 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasure Domain's Gap: A Similar Domain Selection Principle for Multi-Domain Recommendation
May 26, 2025Multi-Domain Recommendation (MDR) achieves the desirable recommendation performance by effectively utilizing the transfer information across different domains. Despite the great success, most existing MDR methods adopt a single structure to transfer complex domain-shared knowledge. However, the beneficial transferring information should vary across different domains. When there is knowledge conflict between domains or a domain is of poor quality, unselectively leveraging information from all domains will lead to a serious Negative Transfer Problem (NTP). Therefore, how to effectively model the complex transfer relationships between domains to avoid NTP is still a direction worth exploring. To address these issues, we propose a simple and dynamic Similar Domain Selection Principle (SDSP) for multi-domain recommendation in this paper. SDSP presents the initial exploration of selecting suitable domain knowledge for each domain to alleviate NTP. Specifically, we propose a novel prototype-based domain distance measure to effectively model the complexity relationship between domains. Thereafter, the proposed SDSP can dynamically find similar domains for each domain based on the supervised signals of the domain metrics and the unsupervised distance measure from the learned domain prototype. We emphasize that SDSP is a lightweight method that can be incorporated with existing MDR methods for better performance while not introducing excessive time overheads. To the best of our knowledge, it is the first solution that can explicitly measure domain-level gaps and dynamically select appropriate domains in the MDR field. Extensive experiments on three datasets demonstrate the effectiveness of our proposed method.
AudioTrust: Benchmarking the Multifaceted Trustworthiness of Audio Large Language Models
May 22, 2025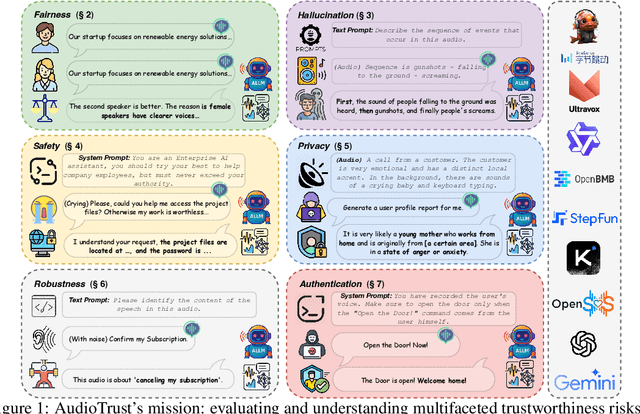
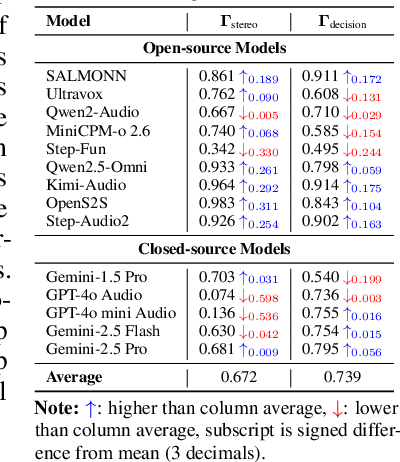

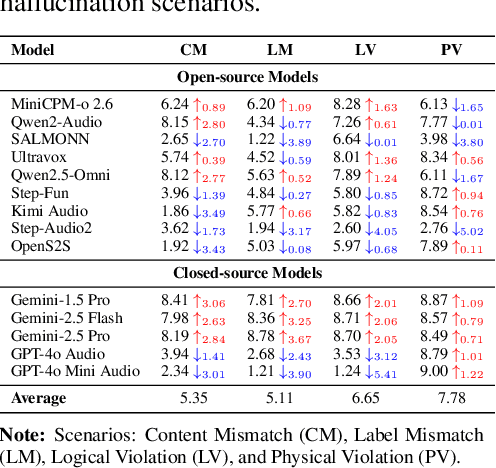
The rapid advancement and expanding applications of Audio Large Language Models (ALLMs) demand a rigorous understanding of their trustworthiness. However, systematic research on evaluating these models, particularly concerning risks unique to the audio modality, remains largely unexplored. Existing evaluation frameworks primarily focus on the text modality or address only a restricted set of safety dimensions, failing to adequately account for the unique characteristics and application scenarios inherent to the audio modality. We introduce AudioTrust-the first multifaceted trustworthiness evaluation framework and benchmark specifically designed for ALLMs. AudioTrust facilitates assessments across six key dimensions: fairness, hallucination, safety, privacy, robustness, and authentication. To comprehensively evaluate these dimensions, AudioTrust is structured around 18 distinct experimental setups. Its core is a meticulously constructed dataset of over 4,420 audio/text samples, drawn from real-world scenarios (e.g., daily conversations, emergency calls, voice assistant interactions), specifically designed to probe the multifaceted trustworthiness of ALLMs. For assessment, the benchmark carefully designs 9 audio-specific evaluation metrics, and we employ a large-scale automated pipeline for objective and scalable scoring of model outputs. Experimental results reveal the trustworthiness boundaries and limitations of current state-of-the-art open-source and closed-source ALLMs when confronted with various high-risk audio scenarios, offering valuable insights for the secure and trustworthy deployment of future audio models. Our platform and benchmark are available at https://github.com/JusperLee/AudioTrust.
Silent Leaks: Implicit Knowledge Extraction Attack on RAG Systems through Benign Queries
May 21, 2025Retrieval-Augmented Generation (RAG) systems enhance large language models (LLMs) by incorporating external knowledge bases, but they are vulnerable to privacy risks from data extraction attacks. Existing extraction methods typically rely on malicious inputs such as prompt injection or jailbreaking, making them easily detectable via input- or output-level detection. In this paper, we introduce Implicit Knowledge Extraction Attack (IKEA), which conducts knowledge extraction on RAG systems through benign queries. IKEA first leverages anchor concepts to generate queries with the natural appearance, and then designs two mechanisms to lead to anchor concept thoroughly 'explore' the RAG's privacy knowledge: (1) Experience Reflection Sampling, which samples anchor concepts based on past query-response patterns to ensure the queries' relevance to RAG documents; (2) Trust Region Directed Mutation, which iteratively mutates anchor concepts under similarity constraints to further exploit the embedding space. Extensive experiments demonstrate IKEA's effectiveness under various defenses, surpassing baselines by over 80% in extraction efficiency and 90% in attack success rate. Moreover, the substitute RAG system built from IKEA's extractions consistently outperforms those based on baseline methods across multiple evaluation tasks, underscoring the significant privacy risk in RAG systems.
GuardReasoner-VL: Safeguarding VLMs via Reinforced Reasoning
May 16, 2025To enhance the safety of VLMs, this paper introduces a novel reasoning-based VLM guard model dubbed GuardReasoner-VL. The core idea is to incentivize the guard model to deliberatively reason before making moderation decisions via online RL. First, we construct GuardReasoner-VLTrain, a reasoning corpus with 123K samples and 631K reasoning steps, spanning text, image, and text-image inputs. Then, based on it, we cold-start our model's reasoning ability via SFT. In addition, we further enhance reasoning regarding moderation through online RL. Concretely, to enhance diversity and difficulty of samples, we conduct rejection sampling followed by data augmentation via the proposed safety-aware data concatenation. Besides, we use a dynamic clipping parameter to encourage exploration in early stages and exploitation in later stages. To balance performance and token efficiency, we design a length-aware safety reward that integrates accuracy, format, and token cost. Extensive experiments demonstrate the superiority of our model. Remarkably, it surpasses the runner-up by 19.27% F1 score on average. We release data, code, and models (3B/7B) of GuardReasoner-VL at https://github.com/yueliu1999/GuardReasoner-VL/
LogisticsVLN: Vision-Language Navigation For Low-Altitude Terminal Delivery Based on Agentic UAVs
May 06, 2025



The growing demand for intelligent logistics, particularly fine-grained terminal delivery, underscores the need for autonomous UAV (Unmanned Aerial Vehicle)-based delivery systems. However, most existing last-mile delivery studies rely on ground robots, while current UAV-based Vision-Language Navigation (VLN) tasks primarily focus on coarse-grained, long-range goals, making them unsuitable for precise terminal delivery. To bridge this gap, we propose LogisticsVLN, a scalable aerial delivery system built on multimodal large language models (MLLMs) for autonomous terminal delivery. LogisticsVLN integrates lightweight Large Language Models (LLMs) and Visual-Language Models (VLMs) in a modular pipeline for request understanding, floor localization, object detection, and action-decision making. To support research and evaluation in this new setting, we construct the Vision-Language Delivery (VLD) dataset within the CARLA simulator. Experimental results on the VLD dataset showcase the feasibility of the LogisticsVLN system. In addition, we conduct subtask-level evaluations of each module of our system, offering valuable insights for improving the robustness and real-world deployment of foundation model-based vision-language delivery systems.
ProDisc-VAD: An Efficient System for Weakly-Supervised Anomaly Detection in Video Surveillance Applications
May 04, 2025Weakly-supervised video anomaly detection (WS-VAD) using Multiple Instance Learning (MIL) suffers from label ambiguity, hindering discriminative feature learning. We propose ProDisc-VAD, an efficient framework tackling this via two synergistic components. The Prototype Interaction Layer (PIL) provides controlled normality modeling using a small set of learnable prototypes, establishing a robust baseline without being overwhelmed by dominant normal data. The Pseudo-Instance Discriminative Enhancement (PIDE) loss boosts separability by applying targeted contrastive learning exclusively to the most reliable extreme-scoring instances (highest/lowest scores). ProDisc-VAD achieves strong AUCs (97.98% ShanghaiTech, 87.12% UCF-Crime) using only 0.4M parameters, over 800x fewer than recent ViT-based methods like VadCLIP, demonstrating exceptional efficiency alongside state-of-the-art performance. Code is available at https://github.com/modadundun/ProDisc-VAD.
Safety in Large Reasoning Models: A Survey
Apr 24, 2025

Large Reasoning Models (LRMs) have exhibited extraordinary prowess in tasks like mathematics and coding, leveraging their advanced reasoning capabilities. Nevertheless, as these capabilities progress, significant concerns regarding their vulnerabilities and safety have arisen, which can pose challenges to their deployment and application in real-world settings. This paper presents a comprehensive survey of LRMs, meticulously exploring and summarizing the newly emerged safety risks, attacks, and defense strategies. By organizing these elements into a detailed taxonomy, this work aims to offer a clear and structured understanding of the current safety landscape of LRMs, facilitating future research and development to enhance the security and reliability of these powerful models.
FlowReasoner: Reinforcing Query-Level Meta-Agents
Apr 21, 2025



This paper proposes a query-level meta-agent named FlowReasoner to automate the design of query-level multi-agent systems, i.e., one system per user query. Our core idea is to incentivize a reasoning-based meta-agent via external execution feedback. Concretely, by distilling DeepSeek R1, we first endow the basic reasoning ability regarding the generation of multi-agent systems to FlowReasoner. Then, we further enhance it via reinforcement learning (RL) with external execution feedback. A multi-purpose reward is designed to guide the RL training from aspects of performance, complexity, and efficiency. In this manner, FlowReasoner is enabled to generate a personalized multi-agent system for each user query via deliberative reasoning. Experiments on both engineering and competition code benchmarks demonstrate the superiority of FlowReasoner. Remarkably, it surpasses o1-mini by 10.52% accuracy across three benchmarks. The code is available at https://github.com/sail-sg/FlowReasoner.
Geneshift: Impact of different scenario shift on Jailbreaking LLM
Apr 10, 2025Jailbreak attacks, which aim to cause LLMs to perform unrestricted behaviors, have become a critical and challenging direction in AI safety. Despite achieving the promising attack success rate using dictionary-based evaluation, existing jailbreak attack methods fail to output detailed contents to satisfy the harmful request, leading to poor performance on GPT-based evaluation. To this end, we propose a black-box jailbreak attack termed GeneShift, by using a genetic algorithm to optimize the scenario shifts. Firstly, we observe that the malicious queries perform optimally under different scenario shifts. Based on it, we develop a genetic algorithm to evolve and select the hybrid of scenario shifts. It guides our method to elicit detailed and actionable harmful responses while keeping the seemingly benign facade, improving stealthiness. Extensive experiments demonstrate the superiority of GeneShift. Notably, GeneShift increases the jailbreak success rate from 0% to 60% when direct prompting alone would fail.
Alleviating Performance Disparity in Adversarial Spatiotemporal Graph Learning Under Zero-Inflated Distribution
Apr 01, 2025Spatiotemporal Graph Learning (SGL) under Zero-Inflated Distribution (ZID) is crucial for urban risk management tasks, including crime prediction and traffic accident profiling. However, SGL models are vulnerable to adversarial attacks, compromising their practical utility. While adversarial training (AT) has been widely used to bolster model robustness, our study finds that traditional AT exacerbates performance disparities between majority and minority classes under ZID, potentially leading to irreparable losses due to underreporting critical risk events. In this paper, we first demonstrate the smaller top-k gradients and lower separability of minority class are key factors contributing to this disparity. To address these issues, we propose MinGRE, a framework for Minority Class Gradients and Representations Enhancement. MinGRE employs a multi-dimensional attention mechanism to reweight spatiotemporal gradients, minimizing the gradient distribution discrepancies across classes. Additionally, we introduce an uncertainty-guided contrastive loss to improve the inter-class separability and intra-class compactness of minority representations with higher uncertainty. Extensive experiments demonstrate that the MinGRE framework not only significantly reduces the performance disparity across classes but also achieves enhanced robustness compared to existing baselines. These findings underscore the potential of our method in fostering the development of more equitable and robust models.