees of suboptimality, and five stacking tasks that require a diverse set of behaviors. Our analysis, both in simulation and in the real world, shows that our approach is the best across data budgets, while standard offline RL from teacher rollouts is surprisingly effective when enough data is given.
TCM-SD: A Large Dataset for Syndrome Differentiation in Traditional Chinese Medicine
Mar 21, 2022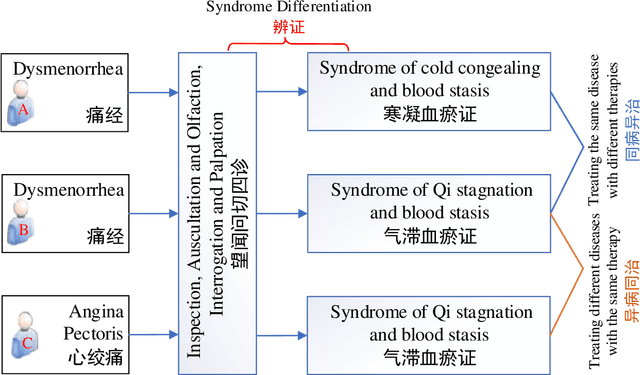
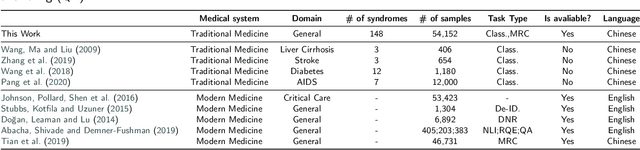

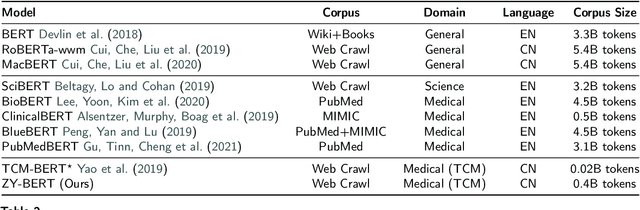
Traditional Chinese Medicine (TCM) is a natural, safe, and effective therapy that has spread and been applied worldwide. The unique TCM diagnosis and treatment system requires a comprehensive analysis of a patient's symptoms hidden in the clinical record written in free text. Prior studies have shown that this system can be informationized and intelligentized with the aid of artificial intelligence (AI) technology, such as natural language processing (NLP). However, existing datasets are not of sufficient quality nor quantity to support the further development of data-driven AI technology in TCM. Therefore, in this paper, we focus on the core task of the TCM diagnosis and treatment system -- syndrome differentiation (SD) -- and we introduce the first public large-scale dataset for SD, called TCM-SD. Our dataset contains 54,152 real-world clinical records covering 148 syndromes. Furthermore, we collect a large-scale unlabelled textual corpus in the field of TCM and propose a domain-specific pre-trained language model, called ZY-BERT. We conducted experiments using deep neural networks to establish a strong performance baseline, reveal various challenges in SD, and prove the potential of domain-specific pre-trained language model. Our study and analysis reveal opportunities for incorporating computer science and linguistics knowledge to explore the empirical validity of TCM theories.
Beyond Pick-and-Place: Tackling Robotic Stacking of Diverse Shapes
Nov 03, 2021
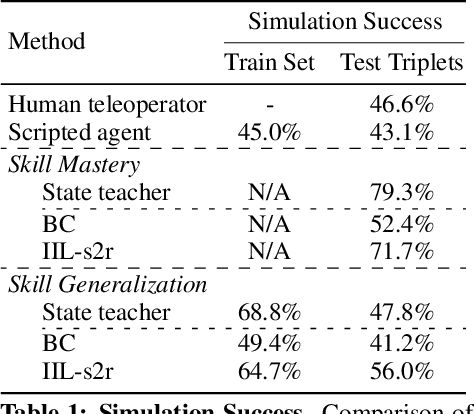
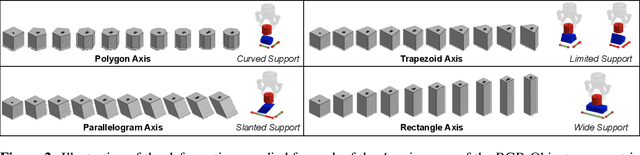
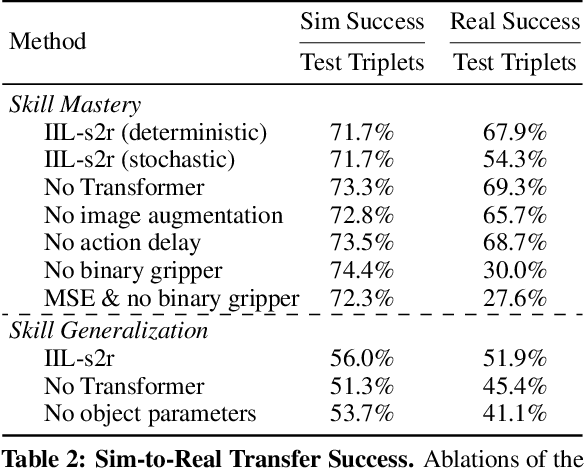
We study the problem of robotic stacking with objects of complex geometry. We propose a challenging and diverse set of such objects that was carefully designed to require strategies beyond a simple "pick-and-place" solution. Our method is a reinforcement learning (RL) approach combined with vision-based interactive policy distillation and simulation-to-reality transfer. Our learned policies can efficiently handle multiple object combinations in the real world and exhibit a large variety of stacking skills. In a large experimental study, we investigate what choices matter for learning such general vision-based agents in simulation, and what affects optimal transfer to the real robot. We then leverage data collected by such policies and improve upon them with offline RL. A video and a blog post of our work are provided as supplementary material.
To be Closer: Learning to Link up Aspects with Opinions
Sep 17, 2021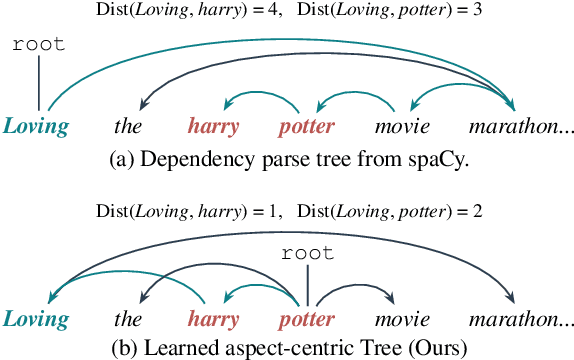
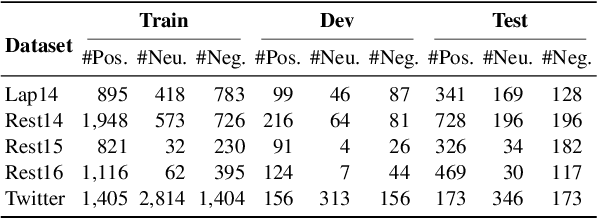
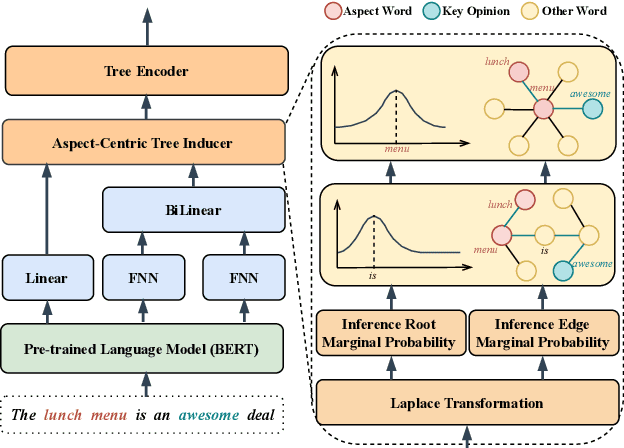
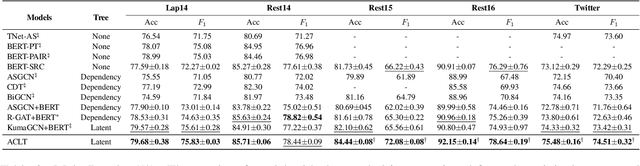
Dependency parse trees are helpful for discovering the opinion words in aspect-based sentiment analysis (ABSA). However, the trees obtained from off-the-shelf dependency parsers are static, and could be sub-optimal in ABSA. This is because the syntactic trees are not designed for capturing the interactions between opinion words and aspect words. In this work, we aim to shorten the distance between aspects and corresponding opinion words by learning an aspect-centric tree structure. The aspect and opinion words are expected to be closer along such tree structure compared to the standard dependency parse tree. The learning process allows the tree structure to adaptively correlate the aspect and opinion words, enabling us to better identify the polarity in the ABSA task. We conduct experiments on five aspect-based sentiment datasets, and the proposed model significantly outperforms recent strong baselines. Furthermore, our thorough analysis demonstrates the average distance between aspect and opinion words are shortened by at least 19% on the standard SemEval Restaurant14 dataset.