 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePR-RRN: Pairwise-Regularized Residual-Recursive Networks for Non-rigid Structure-from-Motion
Aug 17, 2021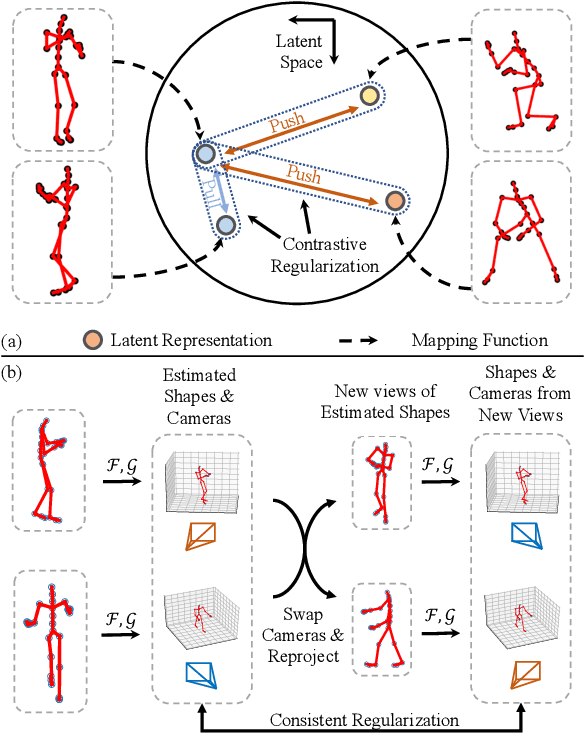
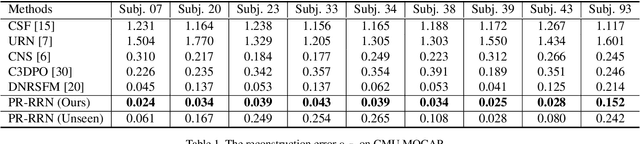
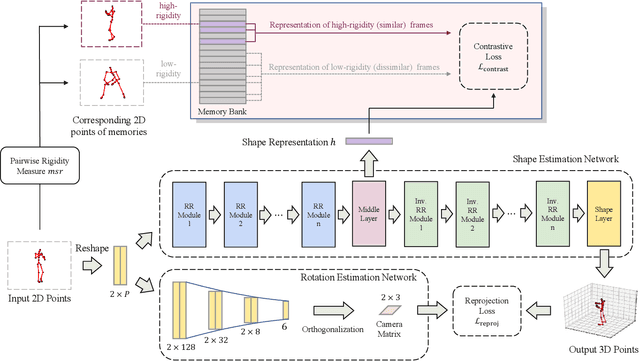
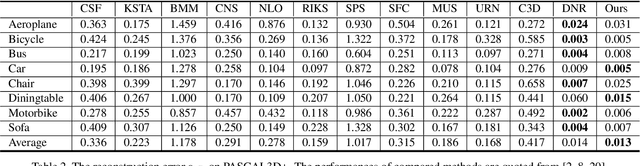
We propose PR-RRN, a novel neural-network based method for Non-rigid Structure-from-Motion (NRSfM). PR-RRN consists of Residual-Recursive Networks (RRN) and two extra regularization losses. RRN is designed to effectively recover 3D shape and camera from 2D keypoints with novel residual-recursive structure. As NRSfM is a highly under-constrained problem, we propose two new pairwise regularization to further regularize the reconstruction. The Rigidity-based Pairwise Contrastive Loss regularizes the shape representation by encouraging higher similarity between the representations of high-rigidity pairs of frames than low-rigidity pairs. We propose minimum singular-value ratio to measure the pairwise rigidity. The Pairwise Consistency Loss enforces the reconstruction to be consistent when the estimated shapes and cameras are exchanged between pairs. Our approach achieves state-of-the-art performance on CMU MOCAP and PASCAL3D+ dataset.
SUNet: Symmetric Undistortion Network for Rolling Shutter Correction
Aug 10, 2021
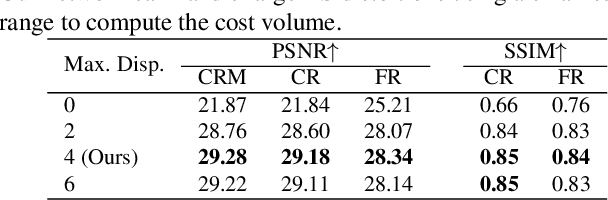
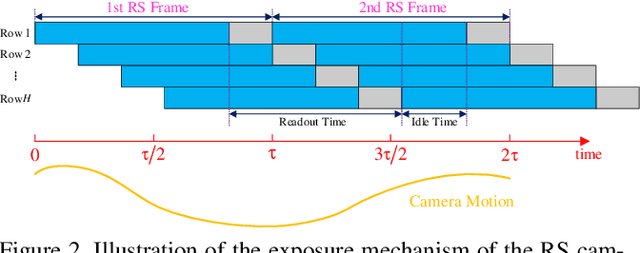
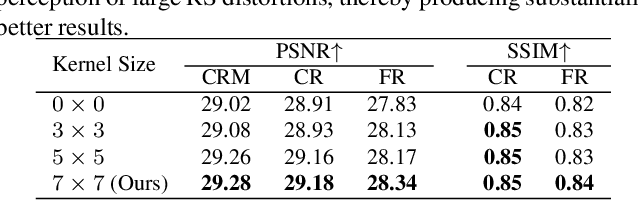
The vast majority of modern consumer-grade cameras employ a rolling shutter mechanism, leading to image distortions if the camera moves during image acquisition. In this paper, we present a novel deep network to solve the generic rolling shutter correction problem with two consecutive frames. Our pipeline is symmetrically designed to predict the global shutter image corresponding to the intermediate time of these two frames, which is difficult for existing methods because it corresponds to a camera pose that differs most from the two frames. First, two time-symmetric dense undistortion flows are estimated by using well-established principles: pyramidal construction, warping, and cost volume processing. Then, both rolling shutter images are warped into a common global shutter one in the feature space, respectively. Finally, a symmetric consistency constraint is constructed in the image decoder to effectively aggregate the contextual cues of two rolling shutter images, thereby recovering the high-quality global shutter image. Extensive experiments with both synthetic and real data from public benchmarks demonstrate the superiority of our proposed approach over the state-of-the-art methods.
Complementary Patch for Weakly Supervised Semantic Segmentation
Aug 09, 2021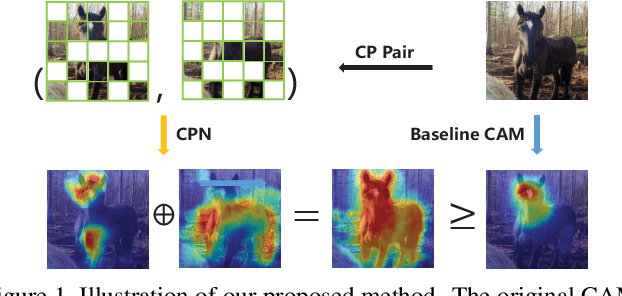
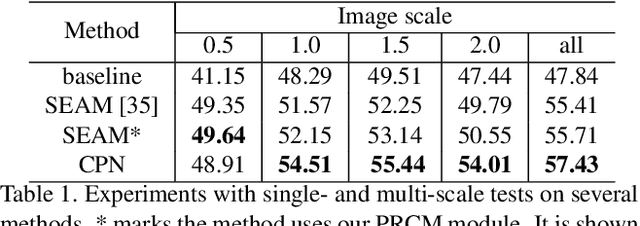
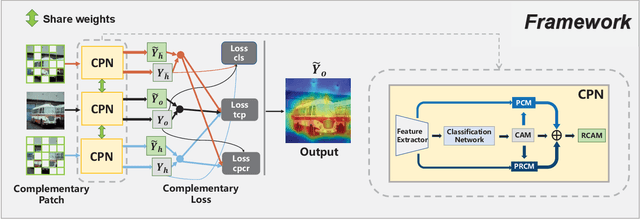

Weakly Supervised Semantic Segmentation (WSSS) based on image-level labels has been greatly advanced by exploiting the outputs of Class Activation Map (CAM) to generate the pseudo labels for semantic segmentation. However, CAM merely discovers seeds from a small number of regions, which may be insufficient to serve as pseudo masks for semantic segmentation. In this paper, we formulate the expansion of object regions in CAM as an increase in information. From the perspective of information theory, we propose a novel Complementary Patch (CP) Representation and prove that the information of the sum of the CAMs by a pair of input images with complementary hidden (patched) parts, namely CP Pair, is greater than or equal to the information of the baseline CAM. Therefore, a CAM with more information related to object seeds can be obtained by narrowing down the gap between the sum of CAMs generated by the CP Pair and the original CAM. We propose a CP Network (CPN) implemented by a triplet network and three regularization functions. To further improve the quality of the CAMs, we propose a Pixel-Region Correlation Module (PRCM) to augment the contextual information by using object-region relations between the feature maps and the CAMs. Experimental results on the PASCAL VOC 2012 datasets show that our proposed method achieves a new state-of-the-art in WSSS, validating the effectiveness of our CP Representation and CPN.
Depth-Guided Camouflaged Object Detection
Jun 26, 2021
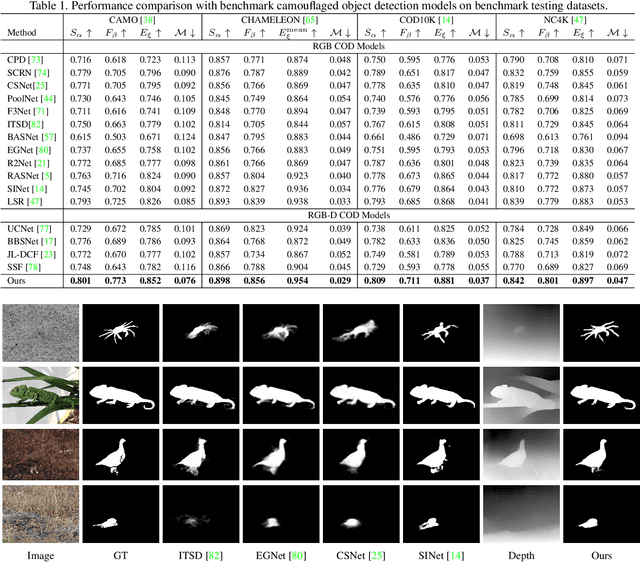
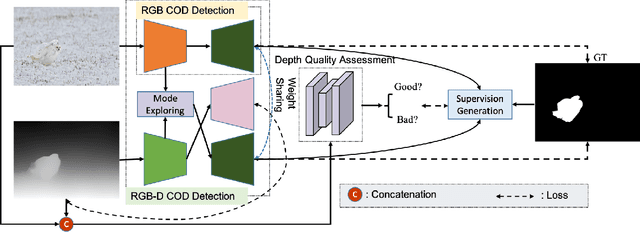

Camouflaged object detection (COD) aims to segment camouflaged objects hiding in the environment, which is challenging due to the similar appearance of camouflaged objects and their surroundings. Research in biology suggests that depth can provide useful object localization cues for camouflaged object discovery, as all the animals have 3D perception ability. However, the depth information has not been exploited for camouflaged object detection. To explore the contribution of depth for camouflage detection, we present a depth-guided camouflaged object detection network with pre-computed depth maps from existing monocular depth estimation methods. Due to the domain gap between the depth estimation dataset and our camouflaged object detection dataset, the generated depth may not be accurate enough to be directly used in our framework. We then introduce a depth quality assessment module to evaluate the quality of depth based on the model prediction from both RGB COD branch and RGB-D COD branch. During training, only high-quality depth is used to update the modal interaction module for multi-modal learning. During testing, our depth quality assessment module can effectively determine the contribution of depth and select the RGB branch or RGB-D branch for camouflage prediction. Extensive experiments on various camouflaged object detection datasets prove the effectiveness of our solution in exploring the depth information for camouflaged object detection. Our code and data is publicly available at: \url{https://github.com/JingZhang617/RGBD-COD}.
Transformer Transforms Salient Object Detection and Camouflaged Object Detection
Apr 20, 2021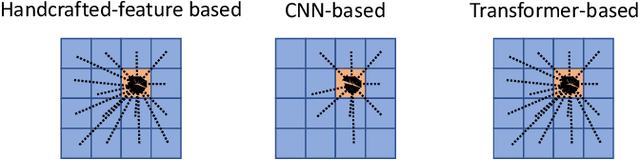
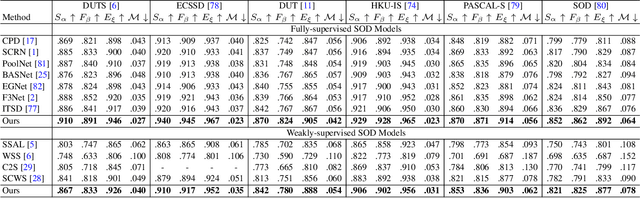
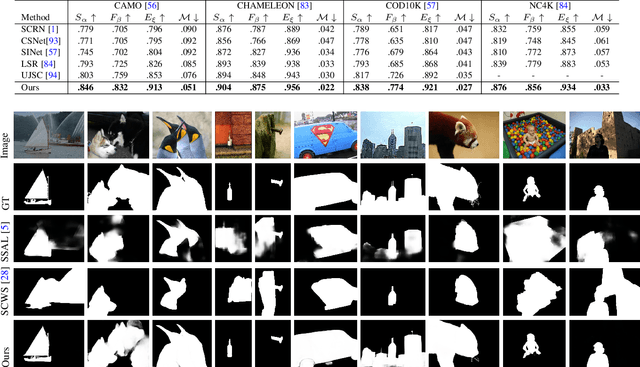
The transformer networks, which originate from machine translation, are particularly good at modeling long-range dependencies within a long sequence. Currently, the transformer networks are making revolutionary progress in various vision tasks ranging from high-level classification tasks to low-level dense prediction tasks. In this paper, we conduct research on applying the transformer networks for salient object detection (SOD). Specifically, we adopt the dense transformer backbone for fully supervised RGB image based SOD, RGB-D image pair based SOD, and weakly supervised SOD via scribble supervision. As an extension, we also apply our fully supervised model to the task of camouflaged object detection (COD) for camouflaged object segmentation. For the fully supervised models, we define the dense transformer backbone as feature encoder, and design a very simple decoder to produce a one channel saliency map (or camouflage map for the COD task). For the weakly supervised model, as there exists no structure information in the scribble annotation, we first adopt the recent proposed Gated-CRF loss to effectively model the pair-wise relationships for accurate model prediction. Then, we introduce self-supervised learning strategy to push the model to produce scale-invariant predictions, which is proven effective for weakly supervised models and models trained on small training datasets. Extensive experimental results on various SOD and COD tasks (fully supervised RGB image based SOD, fully supervised RGB-D image pair based SOD, weakly supervised SOD via scribble supervision, and fully supervised RGB image based COD) illustrate that transformer networks can transform salient object detection and camouflaged object detection, leading to new benchmarks for each related task.
CFNet: Cascade and Fused Cost Volume for Robust Stereo Matching
Apr 09, 2021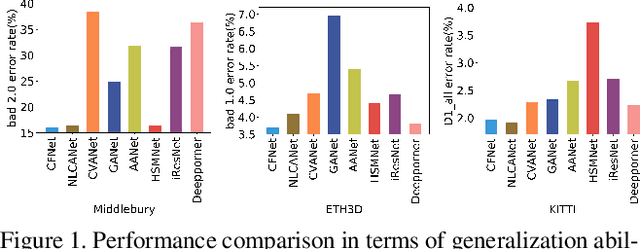
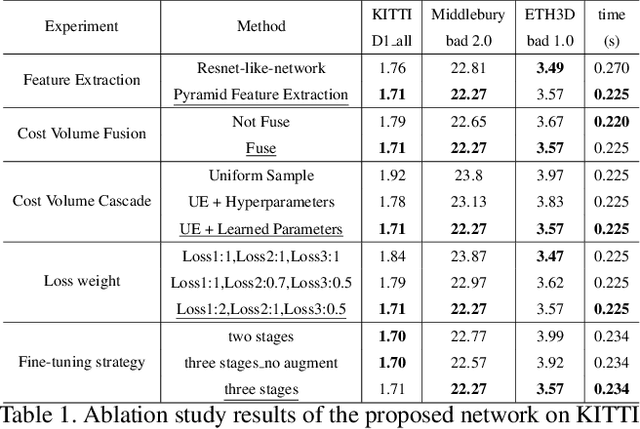
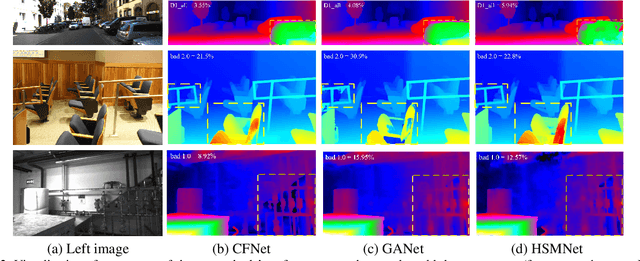
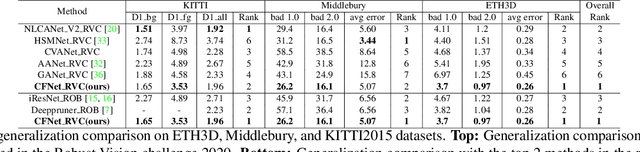
Recently, the ever-increasing capacity of large-scale annotated datasets has led to profound progress in stereo matching. However, most of these successes are limited to a specific dataset and cannot generalize well to other datasets. The main difficulties lie in the large domain differences and unbalanced disparity distribution across a variety of datasets, which greatly limit the real-world applicability of current deep stereo matching models. In this paper, we propose CFNet, a Cascade and Fused cost volume based network to improve the robustness of the stereo matching network. First, we propose a fused cost volume representation to deal with the large domain difference. By fusing multiple low-resolution dense cost volumes to enlarge the receptive field, we can extract robust structural representations for initial disparity estimation. Second, we propose a cascade cost volume representation to alleviate the unbalanced disparity distribution. Specifically, we employ a variance-based uncertainty estimation to adaptively adjust the next stage disparity search space, in this way driving the network progressively prune out the space of unlikely correspondences. By iteratively narrowing down the disparity search space and improving the cost volume resolution, the disparity estimation is gradually refined in a coarse-to-fine manner. When trained on the same training images and evaluated on KITTI, ETH3D, and Middlebury datasets with the fixed model parameters and hyperparameters, our proposed method achieves the state-of-the-art overall performance and obtains the 1st place on the stereo task of Robust Vision Challenge 2020. The code will be available at https://github.com/gallenszl/CFNet.
Uncertainty-aware Joint Salient Object and Camouflaged Object Detection
Apr 06, 2021
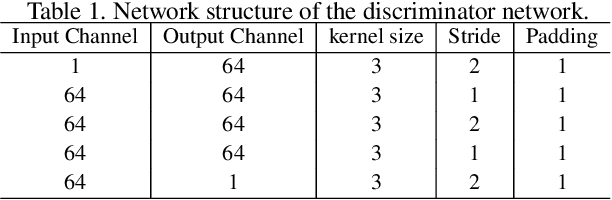
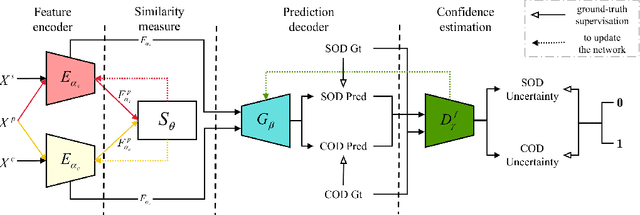
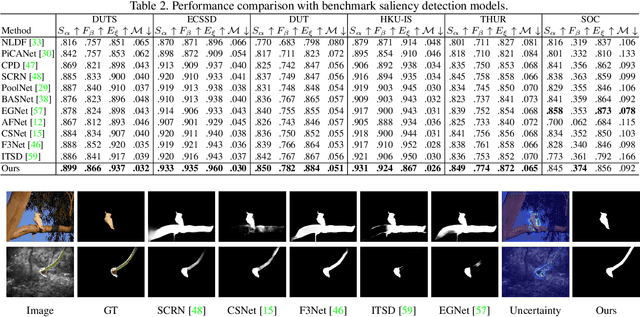
Visual salient object detection (SOD) aims at finding the salient object(s) that attract human attention, while camouflaged object detection (COD) on the contrary intends to discover the camouflaged object(s) that hidden in the surrounding. In this paper, we propose a paradigm of leveraging the contradictory information to enhance the detection ability of both salient object detection and camouflaged object detection. We start by exploiting the easy positive samples in the COD dataset to serve as hard positive samples in the SOD task to improve the robustness of the SOD model. Then, we introduce a similarity measure module to explicitly model the contradicting attributes of these two tasks. Furthermore, considering the uncertainty of labeling in both tasks' datasets, we propose an adversarial learning network to achieve both higher order similarity measure and network confidence estimation. Experimental results on benchmark datasets demonstrate that our solution leads to state-of-the-art (SOTA) performance for both tasks.
Deep Two-View Structure-from-Motion Revisited
Apr 01, 2021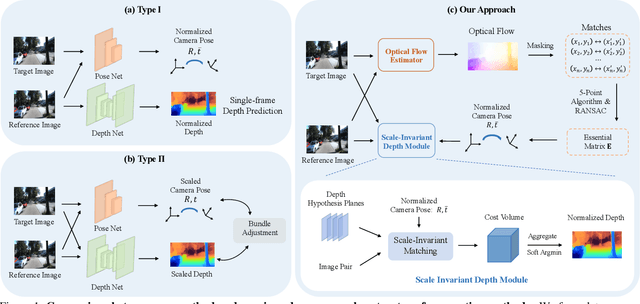
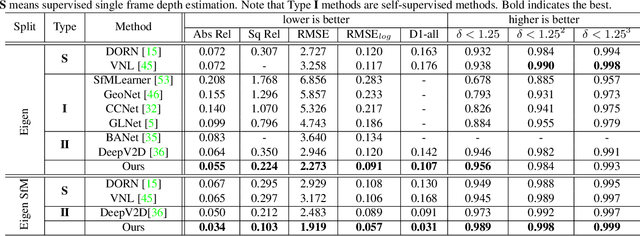


Two-view structure-from-motion (SfM) is the cornerstone of 3D reconstruction and visual SLAM. Existing deep learning-based approaches formulate the problem by either recovering absolute pose scales from two consecutive frames or predicting a depth map from a single image, both of which are ill-posed problems. In contrast, we propose to revisit the problem of deep two-view SfM by leveraging the well-posedness of the classic pipeline. Our method consists of 1) an optical flow estimation network that predicts dense correspondences between two frames; 2) a normalized pose estimation module that computes relative camera poses from the 2D optical flow correspondences, and 3) a scale-invariant depth estimation network that leverages epipolar geometry to reduce the search space, refine the dense correspondences, and estimate relative depth maps. Extensive experiments show that our method outperforms all state-of-the-art two-view SfM methods by a clear margin on KITTI depth, KITTI VO, MVS, Scenes11, and SUN3D datasets in both relative pose and depth estimation.
Simultaneously Localize, Segment and Rank the Camouflaged Objects
Mar 06, 2021
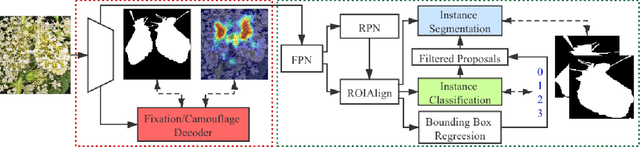
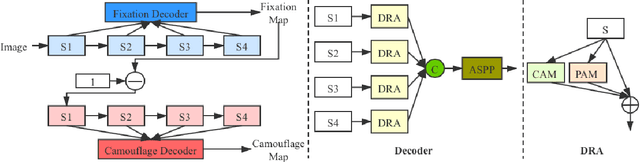
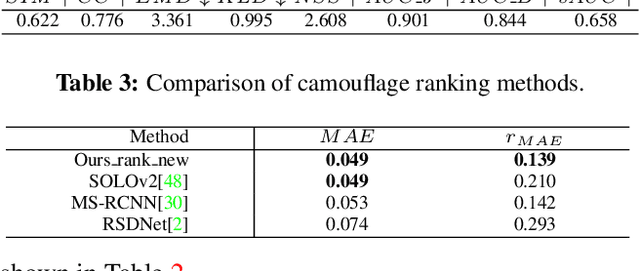
Camouflage is a key defence mechanism across species that is critical to survival. Common strategies for camouflage include background matching, imitating the color and pattern of the environment, and disruptive coloration, disguising body outlines [35]. Camouflaged object detection (COD) aims to segment camouflaged objects hiding in their surroundings. Existing COD models are built upon binary ground truth to segment the camouflaged objects without illustrating the level of camouflage. In this paper, we revisit this task and argue that explicitly modeling the conspicuousness of camouflaged objects against their particular backgrounds can not only lead to a better understanding about camouflage and evolution of animals, but also provide guidance to design more sophisticated camouflage techniques. Furthermore, we observe that it is some specific parts of the camouflaged objects that make them detectable by predators. With the above understanding about camouflaged objects, we present the first ranking based COD network (Rank-Net) to simultaneously localize, segment and rank camouflaged objects. The localization model is proposed to find the discriminative regions that make the camouflaged object obvious. The segmentation model segments the full scope of the camouflaged objects. And, the ranking model infers the detectability of different camouflaged objects. Moreover, we contribute a large COD testing set to evaluate the generalization ability of COD models. Experimental results show that our model achieves new state-of-the-art, leading to a more interpretable COD network.
IAFA: Instance-aware Feature Aggregation for 3D Object Detection from a Single Image
Mar 05, 2021
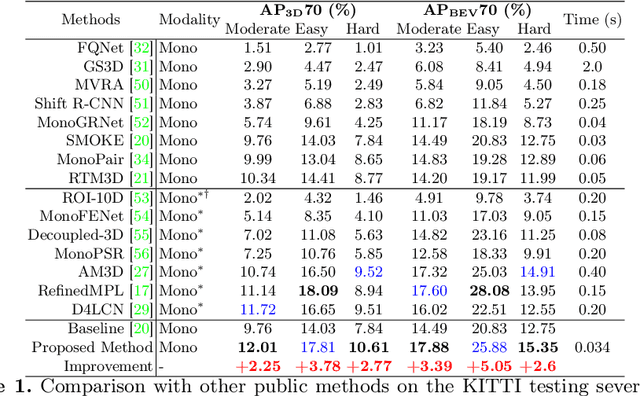
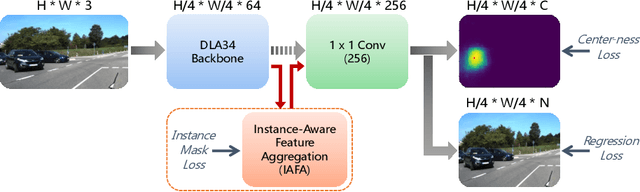
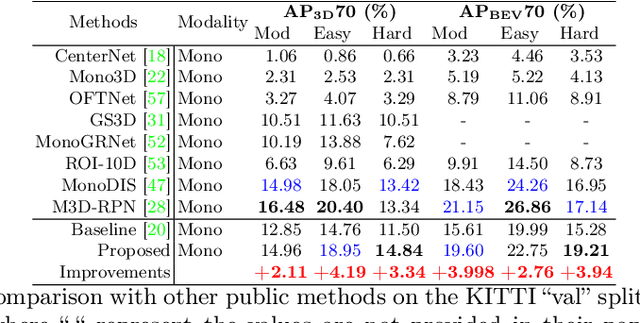
3D object detection from a single image is an important task in Autonomous Driving (AD), where various approaches have been proposed. However, the task is intrinsically ambiguous and challenging as single image depth estimation is already an ill-posed problem. In this paper, we propose an instance-aware approach to aggregate useful information for improving the accuracy of 3D object detection with the following contributions. First, an instance-aware feature aggregation (IAFA) module is proposed to collect local and global features for 3D bounding boxes regression. Second, we empirically find that the spatial attention module can be well learned by taking coarse-level instance annotations as a supervision signal. The proposed module has significantly boosted the performance of the baseline method on both 3D detection and 2D bird-eye's view of vehicle detection among all three categories. Third, our proposed method outperforms all single image-based approaches (even these methods trained with depth as auxiliary inputs) and achieves state-of-the-art 3D detection performance on the KITTI benchmark.