 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLVE: Scaling Up Reinforcement Learning for Language Models with Adaptive Verifiable Environments
Nov 10, 2025



We introduce Reinforcement Learning (RL) with Adaptive Verifiable Environments (RLVE), an approach using verifiable environments that procedurally generate problems and provide algorithmically verifiable rewards, to scale up RL for language models (LMs). RLVE enables each verifiable environment to dynamically adapt its problem difficulty distribution to the policy model's capabilities as training progresses. In contrast, static data distributions often lead to vanishing learning signals when problems are either too easy or too hard for the policy. To implement RLVE, we create RLVE-Gym, a large-scale suite of 400 verifiable environments carefully developed through manual environment engineering. Using RLVE-Gym, we show that environment scaling, i.e., expanding the collection of training environments, consistently improves generalizable reasoning capabilities. RLVE with joint training across all 400 environments in RLVE-Gym yields a 3.37% absolute average improvement across six reasoning benchmarks, starting from one of the strongest 1.5B reasoning LMs. By comparison, continuing this LM's original RL training yields only a 0.49% average absolute gain despite using over 3x more compute. We release our code publicly.
Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)
Oct 27, 2025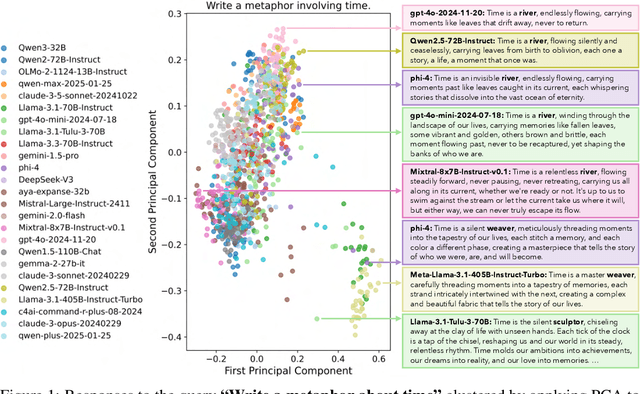
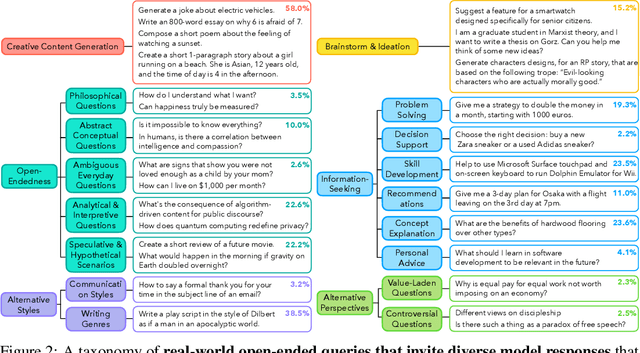
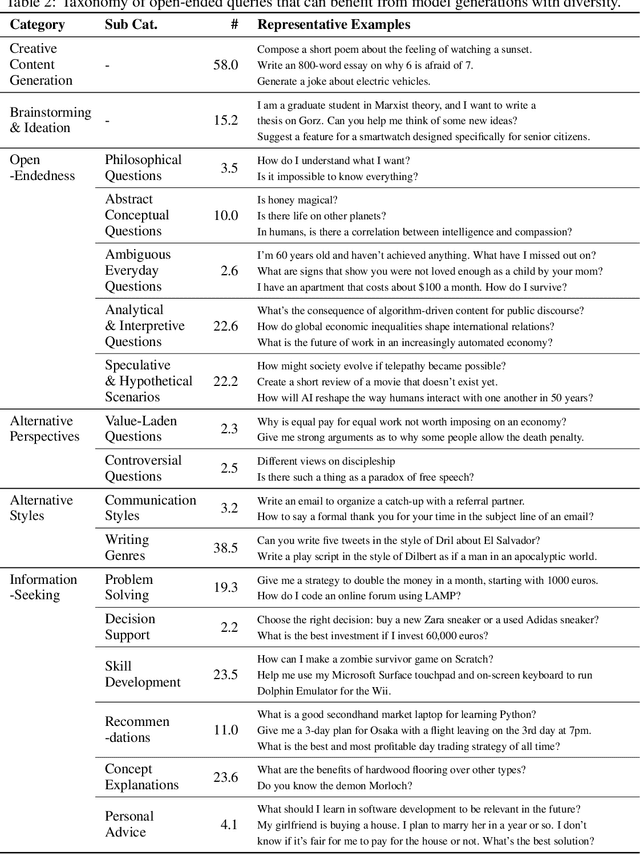
Language models (LMs) often struggle to generate diverse, human-like creative content, raising concerns about the long-term homogenization of human thought through repeated exposure to similar outputs. Yet scalable methods for evaluating LM output diversity remain limited, especially beyond narrow tasks such as random number or name generation, or beyond repeated sampling from a single model. We introduce Infinity-Chat, a large-scale dataset of 26K diverse, real-world, open-ended user queries that admit a wide range of plausible answers with no single ground truth. We introduce the first comprehensive taxonomy for characterizing the full spectrum of open-ended prompts posed to LMs, comprising 6 top-level categories (e.g., brainstorm & ideation) that further breaks down to 17 subcategories. Using Infinity-Chat, we present a large-scale study of mode collapse in LMs, revealing a pronounced Artificial Hivemind effect in open-ended generation of LMs, characterized by (1) intra-model repetition, where a single model consistently generates similar responses, and more so (2) inter-model homogeneity, where different models produce strikingly similar outputs. Infinity-Chat also includes 31,250 human annotations, across absolute ratings and pairwise preferences, with 25 independent human annotations per example. This enables studying collective and individual-specific human preferences in response to open-ended queries. Our findings show that LMs, reward models, and LM judges are less well calibrated to human ratings on model generations that elicit differing idiosyncratic annotator preferences, despite maintaining comparable overall quality. Overall, INFINITY-CHAT presents the first large-scale resource for systematically studying real-world open-ended queries to LMs, revealing critical insights to guide future research for mitigating long-term AI safety risks posed by the Artificial Hivemind.
PrefPalette: Personalized Preference Modeling with Latent Attributes
Jul 17, 2025



Personalizing AI systems requires understanding not just what users prefer, but the reasons that underlie those preferences - yet current preference models typically treat human judgment as a black box. We introduce PrefPalette, a framework that decomposes preferences into attribute dimensions and tailors its preference prediction to distinct social community values in a human-interpretable manner. PrefPalette operationalizes a cognitive science principle known as multi-attribute decision making in two ways: (1) a scalable counterfactual attribute synthesis step that involves generating synthetic training data to isolate for individual attribute effects (e.g., formality, humor, cultural values), and (2) attention-based preference modeling that learns how different social communities dynamically weight these attributes. This approach moves beyond aggregate preference modeling to capture the diverse evaluation frameworks that drive human judgment. When evaluated on 45 social communities from the online platform Reddit, PrefPalette outperforms GPT-4o by 46.6% in average prediction accuracy. Beyond raw predictive improvements, PrefPalette also shed light on intuitive, community-specific profiles: scholarly communities prioritize verbosity and stimulation, conflict-oriented communities value sarcasm and directness, and support-based communities emphasize empathy. By modeling the attribute-mediated structure of human judgment, PrefPalette delivers both superior preference modeling and transparent, interpretable insights, and serves as a first step toward more trustworthy, value-aware personalized applications.
Spurious Rewards: Rethinking Training Signals in RLVR
Jun 12, 2025



We show that reinforcement learning with verifiable rewards (RLVR) can elicit strong mathematical reasoning in certain models even with spurious rewards that have little, no, or even negative correlation with the correct answer. For example, RLVR improves MATH-500 performance for Qwen2.5-Math-7B in absolute points by 21.4% (random reward), 13.8% (format reward), 24.1% (incorrect label), 26.0% (1-shot RL), and 27.1% (majority voting) -- nearly matching the 29.1% gained with ground truth rewards. However, the spurious rewards that work for Qwen often fail to yield gains with other model families like Llama3 or OLMo2. In particular, we find code reasoning -- thinking in code without actual code execution -- to be a distinctive Qwen2.5-Math behavior that becomes significantly more frequent after RLVR, from 65% to over 90%, even with spurious rewards. Overall, we hypothesize that, given the lack of useful reward signal, RLVR must somehow be surfacing useful reasoning representations learned during pretraining, although the exact mechanism remains a topic for future work. We suggest that future RLVR research should possibly be validated on diverse models rather than a single de facto choice, as we show that it is easy to get significant performance gains on Qwen models even with completely spurious reward signals.
MADFormer: Mixed Autoregressive and Diffusion Transformers for Continuous Image Generation
Jun 09, 2025



Recent progress in multimodal generation has increasingly combined autoregressive (AR) and diffusion-based approaches, leveraging their complementary strengths: AR models capture long-range dependencies and produce fluent, context-aware outputs, while diffusion models operate in continuous latent spaces to refine high-fidelity visual details. However, existing hybrids often lack systematic guidance on how and why to allocate model capacity between these paradigms. In this work, we introduce MADFormer, a Mixed Autoregressive and Diffusion Transformer that serves as a testbed for analyzing AR-diffusion trade-offs. MADFormer partitions image generation into spatial blocks, using AR layers for one-pass global conditioning across blocks and diffusion layers for iterative local refinement within each block. Through controlled experiments on FFHQ-1024 and ImageNet, we identify two key insights: (1) block-wise partitioning significantly improves performance on high-resolution images, and (2) vertically mixing AR and diffusion layers yields better quality-efficiency balances--improving FID by up to 75% under constrained inference compute. Our findings offer practical design principles for future hybrid generative models.
Precise Information Control in Long-Form Text Generation
Jun 06, 2025A central challenge in modern language models (LMs) is intrinsic hallucination: the generation of information that is plausible but unsubstantiated relative to input context. To study this problem, we propose Precise Information Control (PIC), a new task formulation that requires models to generate long-form outputs grounded in a provided set of short self-contained statements, known as verifiable claims, without adding any unsupported ones. For comprehensiveness, PIC includes a full setting that tests a model's ability to include exactly all input claims, and a partial setting that requires the model to selectively incorporate only relevant claims. We present PIC-Bench, a benchmark of eight long-form generation tasks (e.g., summarization, biography generation) adapted to the PIC setting, where LMs are supplied with well-formed, verifiable input claims. Our evaluation of a range of open and proprietary LMs on PIC-Bench reveals that, surprisingly, state-of-the-art LMs still intrinsically hallucinate in over 70% of outputs. To alleviate this lack of faithfulness, we introduce a post-training framework, using a weakly supervised preference data construction method, to train an 8B PIC-LM with stronger PIC ability--improving from 69.1% to 91.0% F1 in the full PIC setting. When integrated into end-to-end factual generation pipelines, PIC-LM improves exact match recall by 17.1% on ambiguous QA with retrieval, and factual precision by 30.5% on a birthplace verification task, underscoring the potential of precisely grounded generation.
SPARTA ALIGNMENT: Collectively Aligning Multiple Language Models through Combat
Jun 05, 2025We propose SPARTA ALIGNMENT, an algorithm to collectively align multiple LLMs through competition and combat. To complement a single model's lack of diversity in generation and biases in evaluation, multiple LLMs form a "sparta tribe" to compete against each other in fulfilling instructions while serving as judges for the competition of others. For each iteration, one instruction and two models are selected for a duel, the other models evaluate the two responses, and their evaluation scores are aggregated through a adapted elo-ranking based reputation system, where winners/losers of combat gain/lose weight in evaluating others. The peer-evaluated combat results then become preference pairs where the winning response is preferred over the losing one, and all models learn from these preferences at the end of each iteration. SPARTA ALIGNMENT enables the self-evolution of multiple LLMs in an iterative and collective competition process. Extensive experiments demonstrate that SPARTA ALIGNMENT outperforms initial models and 4 self-alignment baselines across 10 out of 12 tasks and datasets with 7.0% average improvement. Further analysis reveals that SPARTA ALIGNMENT generalizes more effectively to unseen tasks and leverages the expertise diversity of participating models to produce more logical, direct and informative outputs.
ScienceMeter: Tracking Scientific Knowledge Updates in Language Models
May 30, 2025



Large Language Models (LLMs) are increasingly used to support scientific research, but their knowledge of scientific advancements can quickly become outdated. We introduce ScienceMeter, a new framework for evaluating scientific knowledge update methods over scientific knowledge spanning the past, present, and future. ScienceMeter defines three metrics: knowledge preservation, the extent to which models' understanding of previously learned papers are preserved; knowledge acquisition, how well scientific claims from newly introduced papers are acquired; and knowledge projection, the ability of the updated model to anticipate or generalize to related scientific claims that may emerge in the future. Using ScienceMeter, we examine the scientific knowledge of LLMs on claim judgment and generation tasks across a curated dataset of 15,444 scientific papers and 30,888 scientific claims from ten domains including medicine, biology, materials science, and computer science. We evaluate five representative knowledge update approaches including training- and inference-time methods. With extensive experiments, we find that the best-performing knowledge update methods can preserve only 85.9% of existing knowledge, acquire 71.7% of new knowledge, and project 37.7% of future knowledge. Inference-based methods work for larger models, whereas smaller models require training to achieve comparable performance. Cross-domain analysis reveals that performance on these objectives is correlated. Even when applying on specialized scientific LLMs, existing knowledge update methods fail to achieve these objectives collectively, underscoring that developing robust scientific knowledge update mechanisms is both crucial and challenging.
MMMG: a Comprehensive and Reliable Evaluation Suite for Multitask Multimodal Generation
May 23, 2025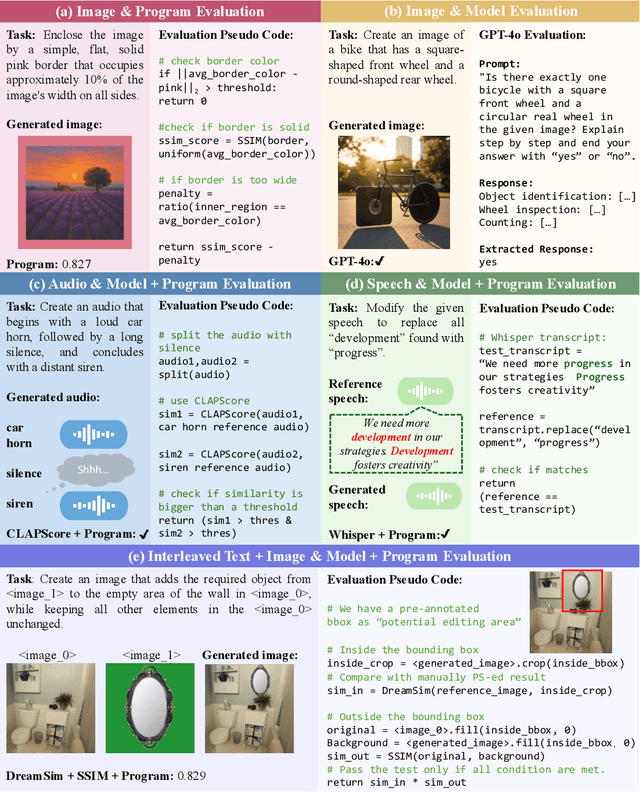
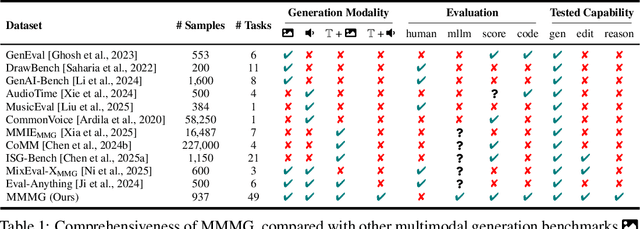
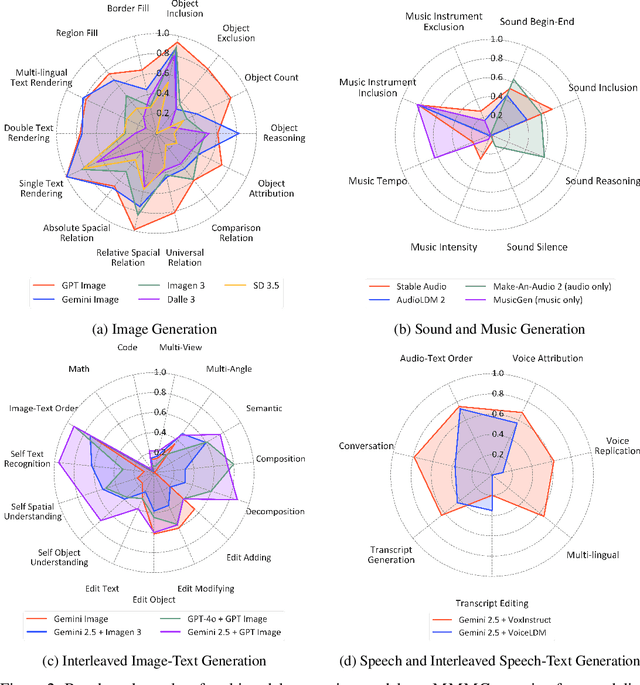
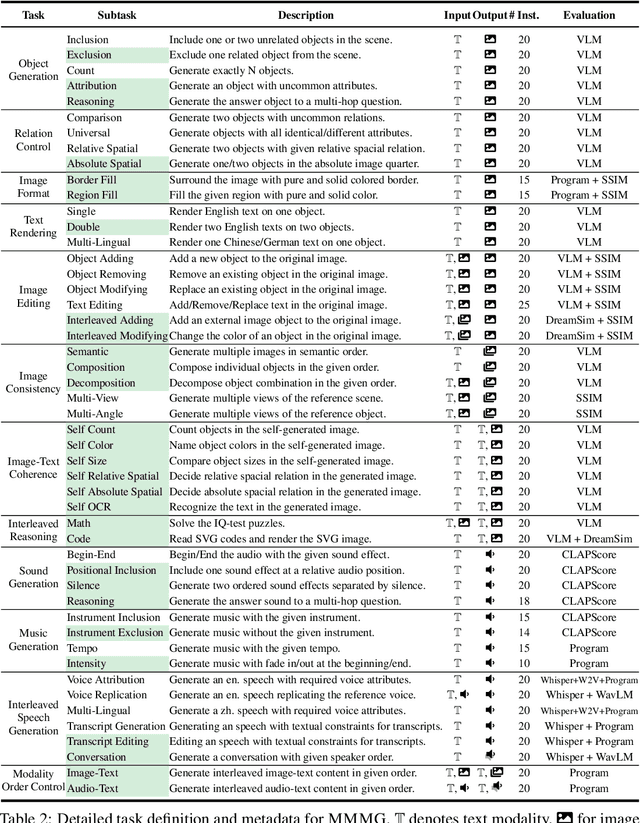
Automatically evaluating multimodal generation presents a significant challenge, as automated metrics often struggle to align reliably with human evaluation, especially for complex tasks that involve multiple modalities. To address this, we present MMMG, a comprehensive and human-aligned benchmark for multimodal generation across 4 modality combinations (image, audio, interleaved text and image, interleaved text and audio), with a focus on tasks that present significant challenges for generation models, while still enabling reliable automatic evaluation through a combination of models and programs. MMMG encompasses 49 tasks (including 29 newly developed ones), each with a carefully designed evaluation pipeline, and 937 instructions to systematically assess reasoning, controllability, and other key capabilities of multimodal generation models. Extensive validation demonstrates that MMMG is highly aligned with human evaluation, achieving an average agreement of 94.3%. Benchmarking results on 24 multimodal generation models reveal that even though the state-of-the-art model, GPT Image, achieves 78.3% accuracy for image generation, it falls short on multimodal reasoning and interleaved generation. Furthermore, results suggest considerable headroom for improvement in audio generation, highlighting an important direction for future research.
BLAB: Brutally Long Audio Bench
May 05, 2025Developing large audio language models (LMs) capable of understanding diverse spoken interactions is essential for accommodating the multimodal nature of human communication and can increase the accessibility of language technologies across different user populations. Recent work on audio LMs has primarily evaluated their performance on short audio segments, typically under 30 seconds, with limited exploration of long-form conversational speech segments that more closely reflect natural user interactions with these models. We introduce Brutally Long Audio Bench (BLAB), a challenging long-form audio benchmark that evaluates audio LMs on localization, duration estimation, emotion, and counting tasks using audio segments averaging 51 minutes in length. BLAB consists of 833+ hours of diverse, full-length audio clips, each paired with human-annotated, text-based natural language questions and answers. Our audio data were collected from permissively licensed sources and underwent a human-assisted filtering process to ensure task compliance. We evaluate six open-source and proprietary audio LMs on BLAB and find that all of them, including advanced models such as Gemini 2.0 Pro and GPT-4o, struggle with the tasks in BLAB. Our comprehensive analysis reveals key insights into the trade-offs between task difficulty and audio duration. In general, we find that audio LMs struggle with long-form speech, with performance declining as duration increases. They perform poorly on localization, temporal reasoning, counting, and struggle to understand non-phonemic information, relying more on prompts than audio content. BLAB serves as a challenging evaluation framework to develop audio LMs with robust long-form audio understanding capabilities.