 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualThink-VLA: Visual Intermediate Reasoning for Effective and Low-Latency Vision-Language-Action Policies
May 28, 2026Recent work has begun to equip vision-language-action (VLA) policies with explicit intermediate reasoning. In embodied control, however, textual chain-of-thought is a poor fit: irrelevant or weakly textual information can interfere with action prediction, while autoregressive text decoding adds too much latency for real-time closed-loop execution. We present VISUALTHINK-VLA, a visual intermediate-reasoning framework for accurate, low-latency VLA policies. Our bootstrapping philosophy is to guide action with effective visual thinking: VISUALTHINK-VLA bootstraps action prediction through a compact visual-evidence interface that preserves spatial precision while avoiding decoding overhead. Besides, to further improve performance and efficiency, VISUALTHINK-VLA adopts a tailored selective routing mechanism to learn the visual evidence tokens, enabling low-latency inference while preserving high-capacity specialization. We also introduce VisualEvidence-Kit, a supervision-and-audit resource centered on a VisualEvidence-Agent that constructs a 754.7k VLA instructions VisualEvidence-Set for route supervision and counterfactual faithfulness tests. Across multiple benchmarks and real-robot evaluation, VISUALTHINK-VLA achieves the highest success rate on most benchmarks while reducing the multi-second latency of reasoning-augmented baselines to the sub-second regime. For example, on BridgeData V2, it reduces step latency from 8.377,s with ECoT to 0.367,s, achieving a 22.8 times speedup.
MAIGO: Mitigating Lost-in-Conversation with History-Cleaned On-Policy Self-Distillation
May 26, 2026Large language models often solve tasks from a fully specified prompt but degrade when the same requirements unfold over multiple turns, known as the lost-in-conversation (LiC) gap. We trace part of this degradation to self-contamination: intermediate assistant replies enter later context and carry early deviations forward. Motivated by this mechanism, we propose MAIGO, an on-policy self-distillation method that reduces this contamination using history-cleaned references from the model's own policy. For middle turns, MAIGO removes prior assistant replies while preserving the user-visible sharded prefix; for answer turns, it distills from paired full-view references conditioned on the completed user-side dialogue. A reliability weight downweights middle-turn samples that disagree with the clean reference. MAIGO requires no verifier rewards, state labels, or inference-time scaffolding. Under the LiC paired-view protocol with deterministic verifiers, MAIGO improves Qwen2.5-7B-Instruct SHARDED accuracy from 52.8 to 66.1 and the SHARDED/FULL ratio from 66.5% to 84.1%, while keeping FULL accuracy within 2.3 points. These results show that self-contamination is a trainable component of the LiC gap.
Efficient Serving for Dynamic Agent Workflows with Prediction-based KV-Cache Management
May 07, 2026LLM-based workflows compose specialized agents to execute complex tasks, and these agents usually share substantial context, allowing KV-Cache reuse to save computation. Existing approaches either manage KV-Cache at agent level and fail to exploit the reuse opportunities within workflows, or manage cache at the workflow level but assume that each workflow calls a static sequence of agents. However, practical workflows are typically dynamic, where the sequence of invoked agents and thus induced cache reuse opportunities depend on the context of each task. To serve such dynamic workflows efficiently, we build a system dubbed PBKV (\textbf{P}rediction-\textbf{B}ased \textbf{KV}-Cache Management). For each workflow, PBKV predicts the agent invocations in several future steps by fusing the guidance from historical workflows and context of the target workflow. Based on the predictions, PBKV estimates the reuse potential of cache entries and keeps the high-potential entries in GPU memory. To be robust to prediction errors, PBKV utilizes the predictions conservatively during both cache eviction and prefetching. Experiments on three workflow benchmarks show that PBKV achieves up to $1.85\times$ speedup over LRU on dynamic workflows, and up to $1.26\times$ speedup over the SOTA baseline KVFlow on the static workflow.
IAD-Unify: A Region-Grounded Unified Model for Industrial Anomaly Segmentation, Understanding, and Generation
Apr 14, 2026Real-world industrial inspection requires not only localizing defects, but also explaining them in natural language and generating controlled defect edits. However, existing approaches fail to jointly support all three capabilities within a unified framework and evaluation protocol. We propose IAD-Unify, a dual-encoder unified framework in which a frozen DINOv2-based region expert supplies precise anomaly evidence to a shared Qwen3.5-4B vision-language backbone via lightweight token injection, jointly enabling anomaly segmentation, region-grounded understanding, and mask-guided generation. To enable unified evaluation, we further construct Anomaly-56K, a comprehensive unified multi-task IAD evaluation platform, spanning 59,916 images across 24 categories and 104 defect variants. Controlled ablations yield four findings: (i) region grounding is the decisive mechanism for understanding, removing it degrades location accuracy by >76 pp; (ii) predicted-region performance closely matches oracle, confirming deployment viability; (iii) region-grounded generation achieves the best full-image fidelity and masked-region perceptual quality; and (iv) pre-initialized joint training improves understanding at negligible generation cost (-0.16 dB). IAD-Unify further achieves strong performance on the MMAD benchmark, including categories unseen during training, demonstrating robust cross-category generalization.
Scheduling LLM Inference with Uncertainty-Aware Output Length Predictions
Apr 01, 2026To schedule LLM inference, the \textit{shortest job first} (SJF) principle is favorable by prioritizing requests with short output lengths to avoid head-of-line (HOL) blocking. Existing methods usually predict a single output length for each request to facilitate scheduling. We argue that such a \textit{point estimate} does not match the \textit{stochastic} decoding process of LLM inference, where output length is \textit{uncertain} by nature and determined by when the end-of-sequence (EOS) token is sampled. Hence, the output length of each request should be fitted with a distribution rather than a single value. With an in-depth analysis of empirical data and the stochastic decoding process, we observe that output length follows a heavy-tailed distribution and can be fitted with the log-t distribution. On this basis, we propose a simple metric called Tail Inflated Expectation (TIE) to replace the output length in SJF scheduling, which adjusts the expectation of a log-t distribution with its tail probabilities to account for the risk that a request generates long outputs. To evaluate our TIE scheduler, we compare it with three strong baselines, and the results show that TIE reduces the per-token latency by $2.31\times$ for online inference and improves throughput by $1.42\times$ for offline data generation.
Unified Personalized Understanding, Generating and Editing
Jan 11, 2026Unified large multimodal models (LMMs) have achieved remarkable progress in general-purpose multimodal understanding and generation. However, they still operate under a ``one-size-fits-all'' paradigm and struggle to model user-specific concepts (e.g., generate a photo of \texttt{<maeve>}) in a consistent and controllable manner. Existing personalization methods typically rely on external retrieval, which is inefficient and poorly integrated into unified multimodal pipelines. Recent personalized unified models introduce learnable soft prompts to encode concept information, yet they either couple understanding and generation or depend on complex multi-stage training, leading to cross-task interference and ultimately to fuzzy or misaligned personalized knowledge. We present \textbf{OmniPersona}, an end-to-end personalization framework for unified LMMs that, for the first time, integrates personalized understanding, generation, and image editing within a single architecture. OmniPersona introduces structurally decoupled concept tokens, allocating dedicated subspaces for different tasks to minimize interference, and incorporates an explicit knowledge replay mechanism that propagates personalized attribute knowledge across tasks, enabling consistent personalized behavior. To systematically evaluate unified personalization, we propose \textbf{\texttt{OmniPBench}}, extending the public UnifyBench concept set with personalized editing tasks and cross-task evaluation protocols integrating understanding, generation, and editing. Experimental results demonstrate that OmniPersona delivers competitive and robust performance across diverse personalization tasks. We hope OmniPersona will serve as a strong baseline and spur further research on controllable, unified personalization.
Retrieval Augmented Comic Image Generation
Jun 14, 2025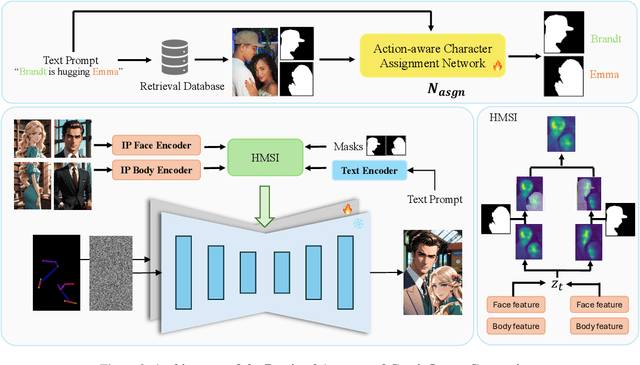



We present RaCig, a novel system for generating comic-style image sequences with consistent characters and expressive gestures. RaCig addresses two key challenges: (1) maintaining character identity and costume consistency across frames, and (2) producing diverse and vivid character gestures. Our approach integrates a retrieval-based character assignment module, which aligns characters in textual prompts with reference images, and a regional character injection mechanism that embeds character features into specified image regions. Experimental results demonstrate that RaCig effectively generates engaging comic narratives with coherent characters and dynamic interactions. The source code will be publicly available to support further research in this area.
SOYO: A Tuning-Free Approach for Video Style Morphing via Style-Adaptive Interpolation in Diffusion Models
Mar 10, 2025Diffusion models have achieved remarkable progress in image and video stylization. However, most existing methods focus on single-style transfer, while video stylization involving multiple styles necessitates seamless transitions between them. We refer to this smooth style transition between video frames as video style morphing. Current approaches often generate stylized video frames with discontinuous structures and abrupt style changes when handling such transitions. To address these limitations, we introduce SOYO, a novel diffusion-based framework for video style morphing. Our method employs a pre-trained text-to-image diffusion model without fine-tuning, combining attention injection and AdaIN to preserve structural consistency and enable smooth style transitions across video frames. Moreover, we notice that applying linear equidistant interpolation directly induces imbalanced style morphing. To harmonize across video frames, we propose a novel adaptive sampling scheduler operating between two style images. Extensive experiments demonstrate that SOYO outperforms existing methods in open-domain video style morphing, better preserving the structural coherence of video frames while achieving stable and smooth style transitions.
Multi-Class Segmentation of Aortic Branches and Zones in Computed Tomography Angiography: The AortaSeg24 Challenge
Feb 07, 2025



Multi-class segmentation of the aorta in computed tomography angiography (CTA) scans is essential for diagnosing and planning complex endovascular treatments for patients with aortic dissections. However, existing methods reduce aortic segmentation to a binary problem, limiting their ability to measure diameters across different branches and zones. Furthermore, no open-source dataset is currently available to support the development of multi-class aortic segmentation methods. To address this gap, we organized the AortaSeg24 MICCAI Challenge, introducing the first dataset of 100 CTA volumes annotated for 23 clinically relevant aortic branches and zones. This dataset was designed to facilitate both model development and validation. The challenge attracted 121 teams worldwide, with participants leveraging state-of-the-art frameworks such as nnU-Net and exploring novel techniques, including cascaded models, data augmentation strategies, and custom loss functions. We evaluated the submitted algorithms using the Dice Similarity Coefficient (DSC) and Normalized Surface Distance (NSD), highlighting the approaches adopted by the top five performing teams. This paper presents the challenge design, dataset details, evaluation metrics, and an in-depth analysis of the top-performing algorithms. The annotated dataset, evaluation code, and implementations of the leading methods are publicly available to support further research. All resources can be accessed at https://aortaseg24.grand-challenge.org.
MAKIMA: Tuning-free Multi-Attribute Open-domain Video Editing via Mask-Guided Attention Modulation
Dec 28, 2024



Diffusion-based text-to-image (T2I) models have demonstrated remarkable results in global video editing tasks. However, their focus is primarily on global video modifications, and achieving desired attribute-specific changes remains a challenging task, specifically in multi-attribute editing (MAE) in video. Contemporary video editing approaches either require extensive fine-tuning or rely on additional networks (such as ControlNet) for modeling multi-object appearances, yet they remain in their infancy, offering only coarse-grained MAE solutions. In this paper, we present MAKIMA, a tuning-free MAE framework built upon pretrained T2I models for open-domain video editing. Our approach preserves video structure and appearance information by incorporating attention maps and features from the inversion process during denoising. To facilitate precise editing of multiple attributes, we introduce mask-guided attention modulation, enhancing correlations between spatially corresponding tokens and suppressing cross-attribute interference in both self-attention and cross-attention layers. To balance video frame generation quality and efficiency, we implement consistent feature propagation, which generates frame sequences by editing keyframes and propagating their features throughout the sequence. Extensive experiments demonstrate that MAKIMA outperforms existing baselines in open-domain multi-attribute video editing tasks, achieving superior results in both editing accuracy and temporal consistency while maintaining computational efficiency.