 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Latency Denial-of-Service: Attacking the LLM Serving Framework, Not the Model
Feb 08, 2026Large Language Models face an emerging and critical threat known as latency attacks. Because LLM inference is inherently expensive, even modest slowdowns can translate into substantial operating costs and severe availability risks. Recently, a growing body of research has focused on algorithmic complexity attacks by crafting inputs to trigger worst-case output lengths. However, we report a counter-intuitive finding that these algorithmic latency attacks are largely ineffective against modern LLM serving systems. We reveal that system-level optimization such as continuous batching provides a logical isolation to mitigate contagious latency impact on co-located users. To this end, in this paper, we shift the focus from the algorithm to the system layer, and introduce a new Fill and Squeeze attack strategy targeting the state transition of the scheduler. "Fill" first exhausts the global KV cache to induce Head-of-Line blocking, while "Squeeze" forces the system into repetitive preemption. By manipulating output lengths using methods from simple plain-text prompts to more complex prompt engineering, and leveraging side-channel probing of memory status, we demonstrate that the attack can be orchestrated in a black-box setting with much less cost. Extensive evaluations indicate by up to 20-280x average slowdown on Time to First Token and 1.5-4x average slowdown on Time Per Output Token compared to existing attacks with 30-40% lower attack cost.
DeepGuard: Defending Deep Joint Source-Channel Coding Against Eavesdropping at Physical-Layer
Dec 21, 2025



Deep joint source-channel coding (DeepJSCC) has emerged as a promising paradigm for efficient and robust information transmission. However, its intrinsic characteristics also pose new security challenges, notably an increased vulnerability to eavesdropping attacks. Existing studies on defending against eavesdropping attacks in DeepJSCC, while demonstrating certain effectiveness, often incur considerable computational overhead or introduce performance trade-offs that may adversely affect legitimate users. In this paper, we present DeepGuard, to the best of our knowledge, the first physical-layer defense framework for DeepJSCC against eavesdropping attacks, validated through over-the-air experiments using software-defined radios (SDRs). Considering that existing eavesdropping attacks against DeepJSCC are limited to simulation under ideal channels, we take a step further by identifying and implementing four representative types of attacks under various configurations in orthogonal frequency-division multiplexing systems. These attacks are evaluated over-the-air under diverse scenarios, allowing us to comprehensively characterize the real-world threat landscape. To mitigate these threats, DeepGuard introduces a novel preamble perturbation mechanism that modifies the preamble shared only between legitimate transceivers. To realize it, we first conduct a theoretical analysis of the perturbation's impact on the signals intercepted by the eavesdropper. Building upon this, we develop an end-to-end perturbation optimization algorithm that significantly degrades eavesdropping performance while preserving reliable communication for legitimate users. We prototype DeepGuard using SDRs and conduct extensive over-the-air experiments in practical scenarios. Extensive experiments demonstrate that DeepGuard effectively mitigates eavesdropping threats.
Empowering Agentic Video Analytics Systems with Video Language Models
May 02, 2025



AI-driven video analytics has become increasingly pivotal across diverse domains. However, existing systems are often constrained to specific, predefined tasks, limiting their adaptability in open-ended analytical scenarios. The recent emergence of Video-Language Models (VLMs) as transformative technologies offers significant potential for enabling open-ended video understanding, reasoning, and analytics. Nevertheless, their limited context windows present challenges when processing ultra-long video content, which is prevalent in real-world applications. To address this, we introduce AVAS, a VLM-powered system designed for open-ended, advanced video analytics. AVAS incorporates two key innovations: (1) the near real-time construction of Event Knowledge Graphs (EKGs) for efficient indexing of long or continuous video streams, and (2) an agentic retrieval-generation mechanism that leverages EKGs to handle complex and diverse queries. Comprehensive evaluations on public benchmarks, LVBench and VideoMME-Long, demonstrate that AVAS achieves state-of-the-art performance, attaining 62.3% and 64.1% accuracy, respectively, significantly surpassing existing VLM and video Retrieval-Augmented Generation (RAG) systems. Furthermore, to evaluate video analytics in ultra-long and open-world video scenarios, we introduce a new benchmark, AVAS-100. This benchmark comprises 8 videos, each exceeding 10 hours in duration, along with 120 manually annotated, diverse, and complex question-answer pairs. On AVAS-100, AVAS achieves top-tier performance with an accuracy of 75.8%.
Underload: Defending against Latency Attacks for Object Detectors on Edge Devices
Dec 03, 2024Object detection is a fundamental enabler for many real-time downstream applications such as autonomous driving, augmented reality and supply chain management. However, the algorithmic backbone of neural networks is brittle to imperceptible perturbations in the system inputs, which were generally known as misclassifying attacks. By targeting the real-time processing capability, a new class of latency attacks are reported recently. They exploit new attack surfaces in object detectors by creating a computational bottleneck in the post-processing module, that leads to cascading failure and puts the real-time downstream tasks at risks. In this work, we take an initial attempt to defend against this attack via background-attentive adversarial training that is also cognizant of the underlying hardware capabilities. We first draw system-level connections between latency attack and hardware capacity across heterogeneous GPU devices. Based on the particular adversarial behaviors, we utilize objectness loss as a proxy and build background attention into the adversarial training pipeline, and achieve a reasonable balance between clean and robust accuracy. The extensive experiments demonstrate the defense effectiveness of restoring real-time processing capability from $13$ FPS to $43$ FPS on Jetson Orin NX, with a better trade-off between the clean and robust accuracy.
Confidant: Customizing Transformer-based LLMs via Collaborative Edge Training
Nov 22, 2023Transformer-based large language models (LLMs) have demonstrated impressive capabilities in a variety of natural language processing (NLP) tasks. Nonetheless, it is challenging to deploy and fine-tune LLMs on mobile edge devices with limited computing, memory, and energy budgets. In this paper, we propose Confidant, a multi-backend collaborative training framework for customizing state-of-the-art LLMs on commodity mobile devices like smartphones. Confidant partitions an LLM into several sub-models so that each fits into a mobile device's memory. A pipeline parallel training mechanism is further developed to ensure fast and efficient distributed training. In addition, we propose a novel backend scheduler to allocate different attention heads to heterogeneous compute hardware, including mobile CPU and GPUs, to maximize the compute resource utilization on each edge device. Our preliminary experimental results show that Confidant achieves at most 45.3% memory reduction and 8.03x inference speedup in practical settings.
AccEPT: An Acceleration Scheme for Speeding Up Edge Pipeline-parallel Training
Nov 10, 2023



It is usually infeasible to fit and train an entire large deep neural network (DNN) model using a single edge device due to the limited resources. To facilitate intelligent applications across edge devices, researchers have proposed partitioning a large model into several sub-models, and deploying each of them to a different edge device to collaboratively train a DNN model. However, the communication overhead caused by the large amount of data transmitted from one device to another during training, as well as the sub-optimal partition point due to the inaccurate latency prediction of computation at each edge device can significantly slow down training. In this paper, we propose AccEPT, an acceleration scheme for accelerating the edge collaborative pipeline-parallel training. In particular, we propose a light-weight adaptive latency predictor to accurately estimate the computation latency of each layer at different devices, which also adapts to unseen devices through continuous learning. Therefore, the proposed latency predictor leads to better model partitioning which balances the computation loads across participating devices. Moreover, we propose a bit-level computation-efficient data compression scheme to compress the data to be transmitted between devices during training. Our numerical results demonstrate that our proposed acceleration approach is able to significantly speed up edge pipeline parallel training up to 3 times faster in the considered experimental settings.
Turbo: Opportunistic Enhancement for Edge Video Analytics
Jun 29, 2022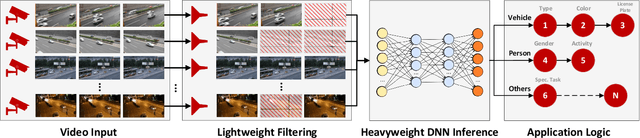
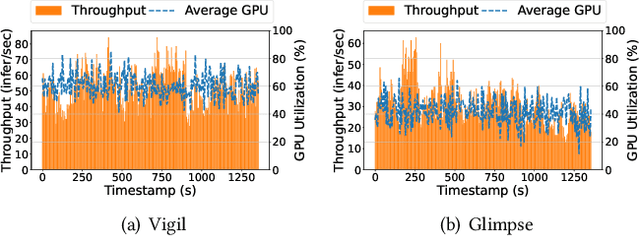
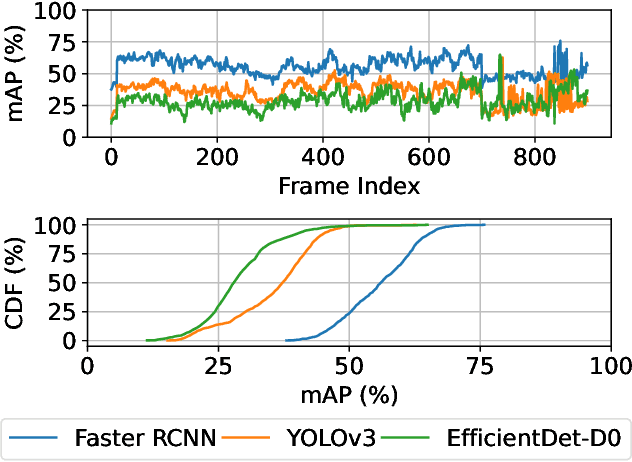
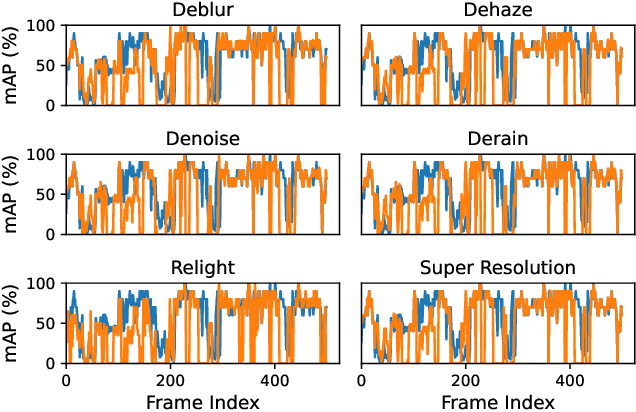
Edge computing is being widely used for video analytics. To alleviate the inherent tension between accuracy and cost, various video analytics pipelines have been proposed to optimize the usage of GPU on edge nodes. Nonetheless, we find that GPU compute resources provisioned for edge nodes are commonly under-utilized due to video content variations, subsampling and filtering at different places of a pipeline. As opposed to model and pipeline optimization, in this work, we study the problem of opportunistic data enhancement using the non-deterministic and fragmented idle GPU resources. In specific, we propose a task-specific discrimination and enhancement module and a model-aware adversarial training mechanism, providing a way to identify and transform low-quality images that are specific to a video pipeline in an accurate and efficient manner. A multi-exit model structure and a resource-aware scheduler is further developed to make online enhancement decisions and fine-grained inference execution under latency and GPU resource constraints. Experiments across multiple video analytics pipelines and datasets reveal that by judiciously allocating a small amount of idle resources on frames that tend to yield greater marginal benefits from enhancement, our system boosts DNN object detection accuracy by $7.3-11.3\%$ without incurring any latency costs.
GEMEL: Model Merging for Memory-Efficient, Real-Time Video Analytics at the Edge
Jan 19, 2022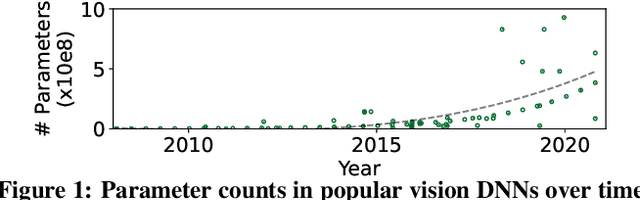
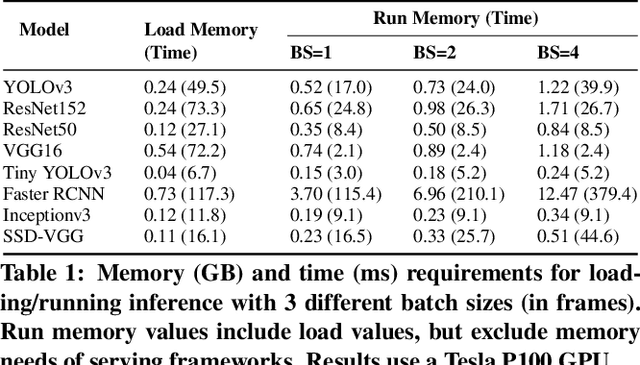
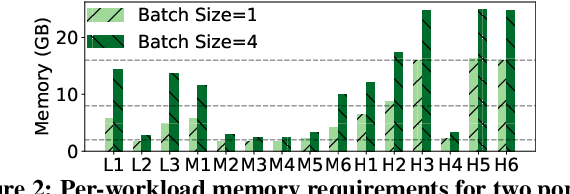

Video analytics pipelines have steadily shifted to edge deployments to reduce bandwidth overheads and privacy violations, but in doing so, face an ever-growing resource tension. Most notably, edge-box GPUs lack the memory needed to concurrently house the growing number of (increasingly complex) models for real-time inference. Unfortunately, existing solutions that rely on time/space sharing of GPU resources are insufficient as the required swapping delays result in unacceptable frame drops and accuracy violations. We present model merging, a new memory management technique that exploits architectural similarities between edge vision models by judiciously sharing their layers (including weights) to reduce workload memory costs and swapping delays. Our system, GEMEL, efficiently integrates merging into existing pipelines by (1) leveraging several guiding observations about per-model memory usage and inter-layer dependencies to quickly identify fruitful and accuracy-preserving merging configurations, and (2) altering edge inference schedules to maximize merging benefits. Experiments across diverse workloads reveal that GEMEL reduces memory usage by up to 60.7%, and improves overall accuracy by 8-39% relative to time/space sharing alone.
Custom Object Detection via Multi-Camera Self-Supervised Learning
Feb 05, 2021
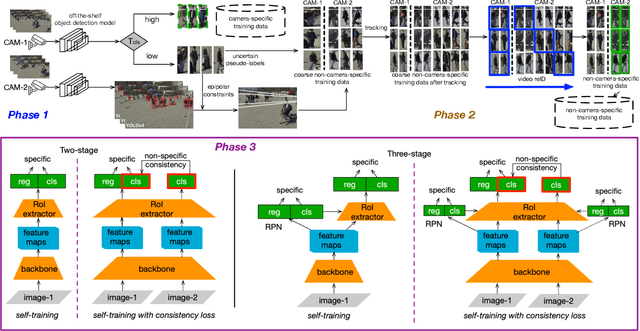
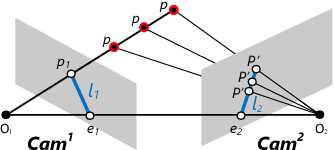
This paper proposes MCSSL, a self-supervised learning approach for building custom object detection models in multi-camera networks. MCSSL associates bounding boxes between cameras with overlapping fields of view by leveraging epipolar geometry and state-of-the-art tracking and reID algorithms, and prudently generates two sets of pseudo-labels to fine-tune backbone and detection networks respectively in an object detection model. To train effectively on pseudo-labels,a powerful reID-like pretext task with consistency loss is constructed for model customization. Our evaluation shows that compared with legacy selftraining methods, MCSSL improves average mAP by 5.44% and 6.76% on WildTrack and CityFlow dataset, respectively.
Ekya: Continuous Learning of Video Analytics Models on Edge Compute Servers
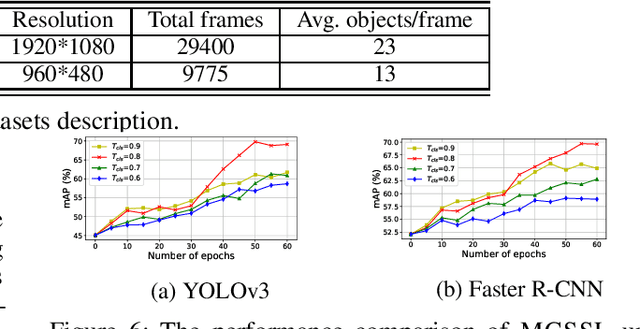
Dec 19, 2020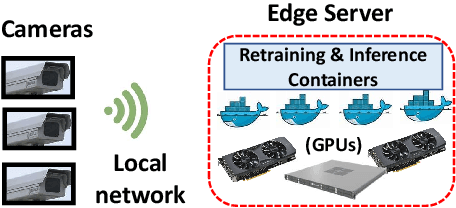
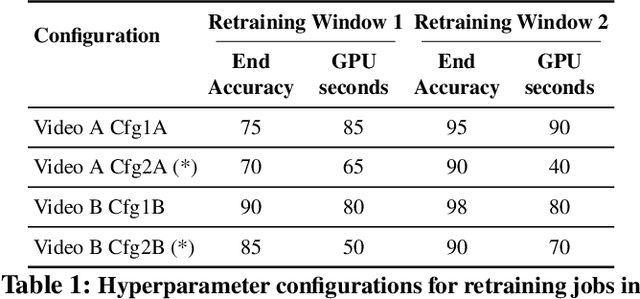
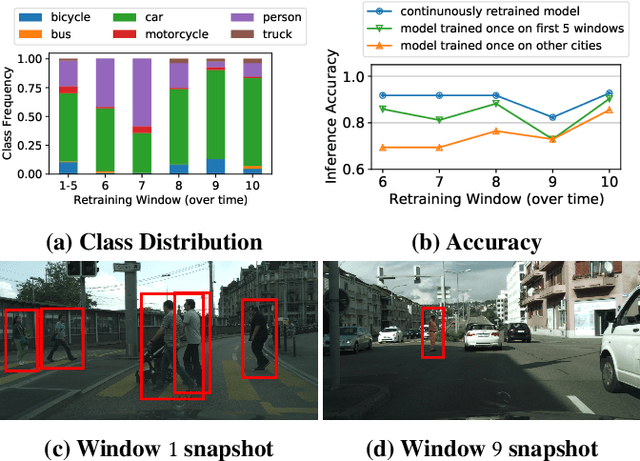

Video analytics applications use edge compute servers for the analytics of the videos (for bandwidth and privacy). Compressed models that are deployed on the edge servers for inference suffer from data drift, where the live video data diverges from the training data. Continuous learning handles data drift by periodically retraining the models on new data. Our work addresses the challenge of jointly supporting inference and retraining tasks on edge servers, which requires navigating the fundamental tradeoff between the retrained model's accuracy and the inference accuracy. Our solution Ekya balances this tradeoff across multiple models and uses a micro-profiler to identify the models that will benefit the most by retraining. Ekya's accuracy gain compared to a baseline scheduler is 29% higher, and the baseline requires 4x more GPU resources to achieve the same accuracy as Ekya.