 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Episodic Control with State Abstraction
Jan 27, 2023Existing Deep Reinforcement Learning (DRL) algorithms suffer from sample inefficiency. Generally, episodic control-based approaches are solutions that leverage highly-rewarded past experiences to improve sample efficiency of DRL algorithms. However, previous episodic control-based approaches fail to utilize the latent information from the historical behaviors (e.g., state transitions, topological similarities, etc.) and lack scalability during DRL training. This work introduces Neural Episodic Control with State Abstraction (NECSA), a simple but effective state abstraction-based episodic control containing a more comprehensive episodic memory, a novel state evaluation, and a multi-step state analysis. We evaluate our approach to the MuJoCo and Atari tasks in OpenAI gym domains. The experimental results indicate that NECSA achieves higher sample efficiency than the state-of-the-art episodic control-based approaches. Our data and code are available at the project website\footnote{\url{https://sites.google.com/view/drl-necsa}}.
EUCLID: Towards Efficient Unsupervised Reinforcement Learning with Multi-choice Dynamics Model
Oct 02, 2022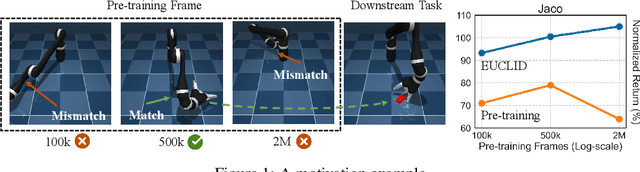
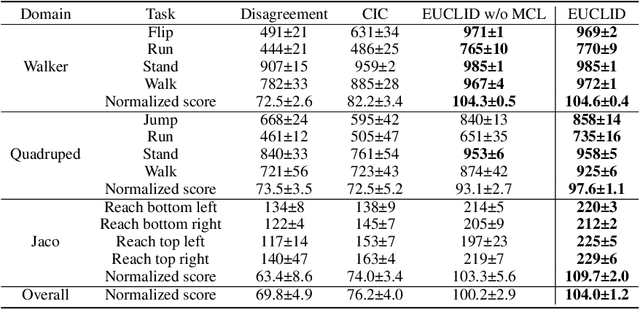
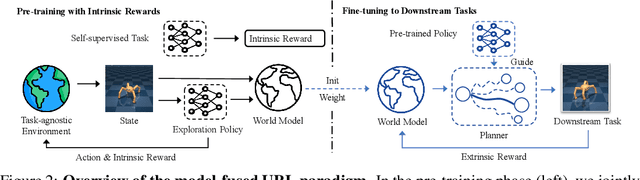
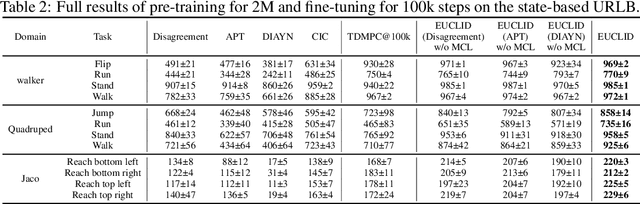
Unsupervised reinforcement learning (URL) poses a promising paradigm to learn useful behaviors in a task-agnostic environment without the guidance of extrinsic rewards to facilitate the fast adaptation of various downstream tasks. Previous works focused on the pre-training in a model-free manner while lacking the study of transition dynamics modeling that leaves a large space for the improvement of sample efficiency in downstream tasks. To this end, we propose an Efficient Unsupervised Reinforcement Learning Framework with Multi-choice Dynamics model (EUCLID), which introduces a novel model-fused paradigm to jointly pre-train the dynamics model and unsupervised exploration policy in the pre-training phase, thus better leveraging the environmental samples and improving the downstream task sampling efficiency. However, constructing a generalizable model which captures the local dynamics under different behaviors remains a challenging problem. We introduce the multi-choice dynamics model that covers different local dynamics under different behaviors concurrently, which uses different heads to learn the state transition under different behaviors during unsupervised pre-training and selects the most appropriate head for prediction in the downstream task. Experimental results in the manipulation and locomotion domains demonstrate that EUCLID achieves state-of-the-art performance with high sample efficiency, basically solving the state-based URLB benchmark and reaching a mean normalized score of 104.0$\pm$1.2$\%$ in downstream tasks with 100k fine-tuning steps, which is equivalent to DDPG's performance at 2M interactive steps with 20x more data.
Distributed Multi-Robot Obstacle Avoidance via Logarithmic Map-based Deep Reinforcement Learning
Sep 14, 2022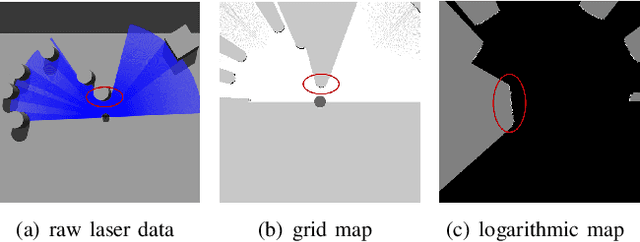

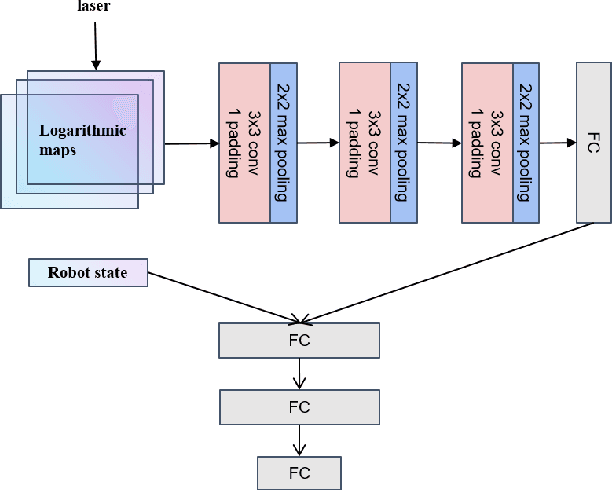
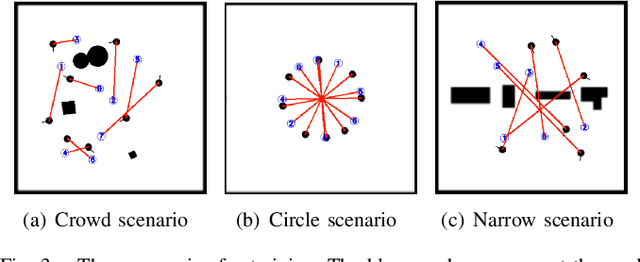
Developing a safe, stable, and efficient obstacle avoidance policy in crowded and narrow scenarios for multiple robots is challenging. Most existing studies either use centralized control or need communication with other robots. In this paper, we propose a novel logarithmic map-based deep reinforcement learning method for obstacle avoidance in complex and communication-free multi-robot scenarios. In particular, our method converts laser information into a logarithmic map. As a step toward improving training speed and generalization performance, our policies will be trained in two specially designed multi-robot scenarios. Compared to other methods, the logarithmic map can represent obstacles more accurately and improve the success rate of obstacle avoidance. We finally evaluate our approach under a variety of simulation and real-world scenarios. The results show that our method provides a more stable and effective navigation solution for robots in complex multi-robot scenarios and pedestrian scenarios. Videos are available at https://youtu.be/r0EsUXe6MZE.
Automatic Reward Design via Learning Motivation-Consistent Intrinsic Rewards
Jul 29, 2022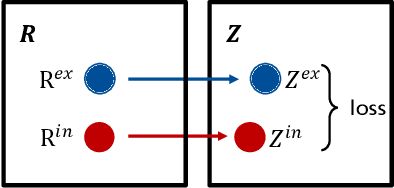


Reward design is a critical part of the application of reinforcement learning, the performance of which strongly depends on how well the reward signal frames the goal of the designer and how well the signal assesses progress in reaching that goal. In many cases, the extrinsic rewards provided by the environment (e.g., win or loss of a game) are very sparse and make it difficult to train agents directly. Researchers usually assist the learning of agents by adding some auxiliary rewards in practice. However, designing auxiliary rewards is often turned to a trial-and-error search for reward settings that produces acceptable results. In this paper, we propose to automatically generate goal-consistent intrinsic rewards for the agent to learn, by maximizing which the expected accumulative extrinsic rewards can be maximized. To this end, we introduce the concept of motivation which captures the underlying goal of maximizing certain rewards and propose the motivation based reward design method. The basic idea is to shape the intrinsic rewards by minimizing the distance between the intrinsic and extrinsic motivations. We conduct extensive experiments and show that our method performs better than the state-of-the-art methods in handling problems of delayed reward, exploration, and credit assignment.
Off-Beat Multi-Agent Reinforcement Learning
May 27, 2022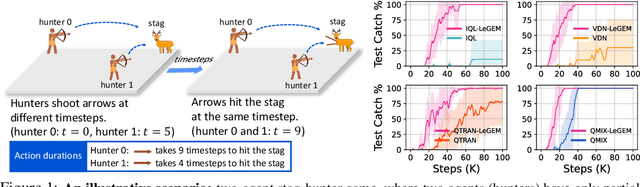
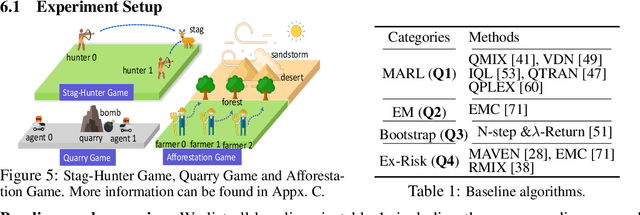

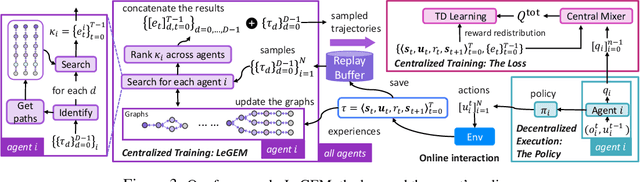
We investigate model-free multi-agent reinforcement learning (MARL) in environments where off-beat actions are prevalent, i.e., all actions have pre-set execution durations. During execution durations, the environment changes are influenced by, but not synchronised with, action execution. Such a setting is ubiquitous in many real-world problems. However, most MARL methods assume actions are executed immediately after inference, which is often unrealistic and can lead to catastrophic failure for multi-agent coordination with off-beat actions. In order to fill this gap, we develop an algorithmic framework for MARL with off-beat actions. We then propose a novel episodic memory, LeGEM, for model-free MARL algorithms. LeGEM builds agents' episodic memories by utilizing agents' individual experiences. It boosts multi-agent learning by addressing the challenging temporal credit assignment problem raised by the off-beat actions via our novel reward redistribution scheme, alleviating the issue of non-Markovian reward. We evaluate LeGEM on various multi-agent scenarios with off-beat actions, including Stag-Hunter Game, Quarry Game, Afforestation Game, and StarCraft II micromanagement tasks. Empirical results show that LeGEM significantly boosts multi-agent coordination and achieves leading performance and improved sample efficiency.
Episodic Multi-agent Reinforcement Learning with Curiosity-Driven Exploration
Nov 22, 2021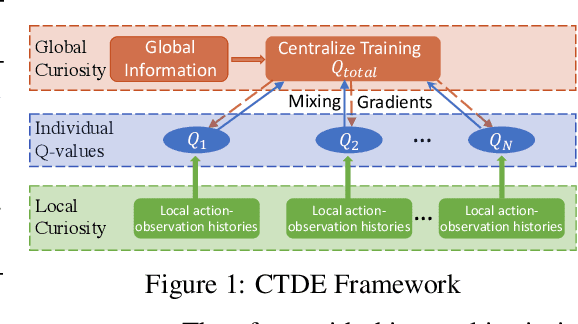
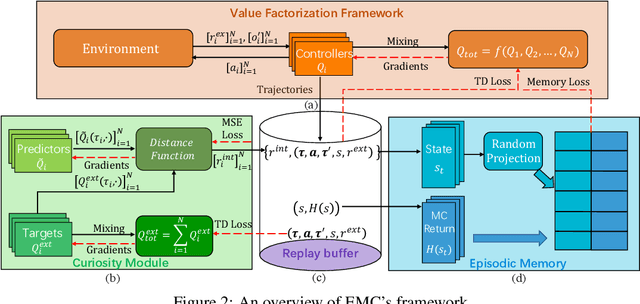

Efficient exploration in deep cooperative multi-agent reinforcement learning (MARL) still remains challenging in complex coordination problems. In this paper, we introduce a novel Episodic Multi-agent reinforcement learning with Curiosity-driven exploration, called EMC. We leverage an insight of popular factorized MARL algorithms that the "induced" individual Q-values, i.e., the individual utility functions used for local execution, are the embeddings of local action-observation histories, and can capture the interaction between agents due to reward backpropagation during centralized training. Therefore, we use prediction errors of individual Q-values as intrinsic rewards for coordinated exploration and utilize episodic memory to exploit explored informative experience to boost policy training. As the dynamics of an agent's individual Q-value function captures the novelty of states and the influence from other agents, our intrinsic reward can induce coordinated exploration to new or promising states. We illustrate the advantages of our method by didactic examples, and demonstrate its significant outperformance over state-of-the-art MARL baselines on challenging tasks in the StarCraft II micromanagement benchmark.
Unifying Behavioral and Response Diversity for Open-ended Learning in Zero-sum Games
Jun 10, 2021
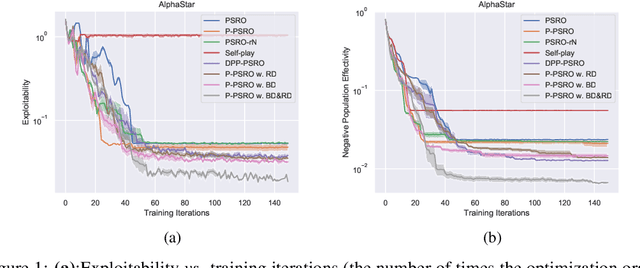
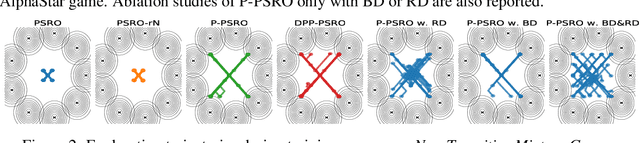
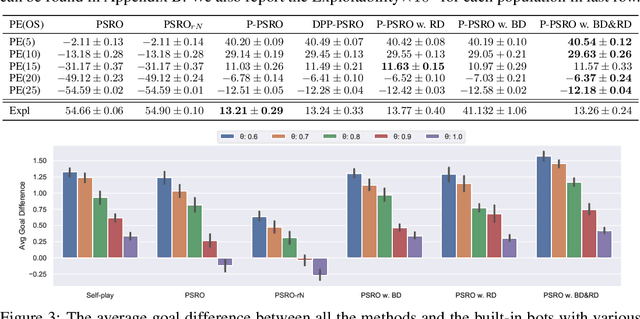
Measuring and promoting policy diversity is critical for solving games with strong non-transitive dynamics where strategic cycles exist, and there is no consistent winner (e.g., Rock-Paper-Scissors). With that in mind, maintaining a pool of diverse policies via open-ended learning is an attractive solution, which can generate auto-curricula to avoid being exploited. However, in conventional open-ended learning algorithms, there are no widely accepted definitions for diversity, making it hard to construct and evaluate the diverse policies. In this work, we summarize previous concepts of diversity and work towards offering a unified measure of diversity in multi-agent open-ended learning to include all elements in Markov games, based on both Behavioral Diversity (BD) and Response Diversity (RD). At the trajectory distribution level, we re-define BD in the state-action space as the discrepancies of occupancy measures. For the reward dynamics, we propose RD to characterize diversity through the responses of policies when encountering different opponents. We also show that many current diversity measures fall in one of the categories of BD or RD but not both. With this unified diversity measure, we design the corresponding diversity-promoting objective and population effectivity when seeking the best responses in open-ended learning. We validate our methods in both relatively simple games like matrix game, non-transitive mixture model, and the complex \textit{Google Research Football} environment. The population found by our methods reveals the lowest exploitability, highest population effectivity in matrix game and non-transitive mixture model, as well as the largest goal difference when interacting with opponents of various levels in \textit{Google Research Football}.
Fever Basketball: A Complex, Flexible, and Asynchronized Sports Game Environment for Multi-agent Reinforcement Learning
Dec 06, 2020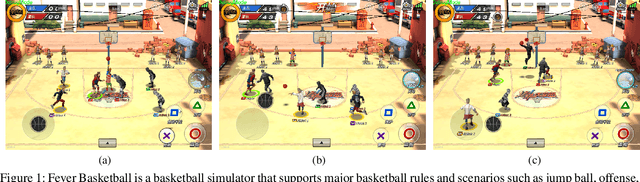
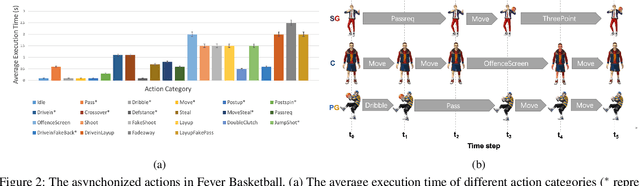
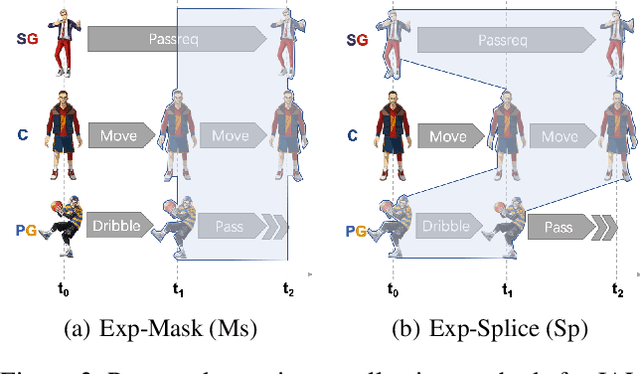
The development of deep reinforcement learning (DRL) has benefited from the emergency of a variety type of game environments where new challenging problems are proposed and new algorithms can be tested safely and quickly, such as Board games, RTS, FPS, and MOBA games. However, many existing environments lack complexity and flexibility and assume the actions are synchronously executed in multi-agent settings, which become less valuable. We introduce the Fever Basketball game, a novel reinforcement learning environment where agents are trained to play basketball game. It is a complex and challenging environment that supports multiple characters, multiple positions, and both the single-agent and multi-agent player control modes. In addition, to better simulate real-world basketball games, the execution time of actions differs among players, which makes Fever Basketball a novel asynchronized environment. We evaluate commonly used multi-agent algorithms of both independent learners and joint-action learners in three game scenarios with varying difficulties, and heuristically propose two baseline methods to diminish the extra non-stationarity brought by asynchronism in Fever Basketball Benchmarks. Besides, we propose an integrated curricula training (ICT) framework to better handle Fever Basketball problems, which includes several game-rule based cascading curricula learners and a coordination curricula switcher focusing on enhancing coordination within the team. The results show that the game remains challenging and can be used as a benchmark environment for studies like long-time horizon, sparse rewards, credit assignment, and non-stationarity, etc. in multi-agent settings.
Learning to Utilize Shaping Rewards: A New Approach of Reward Shaping
Nov 05, 2020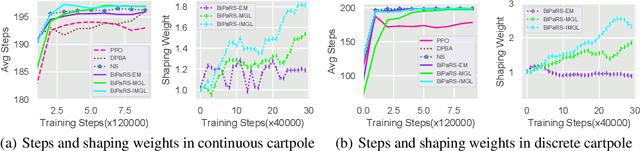
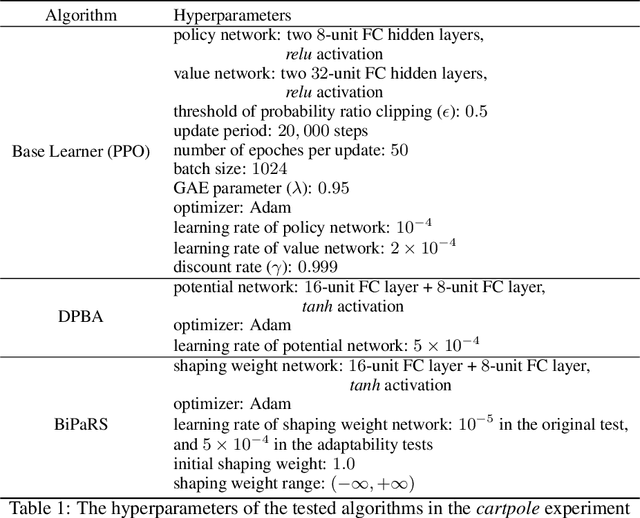

Reward shaping is an effective technique for incorporating domain knowledge into reinforcement learning (RL). Existing approaches such as potential-based reward shaping normally make full use of a given shaping reward function. However, since the transformation of human knowledge into numeric reward values is often imperfect due to reasons such as human cognitive bias, completely utilizing the shaping reward function may fail to improve the performance of RL algorithms. In this paper, we consider the problem of adaptively utilizing a given shaping reward function. We formulate the utilization of shaping rewards as a bi-level optimization problem, where the lower level is to optimize policy using the shaping rewards and the upper level is to optimize a parameterized shaping weight function for true reward maximization. We formally derive the gradient of the expected true reward with respect to the shaping weight function parameters and accordingly propose three learning algorithms based on different assumptions. Experiments in sparse-reward cartpole and MuJoCo environments show that our algorithms can fully exploit beneficial shaping rewards, and meanwhile ignore unbeneficial shaping rewards or even transform them into beneficial ones.
Exploring Unknown States with Action Balance
Mar 10, 2020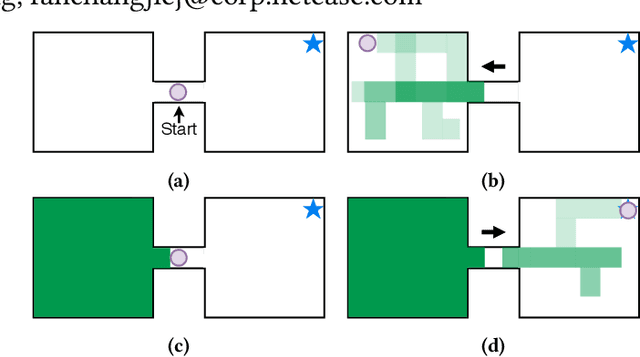
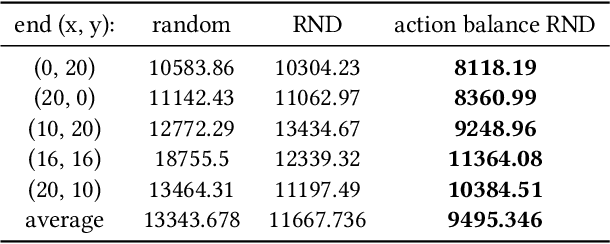
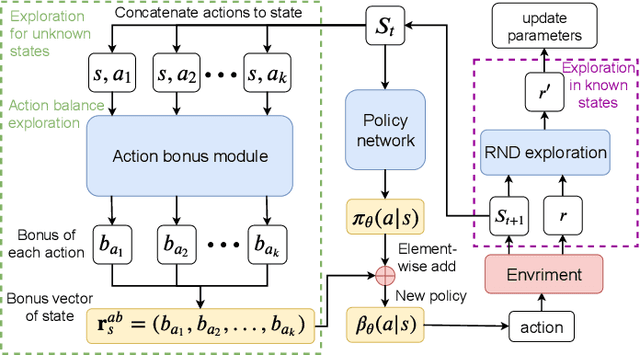
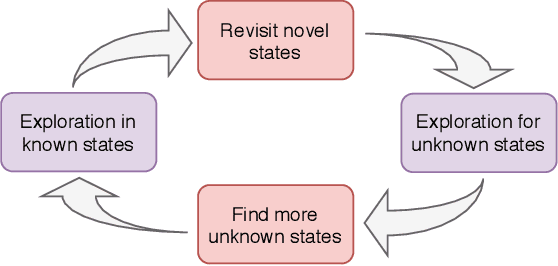
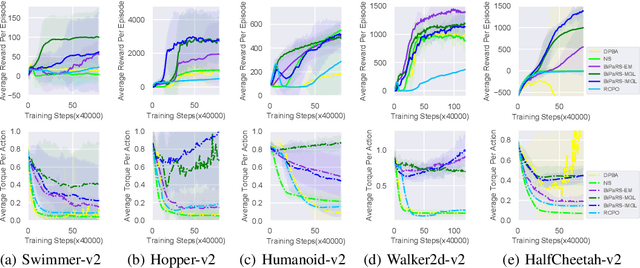
Exploration is a key problem in reinforcement learning. Recently bonus-based methods have achieved considerable successes in environments where exploration is difficult such as Montezuma's Revenge, which assign additional bonus (e.g., intrinsic reward) to guide the agent to rarely visited states. Since the bonus is calculated according to the novelty of the next state after performing an action, we call such methods the next-state bonus methods. However, the next-state bonus methods bring extra issues. It may lead agent to be trapped in states that fewer being visited and ignore to explore unknown states. Moreover, the behavior policy of the agent is also influenced by the bonus added to the state (or state-action) values indirectly. In contrast to the bonus-based methods which explore in known states, in this paper, we focus on the other part of exploration: exploration for finding unknown states. We propose the action balance exploration method to overcome the defects of the next-state bonus methods, which balances the chosen time of each action in each state and can be treated as an extension of upper confidence bound (UCB) to deep reinforcement learning. To take both the advantages of the next-state bonus method and our action balance exploration method, we propose the action balance RND method, which takes both parts of exploration into consideration. The experiments on grid world and Atari games demonstrate action balance exploration has a better capability in finding unknown states and can improve the real performance of RND in some hard exploration environments respectively.