 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHERMES: Human-to-Robot Embodied Learning from Multi-Source Motion Data for Mobile Dexterous Manipulation
Aug 28, 2025Leveraging human motion data to impart robots with versatile manipulation skills has emerged as a promising paradigm in robotic manipulation. Nevertheless, translating multi-source human hand motions into feasible robot behaviors remains challenging, particularly for robots equipped with multi-fingered dexterous hands characterized by complex, high-dimensional action spaces. Moreover, existing approaches often struggle to produce policies capable of adapting to diverse environmental conditions. In this paper, we introduce HERMES, a human-to-robot learning framework for mobile bimanual dexterous manipulation. First, HERMES formulates a unified reinforcement learning approach capable of seamlessly transforming heterogeneous human hand motions from multiple sources into physically plausible robotic behaviors. Subsequently, to mitigate the sim2real gap, we devise an end-to-end, depth image-based sim2real transfer method for improved generalization to real-world scenarios. Furthermore, to enable autonomous operation in varied and unstructured environments, we augment the navigation foundation model with a closed-loop Perspective-n-Point (PnP) localization mechanism, ensuring precise alignment of visual goals and effectively bridging autonomous navigation and dexterous manipulation. Extensive experimental results demonstrate that HERMES consistently exhibits generalizable behaviors across diverse, in-the-wild scenarios, successfully performing numerous complex mobile bimanual dexterous manipulation tasks. Project Page:https://gemcollector.github.io/HERMES/.
H$^{\mathbf{3}}$DP: Triply-Hierarchical Diffusion Policy for Visuomotor Learning
May 12, 2025Visuomotor policy learning has witnessed substantial progress in robotic manipulation, with recent approaches predominantly relying on generative models to model the action distribution. However, these methods often overlook the critical coupling between visual perception and action prediction. In this work, we introduce $\textbf{Triply-Hierarchical Diffusion Policy}~(\textbf{H$^{\mathbf{3}}$DP})$, a novel visuomotor learning framework that explicitly incorporates hierarchical structures to strengthen the integration between visual features and action generation. H$^{3}$DP contains $\mathbf{3}$ levels of hierarchy: (1) depth-aware input layering that organizes RGB-D observations based on depth information; (2) multi-scale visual representations that encode semantic features at varying levels of granularity; and (3) a hierarchically conditioned diffusion process that aligns the generation of coarse-to-fine actions with corresponding visual features. Extensive experiments demonstrate that H$^{3}$DP yields a $\mathbf{+27.5\%}$ average relative improvement over baselines across $\mathbf{44}$ simulation tasks and achieves superior performance in $\mathbf{4}$ challenging bimanual real-world manipulation tasks. Project Page: https://lyy-iiis.github.io/h3dp/.
Stem-OB: Generalizable Visual Imitation Learning with Stem-Like Convergent Observation through Diffusion Inversion
Nov 07, 2024



Visual imitation learning methods demonstrate strong performance, yet they lack generalization when faced with visual input perturbations, including variations in lighting and textures, impeding their real-world application. We propose Stem-OB that utilizes pretrained image diffusion models to suppress low-level visual differences while maintaining high-level scene structures. This image inversion process is akin to transforming the observation into a shared representation, from which other observations stem, with extraneous details removed. Stem-OB contrasts with data-augmentation approaches as it is robust to various unspecified appearance changes without the need for additional training. Our method is a simple yet highly effective plug-and-play solution. Empirical results confirm the effectiveness of our approach in simulated tasks and show an exceptionally significant improvement in real-world applications, with an average increase of 22.2% in success rates compared to the best baseline. See https://hukz18.github.io/Stem-Ob/ for more info.
On the Evaluation of Generative Robotic Simulations
Oct 10, 2024



Due to the difficulty of acquiring extensive real-world data, robot simulation has become crucial for parallel training and sim-to-real transfer, highlighting the importance of scalable simulated robotic tasks. Foundation models have demonstrated impressive capacities in autonomously generating feasible robotic tasks. However, this new paradigm underscores the challenge of adequately evaluating these autonomously generated tasks. To address this, we propose a comprehensive evaluation framework tailored to generative simulations. Our framework segments evaluation into three core aspects: quality, diversity, and generalization. For single-task quality, we evaluate the realism of the generated task and the completeness of the generated trajectories using large language models and vision-language models. In terms of diversity, we measure both task and data diversity through text similarity of task descriptions and world model loss trained on collected task trajectories. For task-level generalization, we assess the zero-shot generalization ability on unseen tasks of a policy trained with multiple generated tasks. Experiments conducted on three representative task generation pipelines demonstrate that the results from our framework are highly consistent with human evaluations, confirming the feasibility and validity of our approach. The findings reveal that while metrics of quality and diversity can be achieved through certain methods, no single approach excels across all metrics, suggesting a need for greater focus on balancing these different metrics. Additionally, our analysis further highlights the common challenge of low generalization capability faced by current works. Our anonymous website: https://sites.google.com/view/evaltasks.
GenSim2: Scaling Robot Data Generation with Multi-modal and Reasoning LLMs
Oct 04, 2024



Robotic simulation today remains challenging to scale up due to the human efforts required to create diverse simulation tasks and scenes. Simulation-trained policies also face scalability issues as many sim-to-real methods focus on a single task. To address these challenges, this work proposes GenSim2, a scalable framework that leverages coding LLMs with multi-modal and reasoning capabilities for complex and realistic simulation task creation, including long-horizon tasks with articulated objects. To automatically generate demonstration data for these tasks at scale, we propose planning and RL solvers that generalize within object categories. The pipeline can generate data for up to 100 articulated tasks with 200 objects and reduce the required human efforts. To utilize such data, we propose an effective multi-task language-conditioned policy architecture, dubbed proprioceptive point-cloud transformer (PPT), that learns from the generated demonstrations and exhibits strong sim-to-real zero-shot transfer. Combining the proposed pipeline and the policy architecture, we show a promising usage of GenSim2 that the generated data can be used for zero-shot transfer or co-train with real-world collected data, which enhances the policy performance by 20% compared with training exclusively on limited real data.
DrM: Mastering Visual Reinforcement Learning through Dormant Ratio Minimization
Oct 30, 2023Visual reinforcement learning (RL) has shown promise in continuous control tasks. Despite its progress, current algorithms are still unsatisfactory in virtually every aspect of the performance such as sample efficiency, asymptotic performance, and their robustness to the choice of random seeds. In this paper, we identify a major shortcoming in existing visual RL methods that is the agents often exhibit sustained inactivity during early training, thereby limiting their ability to explore effectively. Expanding upon this crucial observation, we additionally unveil a significant correlation between the agents' inclination towards motorically inactive exploration and the absence of neuronal activity within their policy networks. To quantify this inactivity, we adopt dormant ratio as a metric to measure inactivity in the RL agent's network. Empirically, we also recognize that the dormant ratio can act as a standalone indicator of an agent's activity level, regardless of the received reward signals. Leveraging the aforementioned insights, we introduce DrM, a method that uses three core mechanisms to guide agents' exploration-exploitation trade-offs by actively minimizing the dormant ratio. Experiments demonstrate that DrM achieves significant improvements in sample efficiency and asymptotic performance with no broken seeds (76 seeds in total) across three continuous control benchmark environments, including DeepMind Control Suite, MetaWorld, and Adroit. Most importantly, DrM is the first model-free algorithm that consistently solves tasks in both the Dog and Manipulator domains from the DeepMind Control Suite as well as three dexterous hand manipulation tasks without demonstrations in Adroit, all based on pixel observations.
RL-ViGen: A Reinforcement Learning Benchmark for Visual Generalization
Jul 15, 2023Visual Reinforcement Learning (Visual RL), coupled with high-dimensional observations, has consistently confronted the long-standing challenge of generalization. Despite the focus on algorithms aimed at resolving visual generalization problems, we argue that the devil is in the existing benchmarks as they are restricted to isolated tasks and generalization categories, undermining a comprehensive evaluation of agents' visual generalization capabilities. To bridge this gap, we introduce RL-ViGen: a novel Reinforcement Learning Benchmark for Visual Generalization, which contains diverse tasks and a wide spectrum of generalization types, thereby facilitating the derivation of more reliable conclusions. Furthermore, RL-ViGen incorporates the latest generalization visual RL algorithms into a unified framework, under which the experiment results indicate that no single existing algorithm has prevailed universally across tasks. Our aspiration is that RL-ViGen will serve as a catalyst in this area, and lay a foundation for the future creation of universal visual generalization RL agents suitable for real-world scenarios. Access to our code and implemented algorithms is provided at https://gemcollector.github.io/RL-ViGen/.
Simple Emergent Action Representations from Multi-Task Policy Training
Oct 18, 2022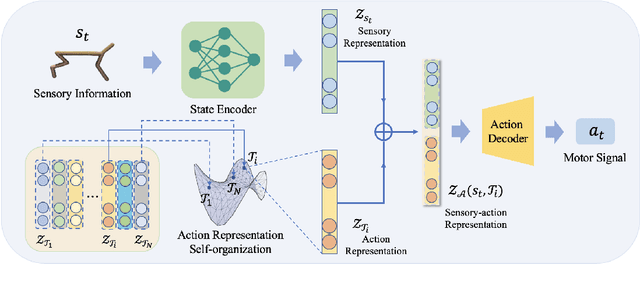

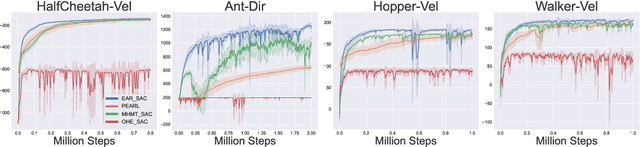

Low-level sensory and motor signals in the high-dimensional spaces (e.g., image observations or motor torques) in deep reinforcement learning are complicated to understand or harness for downstream tasks directly. While sensory representations have been widely studied, the representations of actions that form motor skills are yet under exploration. In this work, we find that when a multi-task policy network takes as input states and task embeddings, a space based on the task embeddings emerges to contain meaningful action representations with moderate constraints. Within this space, interpolated or composed embeddings can serve as a high-level interface to instruct the agent to perform meaningful action sequences. Empirical results not only show that the proposed action representations have efficacy for intra-action interpolation and inter-action composition with limited or no learning, but also demonstrate their superior ability in task adaptation to strong baselines in Mujoco locomotion tasks. The evidence elucidates that learning action representations is a promising direction toward efficient, adaptable, and composable RL, forming the basis of abstract action planning and the understanding of motor signal space. Anonymous project page: https://sites.google.com/view/emergent-action-representation/