 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Transferable Graph Exploration
Oct 28, 2019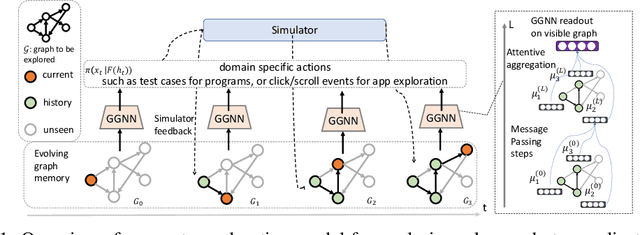
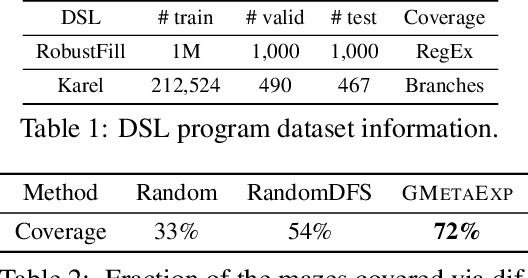


This paper considers the problem of efficient exploration of unseen environments, a key challenge in AI. We propose a `learning to explore' framework where we learn a policy from a distribution of environments. At test time, presented with an unseen environment from the same distribution, the policy aims to generalize the exploration strategy to visit the maximum number of unique states in a limited number of steps. We particularly focus on environments with graph-structured state-spaces that are encountered in many important real-world applications like software testing and map building. We formulate this task as a reinforcement learning problem where the `exploration' agent is rewarded for transitioning to previously unseen environment states and employ a graph-structured memory to encode the agent's past trajectory. Experimental results demonstrate that our approach is extremely effective for exploration of spatial maps; and when applied on the challenging problems of coverage-guided software-testing of domain-specific programs and real-world mobile applications, it outperforms methods that have been hand-engineered by human experts.
Efficient Graph Generation with Graph Recurrent Attention Networks
Oct 02, 2019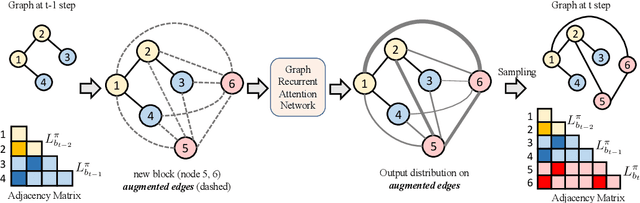
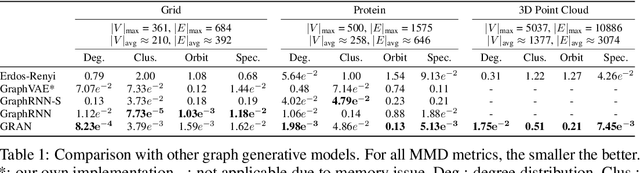
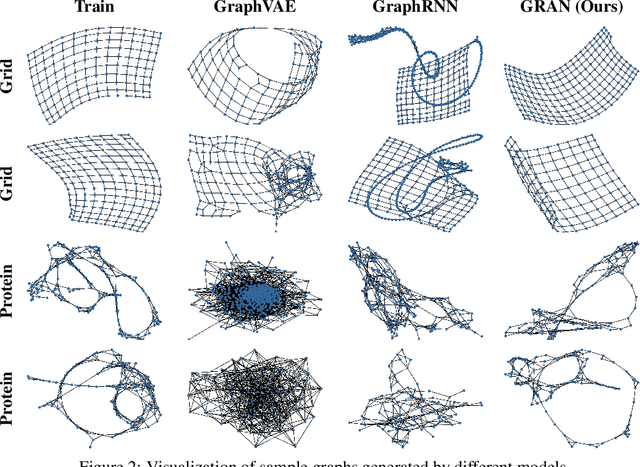
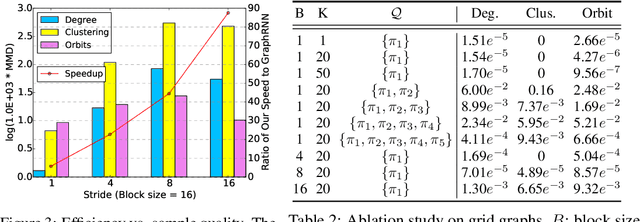
We propose a new family of efficient and expressive deep generative models of graphs, called Graph Recurrent Attention Networks (GRANs). Our model generates graphs one block of nodes and associated edges at a time. The block size and sampling stride allow us to trade off sample quality for efficiency. Compared to previous RNN-based graph generative models, our framework better captures the auto-regressive conditioning between the already-generated and to-be-generated parts of the graph using Graph Neural Networks (GNNs) with attention. This not only reduces the dependency on node ordering but also bypasses the long-term bottleneck caused by the sequential nature of RNNs. Moreover, we parameterize the output distribution per block using a mixture of Bernoulli, which captures the correlations among generated edges within the block. Finally, we propose to handle node orderings in generation by marginalizing over a family of canonical orderings. On standard benchmarks, we achieve state-of-the-art time efficiency and sample quality compared to previous models. Additionally, we show our model is capable of generating large graphs of up to 5K nodes with good quality. To the best of our knowledge, GRAN is the first deep graph generative model that can scale to this size. Our code is released at: https://github.com/lrjconan/GRAN.
Graph Convolutional Transformer: Learning the Graphical Structure of Electronic Health Records
Jun 28, 2019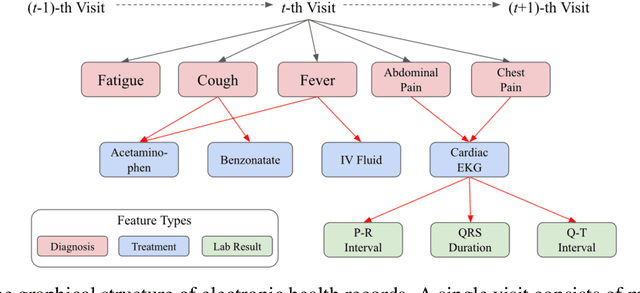

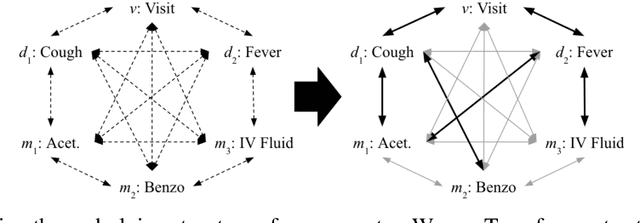
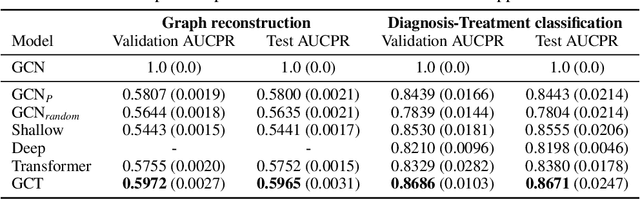
Effective modeling of electronic health records (EHR) is rapidly becoming an important topic in both academia and industry. A recent study showed that utilizing the graphical structure underlying EHR data (e.g. relationship between diagnoses and treatments) improves the performance of prediction tasks such as heart failure diagnosis prediction. However, EHR data do not always contain complete structure information. Moreover, when it comes to claims data, structure information is completely unavailable to begin with. Under such circumstances, can we still do better than just treating EHR data as a flat-structured bag-of-features? In this paper, we study the possibility of utilizing the implicit structure of EHR by using the Transformer for prediction tasks on EHR data. Specifically, we argue that the Transformer is a suitable model to learn the hidden EHR structure, and propose the Graph Convolutional Transformer, which uses data statistics to guide the structure learning process. Our model empirically demonstrated superior prediction performance to previous approaches on both synthetic data and publicly available EHR data on encounter-based prediction tasks such as graph reconstruction and readmission prediction, indicating that it can serve as an effective general-purpose representation learning algorithm for EHR data.
Fast Training of Sparse Graph Neural Networks on Dense Hardware
Jun 27, 2019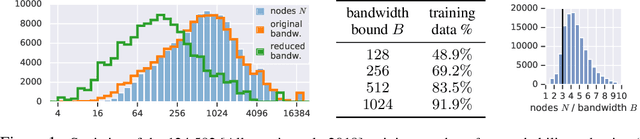

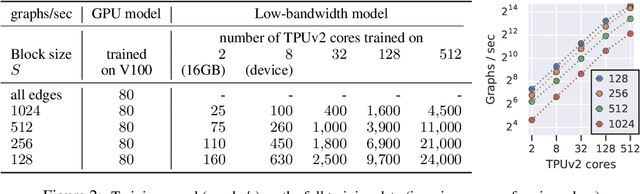
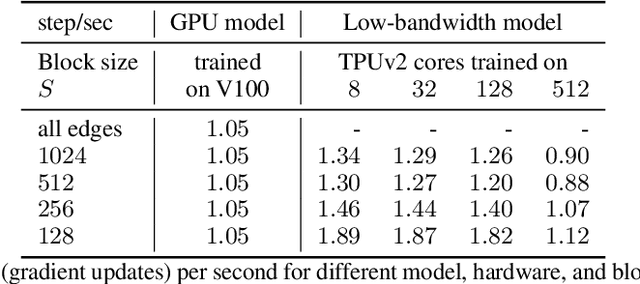
Graph neural networks have become increasingly popular in recent years due to their ability to naturally encode relational input data and their ability to scale to large graphs by operating on a sparse representation of graph adjacency matrices. As we look to scale up these models using custom hardware, a natural assumption would be that we need hardware tailored to sparse operations and/or dynamic control flow. In this work, we question this assumption by scaling up sparse graph neural networks using a platform targeted at dense computation on fixed-size data. Drawing inspiration from optimization of numerical algorithms on sparse matrices, we develop techniques that enable training the sparse graph neural network model from Allamanis et al. [2018] in 13 minutes using a 512-core TPUv2 Pod, whereas the original training takes almost a day.
REGAL: Transfer Learning For Fast Optimization of Computation Graphs
May 30, 2019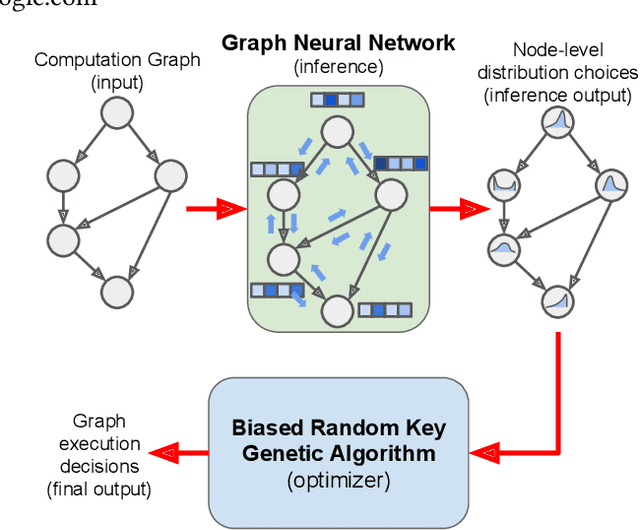
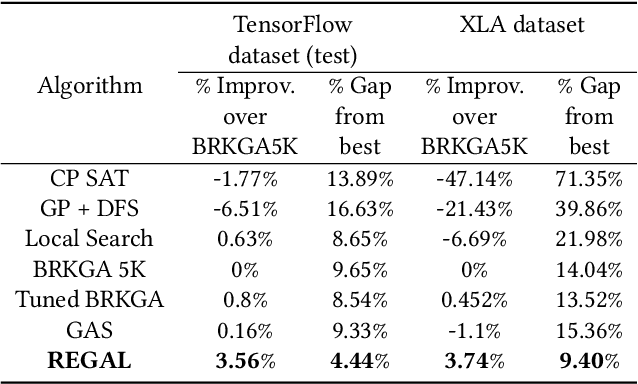
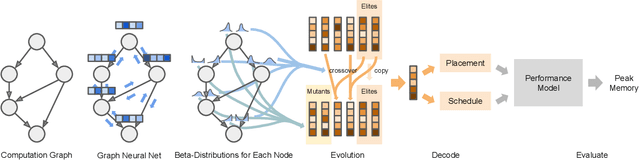
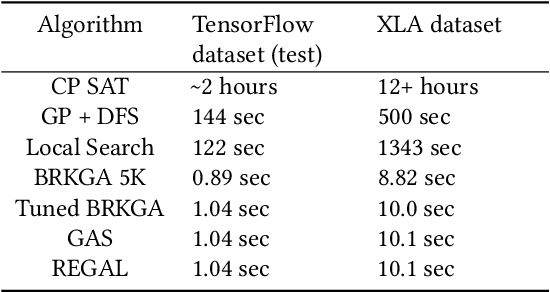
We present a deep reinforcement learning approach to optimizing the execution cost of computation graphs in a static compiler. The key idea is to combine a neural network policy with a genetic algorithm, the Biased Random-Key Genetic Algorithm (BRKGA). The policy is trained to predict, given an input graph to be optimized, the node-level probability distributions for sampling mutations and crossovers in BRKGA. Our approach, "REINFORCE-based Genetic Algorithm Learning" (REGAL), uses the policy's ability to transfer to new graphs to significantly improve the solution quality of the genetic algorithm for the same objective evaluation budget. As a concrete application, we show results for minimizing peak memory in TensorFlow graphs by jointly optimizing device placement and scheduling. REGAL achieves on average 3.56% lower peak memory than BRKGA on previously unseen graphs, outperforming all the algorithms we compare to, and giving 4.4x bigger improvement than the next best algorithm. We also evaluate REGAL on a production compiler team's performance benchmark of XLA graphs and achieve on average 3.74% lower peak memory than BRKGA, again outperforming all others. Our approach and analysis is made possible by collecting a dataset of 372 unique real-world TensorFlow graphs, more than an order of magnitude more data than previous work.
Graph Matching Networks for Learning the Similarity of Graph Structured Objects
May 12, 2019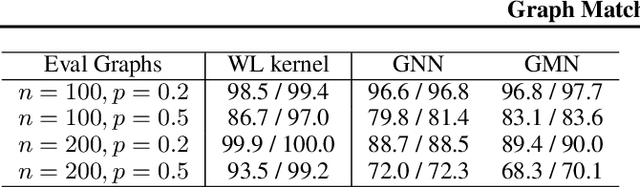
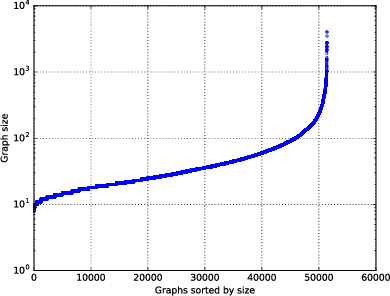
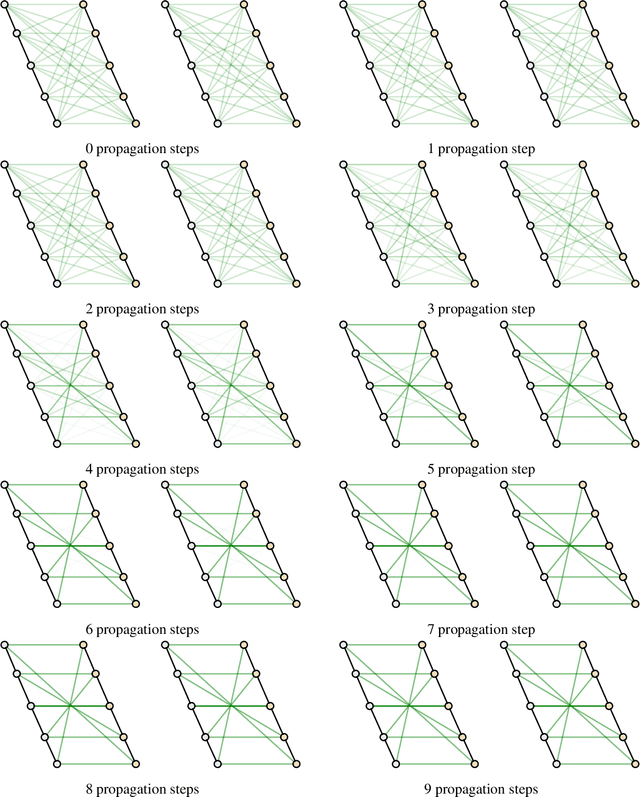
This paper addresses the challenging problem of retrieval and matching of graph structured objects, and makes two key contributions. First, we demonstrate how Graph Neural Networks (GNN), which have emerged as an effective model for various supervised prediction problems defined on structured data, can be trained to produce embedding of graphs in vector spaces that enables efficient similarity reasoning. Second, we propose a novel Graph Matching Network model that, given a pair of graphs as input, computes a similarity score between them by jointly reasoning on the pair through a new cross-graph attention-based matching mechanism. We demonstrate the effectiveness of our models on different domains including the challenging problem of control-flow-graph based function similarity search that plays an important role in the detection of vulnerabilities in software systems. The experimental analysis demonstrates that our models are not only able to exploit structure in the context of similarity learning but they can also outperform domain-specific baseline systems that have been carefully hand-engineered for these problems.
Compositional Imitation Learning: Explaining and executing one task at a time
Dec 04, 2018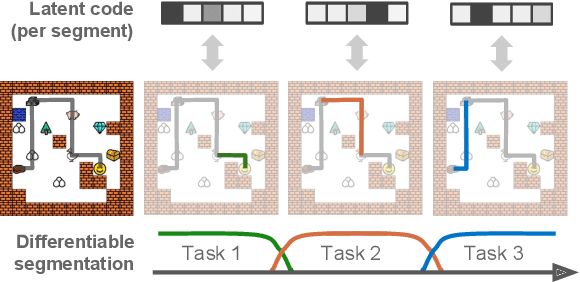
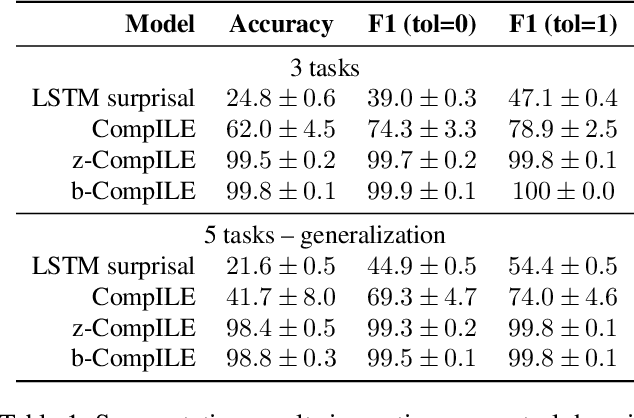
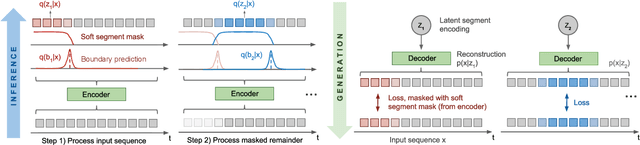
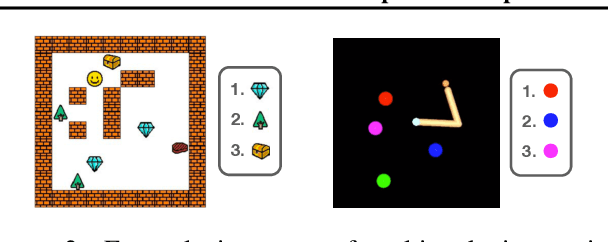
We introduce a framework for Compositional Imitation Learning and Execution (CompILE) of hierarchically-structured behavior. CompILE learns reusable, variable-length segments of behavior from demonstration data using a novel unsupervised, fully-differentiable sequence segmentation module. These learned behaviors can then be re-composed and executed to perform new tasks. At training time, CompILE auto-encodes observed behavior into a sequence of latent codes, each corresponding to a variable-length segment in the input sequence. Once trained, our model generalizes to sequences of longer length and from environment instances not seen during training. We evaluate our model in a challenging 2D multi-task environment and show that CompILE can find correct task boundaries and event encodings in an unsupervised manner without requiring annotated demonstration data. Latent codes and associated behavior policies discovered by CompILE can be used by a hierarchical agent, where the high-level policy selects actions in the latent code space, and the low-level, task-specific policies are simply the learned decoders. We found that our agent could learn given only sparse rewards, where agents without task-specific policies struggle.
Relational inductive biases, deep learning, and graph networks
Oct 17, 2018
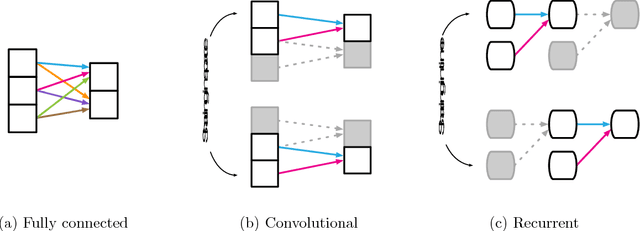
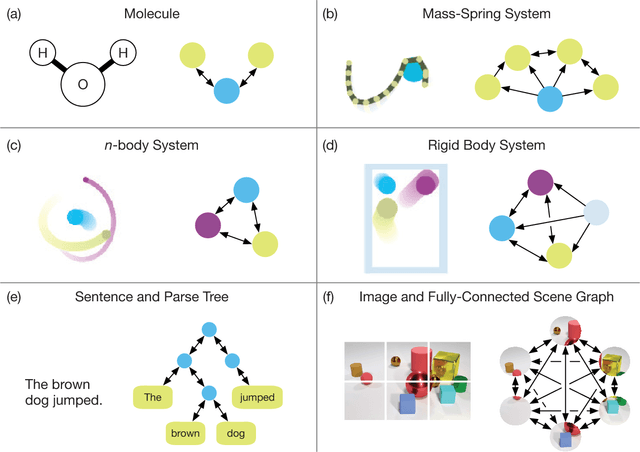
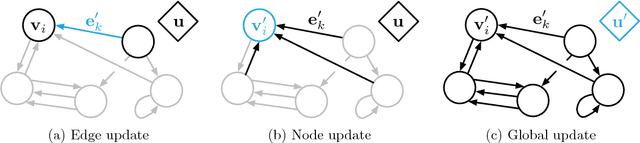
Artificial intelligence (AI) has undergone a renaissance recently, making major progress in key domains such as vision, language, control, and decision-making. This has been due, in part, to cheap data and cheap compute resources, which have fit the natural strengths of deep learning. However, many defining characteristics of human intelligence, which developed under much different pressures, remain out of reach for current approaches. In particular, generalizing beyond one's experiences--a hallmark of human intelligence from infancy--remains a formidable challenge for modern AI. The following is part position paper, part review, and part unification. We argue that combinatorial generalization must be a top priority for AI to achieve human-like abilities, and that structured representations and computations are key to realizing this objective. Just as biology uses nature and nurture cooperatively, we reject the false choice between "hand-engineering" and "end-to-end" learning, and instead advocate for an approach which benefits from their complementary strengths. We explore how using relational inductive biases within deep learning architectures can facilitate learning about entities, relations, and rules for composing them. We present a new building block for the AI toolkit with a strong relational inductive bias--the graph network--which generalizes and extends various approaches for neural networks that operate on graphs, and provides a straightforward interface for manipulating structured knowledge and producing structured behaviors. We discuss how graph networks can support relational reasoning and combinatorial generalization, laying the foundation for more sophisticated, interpretable, and flexible patterns of reasoning. As a companion to this paper, we have released an open-source software library for building graph networks, with demonstrations of how to use them in practice.
Proximal Policy Optimization and its Dynamic Version for Sequence Generation
Aug 24, 2018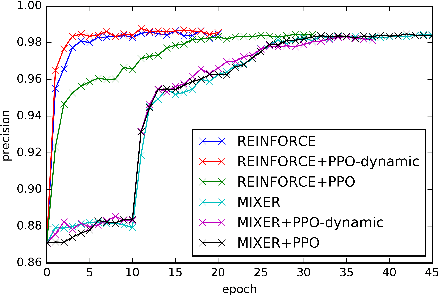
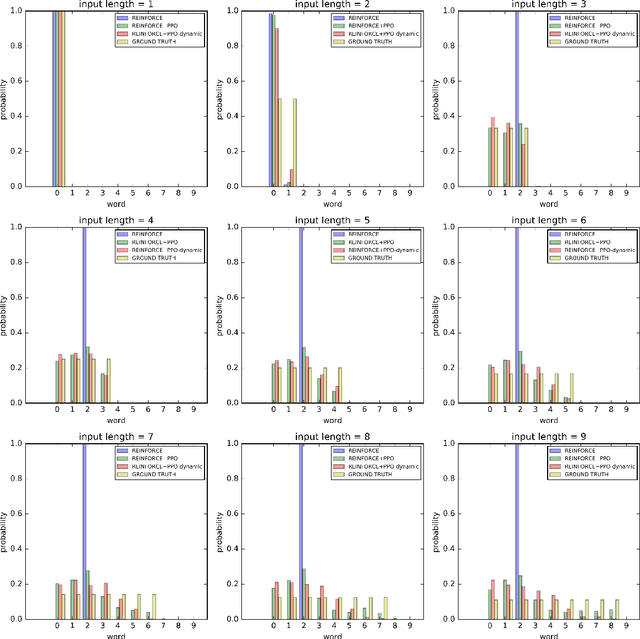
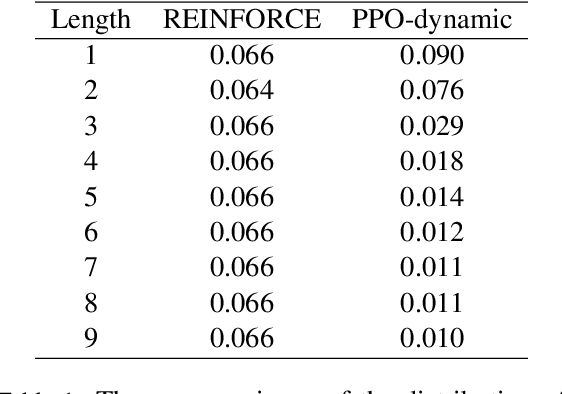
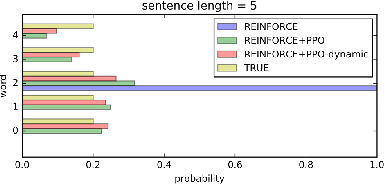
In sequence generation task, many works use policy gradient for model optimization to tackle the intractable backpropagation issue when maximizing the non-differentiable evaluation metrics or fooling the discriminator in adversarial learning. In this paper, we replace policy gradient with proximal policy optimization (PPO), which is a proved more efficient reinforcement learning algorithm, and propose a dynamic approach for PPO (PPO-dynamic). We demonstrate the efficacy of PPO and PPO-dynamic on conditional sequence generation tasks including synthetic experiment and chit-chat chatbot. The results show that PPO and PPO-dynamic can beat policy gradient by stability and performance.
Relational Deep Reinforcement Learning
Jun 28, 2018
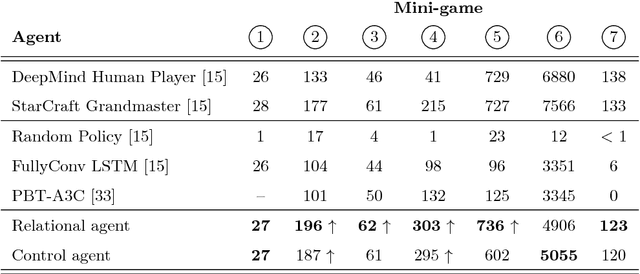
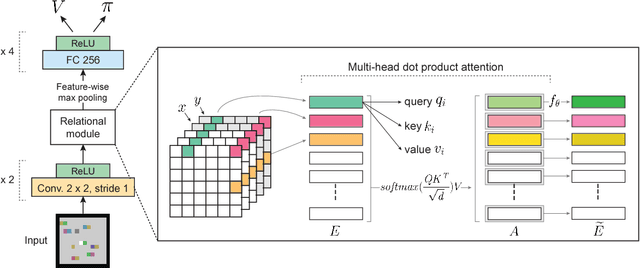
We introduce an approach for deep reinforcement learning (RL) that improves upon the efficiency, generalization capacity, and interpretability of conventional approaches through structured perception and relational reasoning. It uses self-attention to iteratively reason about the relations between entities in a scene and to guide a model-free policy. Our results show that in a novel navigation and planning task called Box-World, our agent finds interpretable solutions that improve upon baselines in terms of sample complexity, ability to generalize to more complex scenes than experienced during training, and overall performance. In the StarCraft II Learning Environment, our agent achieves state-of-the-art performance on six mini-games -- surpassing human grandmaster performance on four. By considering architectural inductive biases, our work opens new directions for overcoming important, but stubborn, challenges in deep RL.