 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Semantic and Pixel Representations for Ultra-Low Bitrate Image Compression
Jun 01, 2026Most existing extreme compression methods fail to achieve an optimal rate-distortion-perception trade-off, as they typically prioritize perceptual fidelity and visual realism over pixel-level accuracy. Consequently, the resulting reconstructions often deviate noticeably from the originals. Ultra-low bitrate image compression is therefore crucial-not only for producing extremely compact representations but also for ensuring that reconstructed images remain semantically coherent and faithful to the source at the pixel level. To this end, we propose SPRDiff, a diffusion-based compression method that fully leverages both semantic and pixel representations, thereby enhancing reconstruction fidelity under ultra-low bitrate constraints. Specifically, we develop a triple-encoder architecture that utilizes high-fidelity features from the pretrained distortion-oriented and semantic-oriented encoders to compensate for the limited representations extracted by the frozen VAE encoder, thereby improving latent compression and entropy modeling. To further enhance the reconstruction fidelity of diffusion models, we introduce a distortion-aware reconstruction module with dual feature extraction. This module not only generates a coarse reconstruction that preserves the main structures, but also provides practical and accurate semantic- and pixel-level conditional signals to guide the diffusion model. Extensive experiments on benchmark datasets demonstrate that our method outperforms state-of-the-art approaches in the rate-distortion-perception tradeoff at extremely low bitrates (below 0.03 bpp), effectively preserving both perceptual quality and pixel-wise fidelity in the reconstructed images. We will release the source code and trained models at https://github.com/cshw2021/SPRDiff.
Mind the Rarities: Can Rare Skin Diseases Be Reliably Diagnosed via Diagnostic Reasoning?
Mar 19, 2026Large vision-language models (LVLMs) demonstrate strong performance in dermatology; however, evaluating diagnostic reasoning for rare conditions remains largely unexplored. Existing benchmarks focus on common diseases and assess only final accuracy, overlooking the clinical reasoning process, which is critical for complex cases. We address this gap by constructing DermCase, a long-context benchmark derived from peer-reviewed case reports. Our dataset contains 26,030 multi-modal image-text pairs and 6,354 clinically challenging cases, each annotated with comprehensive clinical information and step-by-step reasoning chains. To enable reliable evaluation, we establish DermLIP-based similarity metrics that achieve stronger alignment with dermatologists for assessing differential diagnosis quality. Benchmarking 22 leading LVLMs exposes significant deficiencies across diagnosis accuracy, differential diagnosis, and clinical reasoning. Fine-tuning experiments demonstrate that instruction tuning substantially improves performance while Direct Preference Optimization (DPO) yields minimal gains. Systematic error analysis further reveals critical limitations in current models' reasoning capabilities.
SwinIFS: Landmark Guided Swin Transformer For Identity Preserving Face Super Resolution
Jan 04, 2026Face super-resolution aims to recover high-quality facial images from severely degraded low-resolution inputs, but remains challenging due to the loss of fine structural details and identity-specific features. This work introduces SwinIFS, a landmark-guided super-resolution framework that integrates structural priors with hierarchical attention mechanisms to achieve identity-preserving reconstruction at both moderate and extreme upscaling factors. The method incorporates dense Gaussian heatmaps of key facial landmarks into the input representation, enabling the network to focus on semantically important facial regions from the earliest stages of processing. A compact Swin Transformer backbone is employed to capture long-range contextual information while preserving local geometry, allowing the model to restore subtle facial textures and maintain global structural consistency. Extensive experiments on the CelebA benchmark demonstrate that SwinIFS achieves superior perceptual quality, sharper reconstructions, and improved identity retention; it consistently produces more photorealistic results and exhibits strong performance even under 8x magnification, where most methods fail to recover meaningful structure. SwinIFS also provides an advantageous balance between reconstruction accuracy and computational efficiency, making it suitable for real-world applications in facial enhancement, surveillance, and digital restoration. Our code, model weights, and results are available at https://github.com/Habiba123-stack/SwinIFS.
PENDULUM: A Benchmark for Assessing Sycophancy in Multimodal Large Language Models
Dec 22, 2025Sycophancy, an excessive tendency of AI models to agree with user input at the expense of factual accuracy or in contradiction of visual evidence, poses a critical and underexplored challenge for multimodal large language models (MLLMs). While prior studies have examined this behavior in text-only settings of large language models, existing research on visual or multimodal counterparts remains limited in scope and depth of analysis. To address this gap, we introduce a comprehensive evaluation benchmark, \textit{PENDULUM}, comprising approximately 2,000 human-curated Visual Question Answering pairs specifically designed to elicit sycophantic responses. The benchmark spans six distinct image domains of varying complexity, enabling a systematic investigation of how image type and inherent challenges influence sycophantic tendencies. Through extensive evaluation of state-of-the-art MLLMs. we observe substantial variability in model robustness and a pronounced susceptibility to sycophantic and hallucinatory behavior. Furthermore, we propose novel metrics to quantify sycophancy in visual reasoning, offering deeper insights into its manifestations across different multimodal contexts. Our findings highlight the urgent need for developing sycophancy-resilient architectures and training strategies to enhance factual consistency and reliability in future MLLMs. Our proposed dataset with MLLMs response are available at https://github.com/ashikiut/pendulum/.
C3Net: Context-Contrast Network for Camouflaged Object Detection
Nov 16, 2025Camouflaged object detection identifies objects that blend seamlessly with their surroundings through similar colors, textures, and patterns. This task challenges both traditional segmentation methods and modern foundation models, which fail dramatically on camouflaged objects. We identify six fundamental challenges in COD: Intrinsic Similarity, Edge Disruption, Extreme Scale Variation, Environmental Complexities, Contextual Dependencies, and Salient-Camouflaged Object Disambiguation. These challenges frequently co-occur and compound the difficulty of detection, requiring comprehensive architectural solutions. We propose C3Net, which addresses all challenges through a specialized dual-pathway decoder architecture. The Edge Refinement Pathway employs gradient-initialized Edge Enhancement Modules to recover precise boundaries from early features. The Contextual Localization Pathway utilizes our novel Image-based Context Guidance mechanism to achieve intrinsic saliency suppression without external models. An Attentive Fusion Module synergistically combines the two pathways via spatial gating. C3Net achieves state-of-the-art performance with S-measures of 0.898 on COD10K, 0.904 on CAMO, and 0.913 on NC4K, while maintaining efficient processing. C3Net demonstrates that complex, multifaceted detection challenges require architectural innovation, with specialized components working synergistically to achieve comprehensive coverage beyond isolated improvements. Code, model weights, and results are available at https://github.com/Baber-Jan/C3Net.
MSRNet: A Multi-Scale Recursive Network for Camouflaged Object Detection
Nov 16, 2025
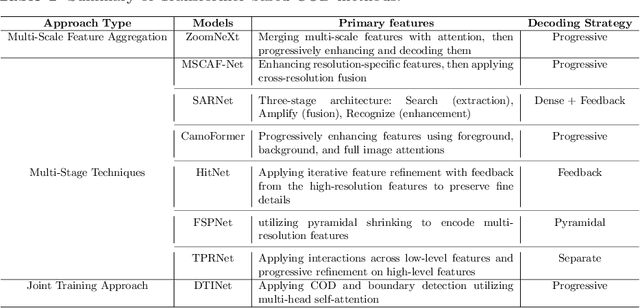
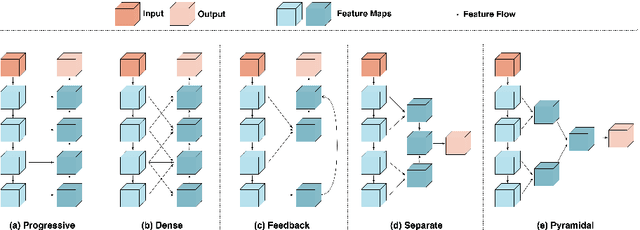
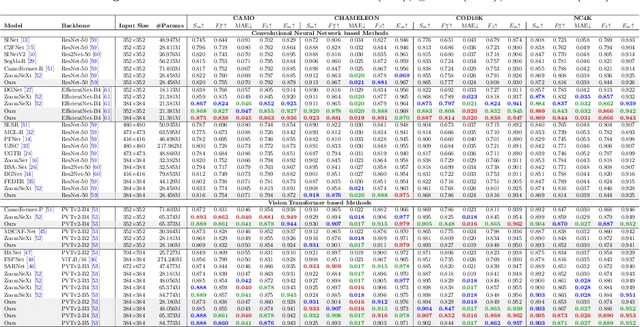
Camouflaged object detection is an emerging and challenging computer vision task that requires identifying and segmenting objects that blend seamlessly into their environments due to high similarity in color, texture, and size. This task is further complicated by low-light conditions, partial occlusion, small object size, intricate background patterns, and multiple objects. While many sophisticated methods have been proposed for this task, current methods still struggle to precisely detect camouflaged objects in complex scenarios, especially with small and multiple objects, indicating room for improvement. We propose a Multi-Scale Recursive Network that extracts multi-scale features via a Pyramid Vision Transformer backbone and combines them via specialized Attention-Based Scale Integration Units, enabling selective feature merging. For more precise object detection, our decoder recursively refines features by incorporating Multi-Granularity Fusion Units. A novel recursive-feedback decoding strategy is developed to enhance global context understanding, helping the model overcome the challenges in this task. By jointly leveraging multi-scale learning and recursive feature optimization, our proposed method achieves performance gains, successfully detecting small and multiple camouflaged objects. Our model achieves state-of-the-art results on two benchmark datasets for camouflaged object detection and ranks second on the remaining two. Our codes, model weights, and results are available at \href{https://github.com/linaagh98/MSRNet}{https://github.com/linaagh98/MSRNet}.
SPEGNet: Synergistic Perception-Guided Network for Camouflaged Object Detection
Oct 06, 2025Camouflaged object detection segments objects with intrinsic similarity and edge disruption. Current detection methods rely on accumulated complex components. Each approach adds components such as boundary modules, attention mechanisms, and multi-scale processors independently. This accumulation creates a computational burden without proportional gains. To manage this complexity, they process at reduced resolutions, eliminating fine details essential for camouflage. We present SPEGNet, addressing fragmentation through a unified design. The architecture integrates multi-scale features via channel calibration and spatial enhancement. Boundaries emerge directly from context-rich representations, maintaining semantic-spatial alignment. Progressive refinement implements scale-adaptive edge modulation with peak influence at intermediate resolutions. This design strikes a balance between boundary precision and regional consistency. SPEGNet achieves 0.887 $S_\alpha$ on CAMO, 0.890 on COD10K, and 0.895 on NC4K, with real-time inference speed. Our approach excels across scales, from tiny, intricate objects to large, pattern-similar ones, while handling occlusion and ambiguous boundaries. Code, model weights, and results are available on \href{https://github.com/Baber-Jan/SPEGNet}{https://github.com/Baber-Jan/SPEGNet}.
MaskAdapt: Unsupervised Geometry-Aware Domain Adaptation Using Multimodal Contextual Learning and RGB-Depth Masking
May 29, 2025Semantic segmentation of crops and weeds is crucial for site-specific farm management; however, most existing methods depend on labor intensive pixel-level annotations. A further challenge arises when models trained on one field (source domain) fail to generalize to new fields (target domain) due to domain shifts, such as variations in lighting, camera setups, soil composition, and crop growth stages. Unsupervised Domain Adaptation (UDA) addresses this by enabling adaptation without target-domain labels, but current UDA methods struggle with occlusions and visual blending between crops and weeds, leading to misclassifications in real-world conditions. To overcome these limitations, we introduce MaskAdapt, a novel approach that enhances segmentation accuracy through multimodal contextual learning by integrating RGB images with features derived from depth data. By computing depth gradients from depth maps, our method captures spatial transitions that help resolve texture ambiguities. These gradients, through a cross-attention mechanism, refines RGB feature representations, resulting in sharper boundary delineation. In addition, we propose a geometry-aware masking strategy that applies horizontal, vertical, and stochastic masks during training. This encourages the model to focus on the broader spatial context for robust visual recognition. Evaluations on real agricultural datasets demonstrate that MaskAdapt consistently outperforms existing State-of-the-Art (SOTA) UDA methods, achieving improved segmentation mean Intersection over Union (mIOU) across diverse field conditions.
PointDiffuse: A Dual-Conditional Diffusion Model for Enhanced Point Cloud Semantic Segmentation
Mar 11, 2025



Diffusion probabilistic models are traditionally used to generate colors at fixed pixel positions in 2D images. Building on this, we extend diffusion models to point cloud semantic segmentation, where point positions also remain fixed, and the diffusion model generates point labels instead of colors. To accelerate the denoising process in reverse diffusion, we introduce a noisy label embedding mechanism. This approach integrates semantic information into the noisy label, providing an initial semantic reference that improves the reverse diffusion efficiency. Additionally, we propose a point frequency transformer that enhances the adjustment of high-level context in point clouds. To reduce computational complexity, we introduce the position condition into MLP and propose denoising PointNet to process the high-resolution point cloud without sacrificing geometric details. Finally, we integrate the proposed noisy label embedding, point frequency transformer and denoising PointNet in our proposed dual conditional diffusion model-based network (PointDiffuse) to perform large-scale point cloud semantic segmentation. Extensive experiments on five benchmarks demonstrate the superiority of PointDiffuse, achieving the state-of-the-art mIoU of 74.2\% on S3DIS Area 5, 81.2\% on S3DIS 6-fold and 64.8\% on SWAN dataset.
A Lightweight Model for Perceptual Image Compression via Implicit Priors
Feb 19, 2025Perceptual image compression has shown strong potential for producing visually appealing results at low bitrates, surpassing classical standards and pixel-wise distortion-oriented neural methods. However, existing methods typically improve compression performance by incorporating explicit semantic priors, such as segmentation maps and textual features, into the encoder or decoder, which increases model complexity by adding parameters and floating-point operations. This limits the model's practicality, as image compression often occurs on resource-limited mobile devices. To alleviate this problem, we propose a lightweight perceptual Image Compression method using Implicit Semantic Priors (ICISP). We first develop an enhanced visual state space block that exploits local and global spatial dependencies to reduce redundancy. Since different frequency information contributes unequally to compression, we develop a frequency decomposition modulation block to adaptively preserve or reduce the low-frequency and high-frequency information. We establish the above blocks as the main modules of the encoder-decoder, and to further improve the perceptual quality of the reconstructed images, we develop a semantic-informed discriminator that uses implicit semantic priors from a pretrained DINOv2 encoder. Experiments on popular benchmarks show that our method achieves competitive compression performance and has significantly fewer network parameters and floating point operations than the existing state-of-the-art.