 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReTool-Video: Recursive Tool-Using Video Agents with Meta-Augmented Tool Grounding
May 13, 2026Video understanding requires active evidence seeking, motivating tool-augmented video agents for temporal reasoning, cross-modal understanding, and complex question answering. Existing video agents have improved video reasoning with retrieval, memory, frame inspection, and verifier tools, but they still face two limitations: (1) a coarse tool space that lacks fine-grained operations for compositional reasoning; and (2) a flat action space that forces high-level video intents into primitive executable tool calls. In this paper, we address these challenges with two complementary designs. First, we construct a MetaAug-Video Tool Library (MVTL), an extensible tool library with 134 registered tools, including 26 base tools for general multimodal signal processing and 108 meta tools for filtering, aggregation, reranking, formatting, and other intermediate-result operations. MVTL supports dual-level access to both structured video information and raw modal evidence, enabling diverse video reasoning scenarios. Second, we propose ReTool-Video, a recursive tool-using method that grounds high-level video intents into executable tool chains. In ReTool-Video, matched actions are executed directly, while unmatched intents are delegated to a resolver for parameter repair, tool substitution, or decomposition. This allows abstract actions such as temporal merging, cross-modal verification, or repeated-event aggregation to be progressively translated into concrete multimodal operations at runtime. Experiments on MVBench, MLVU, and Video-MME w/o sub. show that ReTool-Video consistently outperforms strong baselines. Further analysis demonstrates that recursive grounding and fine-grained meta tools improve the stability and effectiveness of complex video understanding.
The First Challenge on Remote Sensing Infrared Image Super-Resolution at NTIRE 2026: Benchmark Results and Method Overview
Apr 23, 2026This paper presents the NTIRE 2026 Remote Sensing Infrared Image Super-Resolution (x4) Challenge, one of the associated challenges of NTIRE 2026. The challenge aims to recover high-resolution (HR) infrared images from low-resolution (LR) inputs generated through bicubic downsampling with a x4 scaling factor. The objective is to develop effective models or solutions that achieve state-of-the-art performance for infrared image SR in remote sensing scenarios. To reflect the characteristics of infrared data and practical application needs, the challenge adopts a single-track setting. A total of 115 participants registered for the competition, with 13 teams submitting valid entries. This report summarizes the challenge design, dataset, evaluation protocol, main results, and the representative methods of each team. The challenge serves as a benchmark to advance research in infrared image super-resolution and promote the development of effective solutions for real-world remote sensing applications.
NTIRE 2026 The Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 12, 2026This paper presents an overview of the NTIRE 2026 Second Challenge on Day and Night Raindrop Removal for Dual-Focused Images. Building upon the success of the first edition, this challenge attracted a wide range of impressive solutions, all developed and evaluated on our real-world Raindrop Clarity dataset~\cite{jin2024raindrop}. For this edition, we adjust the dataset with 14,139 images for training, 407 images for validation, and 593 images for testing. The primary goal of this challenge is to establish a strong and practical benchmark for the removal of raindrops under various illumination and focus conditions. In total, 168 teams have registered for the competition, and 17 teams submitted valid final solutions and fact sheets for the testing phase. The submitted methods achieved strong performance on the Raindrop Clarity dataset, demonstrating the growing progress in this challenging task.
D-FaST: Cognitive Signal Decoding with Disentangled Frequency-Spatial-Temporal Attention
Jun 02, 2024



Cognitive Language Processing (CLP), situated at the intersection of Natural Language Processing (NLP) and cognitive science, plays a progressively pivotal role in the domains of artificial intelligence, cognitive intelligence, and brain science. Among the essential areas of investigation in CLP, Cognitive Signal Decoding (CSD) has made remarkable achievements, yet there still exist challenges related to insufficient global dynamic representation capability and deficiencies in multi-domain feature integration. In this paper, we introduce a novel paradigm for CLP referred to as Disentangled Frequency-Spatial-Temporal Attention(D-FaST). Specifically, we present an novel cognitive signal decoder that operates on disentangled frequency-space-time domain attention. This decoder encompasses three key components: frequency domain feature extraction employing multi-view attention, spatial domain feature extraction utilizing dynamic brain connection graph attention, and temporal feature extraction relying on local time sliding window attention. These components are integrated within a novel disentangled framework. Additionally, to encourage advancements in this field, we have created a new CLP dataset, MNRED. Subsequently, we conducted an extensive series of experiments, evaluating D-FaST's performance on MNRED, as well as on publicly available datasets including ZuCo, BCIC IV-2A, and BCIC IV-2B. Our experimental results demonstrate that D-FaST outperforms existing methods significantly on both our datasets and traditional CSD datasets including establishing a state-of-the-art accuracy score 78.72% on MNRED, pushing the accuracy score on ZuCo to 78.35%, accuracy score on BCIC IV-2A to 74.85% and accuracy score on BCIC IV-2B to 76.81%.
At Which Training Stage Does Code Data Help LLMs Reasoning?
Sep 30, 2023



Large Language Models (LLMs) have exhibited remarkable reasoning capabilities and become the foundation of language technologies. Inspired by the great success of code data in training LLMs, we naturally wonder at which training stage introducing code data can really help LLMs reasoning. To this end, this paper systematically explores the impact of code data on LLMs at different stages. Concretely, we introduce the code data at the pre-training stage, instruction-tuning stage, and both of them, respectively. Then, the reasoning capability of LLMs is comprehensively and fairly evaluated via six reasoning tasks in five domains. We critically analyze the experimental results and provide conclusions with insights. First, pre-training LLMs with the mixture of code and text can significantly enhance LLMs' general reasoning capability almost without negative transfer on other tasks. Besides, at the instruction-tuning stage, code data endows LLMs the task-specific reasoning capability. Moreover, the dynamic mixing strategy of code and text data assists LLMs to learn reasoning capability step-by-step during training. These insights deepen the understanding of LLMs regarding reasoning ability for their application, such as scientific question answering, legal support, etc. The source code and model parameters are released at the link:~\url{https://github.com/yingweima2022/CodeLLM}.
GeoTransformer: Fast and Robust Point Cloud Registration with Geometric Transformer
Jul 25, 2023



We study the problem of extracting accurate correspondences for point cloud registration. Recent keypoint-free methods have shown great potential through bypassing the detection of repeatable keypoints which is difficult to do especially in low-overlap scenarios. They seek correspondences over downsampled superpoints, which are then propagated to dense points. Superpoints are matched based on whether their neighboring patches overlap. Such sparse and loose matching requires contextual features capturing the geometric structure of the point clouds. We propose Geometric Transformer, or GeoTransformer for short, to learn geometric feature for robust superpoint matching. It encodes pair-wise distances and triplet-wise angles, making it invariant to rigid transformation and robust in low-overlap cases. The simplistic design attains surprisingly high matching accuracy such that no RANSAC is required in the estimation of alignment transformation, leading to $100$ times acceleration. Extensive experiments on rich benchmarks encompassing indoor, outdoor, synthetic, multiway and non-rigid demonstrate the efficacy of GeoTransformer. Notably, our method improves the inlier ratio by $18{\sim}31$ percentage points and the registration recall by over $7$ points on the challenging 3DLoMatch benchmark. Our code and models are available at \url{https://github.com/qinzheng93/GeoTransformer}.
Deep Graph-based Spatial Consistency for Robust Non-rigid Point Cloud Registration
Mar 17, 2023



We study the problem of outlier correspondence pruning for non-rigid point cloud registration. In rigid registration, spatial consistency has been a commonly used criterion to discriminate outliers from inliers. It measures the compatibility of two correspondences by the discrepancy between the respective distances in two point clouds. However, spatial consistency no longer holds in non-rigid cases and outlier rejection for non-rigid registration has not been well studied. In this work, we propose Graph-based Spatial Consistency Network (GraphSCNet) to filter outliers for non-rigid registration. Our method is based on the fact that non-rigid deformations are usually locally rigid, or local shape preserving. We first design a local spatial consistency measure over the deformation graph of the point cloud, which evaluates the spatial compatibility only between the correspondences in the vicinity of a graph node. An attention-based non-rigid correspondence embedding module is then devised to learn a robust representation of non-rigid correspondences from local spatial consistency. Despite its simplicity, GraphSCNet effectively improves the quality of the putative correspondences and attains state-of-the-art performance on three challenging benchmarks. Our code and models are available at https://github.com/qinzheng93/GraphSCNet.
Wound Segmentation with Dynamic Illumination Correction and Dual-view Semantic Fusion
Jul 12, 2022
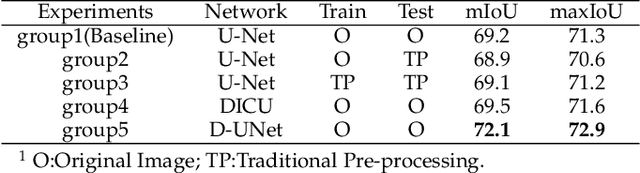
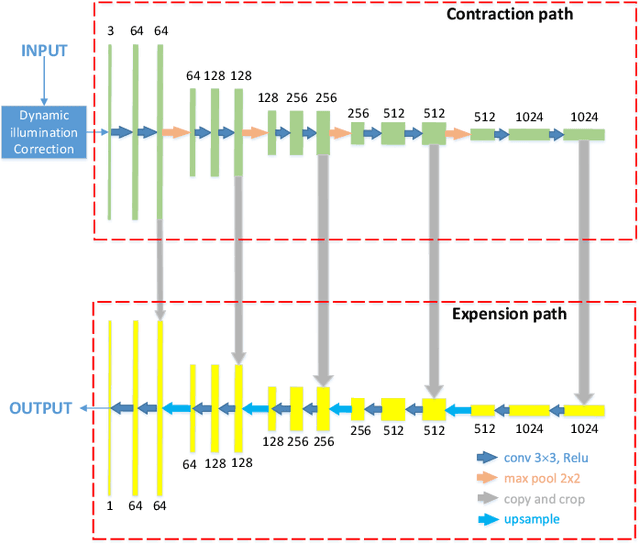

Wound image segmentation is a critical component for the clinical diagnosis and in-time treatment of wounds. Recently, deep learning has become the mainstream methodology for wound image segmentation. However, the pre-processing of the wound image, such as the illumination correction, is required before the training phase as the performance can be greatly improved. The correction procedure and the training of deep models are independent of each other, which leads to sub-optimal segmentation performance as the fixed illumination correction may not be suitable for all images. To address aforementioned issues, an end-to-end dual-view segmentation approach was proposed in this paper, by incorporating a learn-able illumination correction module into the deep segmentation models. The parameters of the module can be learned and updated during the training stage automatically, while the dual-view fusion can fully employ the features from both the raw images and the enhanced ones. To demonstrate the effectiveness and robustness of the proposed framework, the extensive experiments are conducted on the benchmark datasets. The encouraging results suggest that our framework can significantly improve the segmentation performance, compared to the state-of-the-art methods.
Trusted Multi-Scale Classification Framework for Whole Slide Image
Jul 12, 2022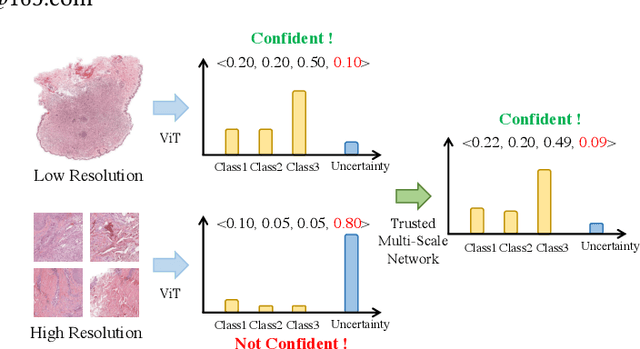


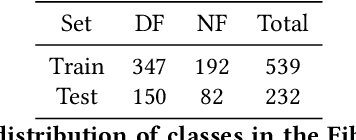
Despite remarkable efforts been made, the classification of gigapixels whole-slide image (WSI) is severely restrained from either the constrained computing resources for the whole slides, or limited utilizing of the knowledge from different scales. Moreover, most of the previous attempts lacked of the ability of uncertainty estimation. Generally, the pathologists often jointly analyze WSI from the different magnifications. If the pathologists are uncertain by using single magnification, then they will change the magnification repeatedly to discover various features of the tissues. Motivated by the diagnose process of the pathologists, in this paper, we propose a trusted multi-scale classification framework for the WSI. Leveraging the Vision Transformer as the backbone for multi branches, our framework can jointly classification modeling, estimating the uncertainty of each magnification of a microscope and integrate the evidence from different magnification. Moreover, to exploit discriminative patches from WSIs and reduce the requirement for computation resources, we propose a novel patch selection schema using attention rollout and non-maximum suppression. To empirically investigate the effectiveness of our approach, empirical experiments are conducted on our WSI classification tasks, using two benchmark databases. The obtained results suggest that the trusted framework can significantly improve the WSI classification performance compared with the state-of-the-art methods.
Unsupervised Voice-Face Representation Learning by Cross-Modal Prototype Contrast
May 02, 2022
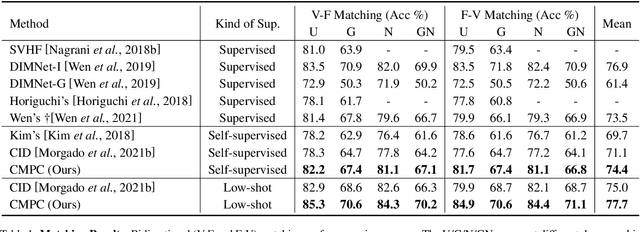
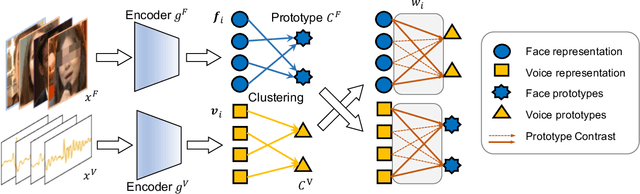
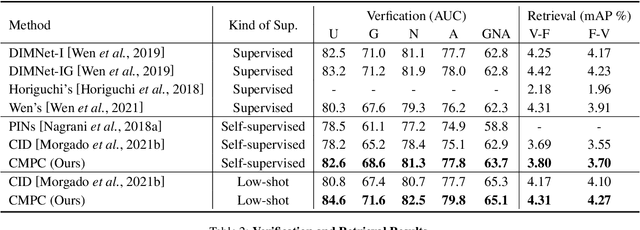
We present an approach to learn voice-face representations from the talking face videos, without any identity labels. Previous works employ cross-modal instance discrimination tasks to establish the correlation of voice and face. These methods neglect the semantic content of different videos, introducing false-negative pairs as training noise. Furthermore, the positive pairs are constructed based on the natural correlation between audio clips and visual frames. However, this correlation might be weak or inaccurate in a large amount of real-world data, which leads to deviating positives into the contrastive paradigm. To address these issues, we propose the cross-modal prototype contrastive learning (CMPC), which takes advantage of contrastive methods and resists adverse effects of false negatives and deviate positives. On one hand, CMPC could learn the intra-class invariance by constructing semantic-wise positives via unsupervised clustering in different modalities. On the other hand, by comparing the similarities of cross-modal instances from that of cross-modal prototypes, we dynamically recalibrate the unlearnable instances' contribution to overall loss. Experiments show that the proposed approach outperforms state-of-the-art unsupervised methods on various voice-face association evaluation protocols. Additionally, in the low-shot supervision setting, our method also has a significant improvement compared to previous instance-wise contrastive learning.