 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperbolic Space with Hierarchical Margin Boosts Fine-Grained Learning from Coarse Labels
Nov 18, 2023Learning fine-grained embeddings from coarse labels is a challenging task due to limited label granularity supervision, i.e., lacking the detailed distinctions required for fine-grained tasks. The task becomes even more demanding when attempting few-shot fine-grained recognition, which holds practical significance in various applications. To address these challenges, we propose a novel method that embeds visual embeddings into a hyperbolic space and enhances their discriminative ability with a hierarchical cosine margins manner. Specifically, the hyperbolic space offers distinct advantages, including the ability to capture hierarchical relationships and increased expressive power, which favors modeling fine-grained objects. Based on the hyperbolic space, we further enforce relatively large/small similarity margins between coarse/fine classes, respectively, yielding the so-called hierarchical cosine margins manner. While enforcing similarity margins in the regular Euclidean space has become popular for deep embedding learning, applying it to the hyperbolic space is non-trivial and validating the benefit for coarse-to-fine generalization is valuable. Extensive experiments conducted on five benchmark datasets showcase the effectiveness of our proposed method, yielding state-of-the-art results surpassing competing methods.
Watch out Venomous Snake Species: A Solution to SnakeCLEF2023
Jul 19, 2023The SnakeCLEF2023 competition aims to the development of advanced algorithms for snake species identification through the analysis of images and accompanying metadata. This paper presents a method leveraging utilization of both images and metadata. Modern CNN models and strong data augmentation are utilized to learn better representation of images. To relieve the challenge of long-tailed distribution, seesaw loss is utilized in our method. We also design a light model to calculate prior probabilities using metadata features extracted from CLIP in post processing stage. Besides, we attach more importance to venomous species by assigning venomous species labels to some examples that model is uncertain about. Our method achieves 91.31% score of the final metric combined of F1 and other metrics on private leaderboard, which is the 1st place among the participators. The code is available at https://github.com/xiaoxsparraw/CLEF2023.
Delving Deep into Simplicity Bias for Long-Tailed Image Recognition
Feb 07, 2023



Simplicity Bias (SB) is a phenomenon that deep neural networks tend to rely favorably on simpler predictive patterns but ignore some complex features when applied to supervised discriminative tasks. In this work, we investigate SB in long-tailed image recognition and find the tail classes suffer more severely from SB, which harms the generalization performance of such underrepresented classes. We empirically report that self-supervised learning (SSL) can mitigate SB and perform in complementary to the supervised counterpart by enriching the features extracted from tail samples and consequently taking better advantage of such rare samples. However, standard SSL methods are designed without explicitly considering the inherent data distribution in terms of classes and may not be optimal for long-tailed distributed data. To address this limitation, we propose a novel SSL method tailored to imbalanced data. It leverages SSL by triple diverse levels, i.e., holistic-, partial-, and augmented-level, to enhance the learning of predictive complex patterns, which provides the potential to overcome the severe SB on tail data. Both quantitative and qualitative experimental results on five long-tailed benchmark datasets show our method can effectively mitigate SB and significantly outperform the competing state-of-the-arts.
An Embarrassingly Simple Approach to Semi-Supervised Few-Shot Learning
Sep 28, 2022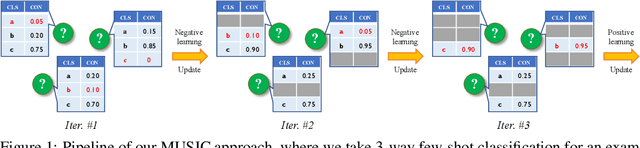
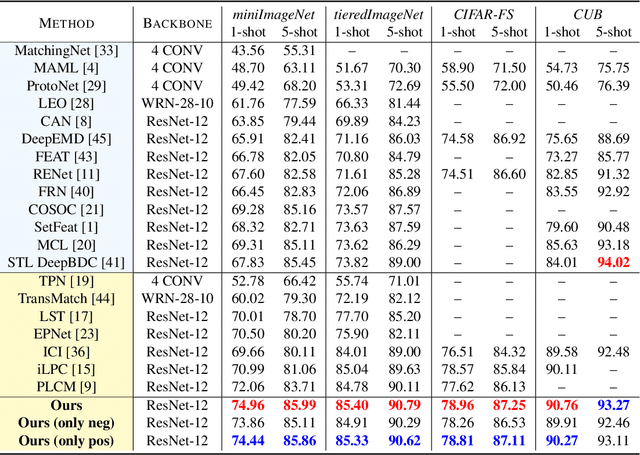
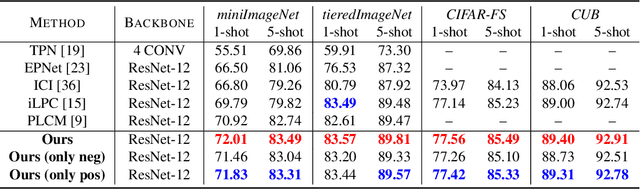
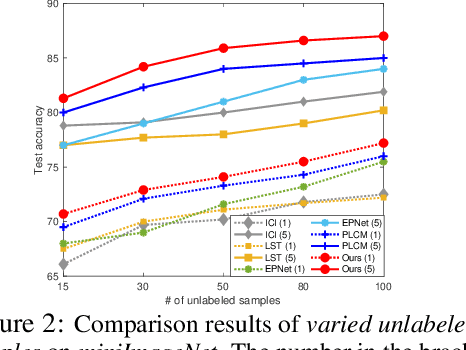
Semi-supervised few-shot learning consists in training a classifier to adapt to new tasks with limited labeled data and a fixed quantity of unlabeled data. Many sophisticated methods have been developed to address the challenges this problem comprises. In this paper, we propose a simple but quite effective approach to predict accurate negative pseudo-labels of unlabeled data from an indirect learning perspective, and then augment the extremely label-constrained support set in few-shot classification tasks. Our approach can be implemented in just few lines of code by only using off-the-shelf operations, yet it is able to outperform state-of-the-art methods on four benchmark datasets.
Monotonic Neural Network: combining Deep Learning with Domain Knowledge for Chiller Plants Energy Optimization
Jun 11, 2021
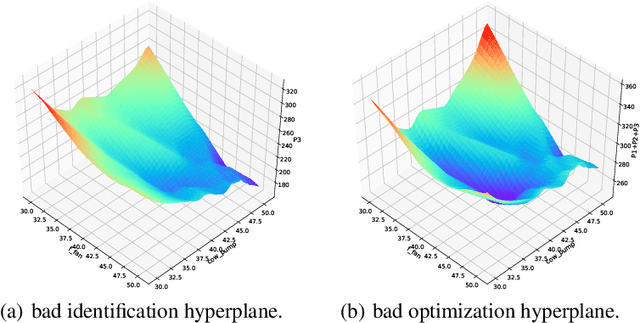
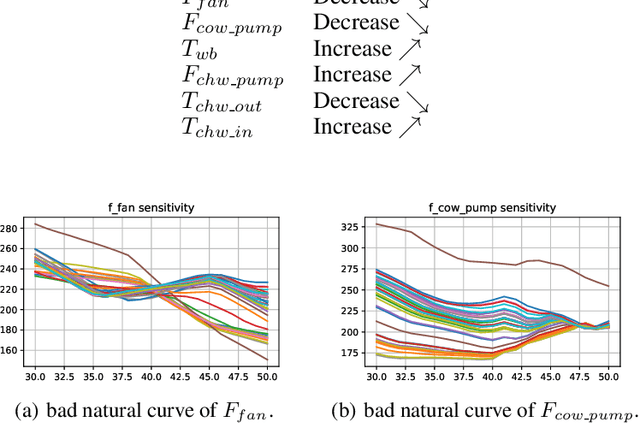
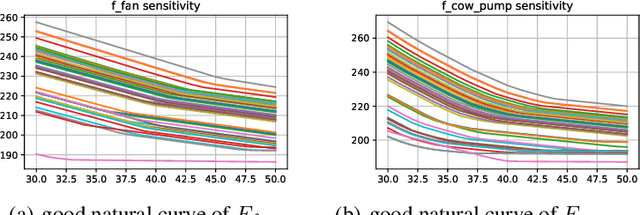
In this paper, we are interested in building a domain knowledge based deep learning framework to solve the chiller plants energy optimization problems. Compared to the hotspot applications of deep learning (e.g. image classification and NLP), it is difficult to collect enormous data for deep network training in real-world physical systems. Most existing methods reduce the complex systems into linear model to facilitate the training on small samples. To tackle the small sample size problem, this paper considers domain knowledge in the structure and loss design of deep network to build a nonlinear model with lower redundancy function space. Specifically, the energy consumption estimation of most chillers can be physically viewed as an input-output monotonic problem. Thus, we can design a Neural Network with monotonic constraints to mimic the physical behavior of the system. We verify the proposed method in a cooling system of a data center, experimental results show the superiority of our framework in energy optimization compared to the existing ones.
Zero-Shot Instance Segmentation
Apr 14, 2021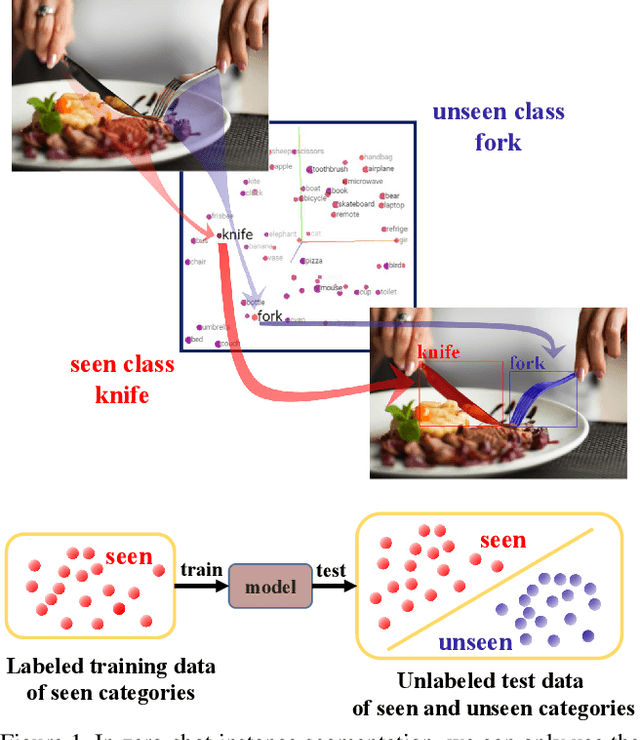
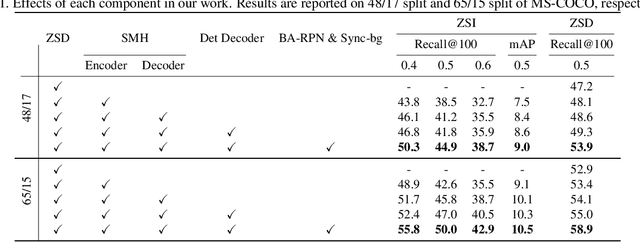
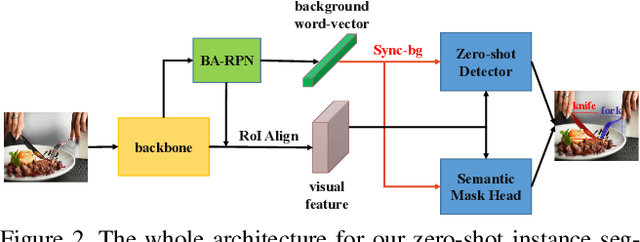
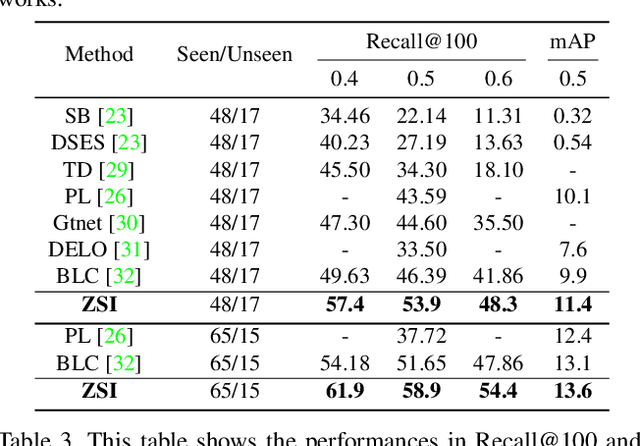
Deep learning has significantly improved the precision of instance segmentation with abundant labeled data. However, in many areas like medical and manufacturing, collecting sufficient data is extremely hard and labeling this data requires high professional skills. We follow this motivation and propose a new task set named zero-shot instance segmentation (ZSI). In the training phase of ZSI, the model is trained with seen data, while in the testing phase, it is used to segment all seen and unseen instances. We first formulate the ZSI task and propose a method to tackle the challenge, which consists of Zero-shot Detector, Semantic Mask Head, Background Aware RPN and Synchronized Background Strategy. We present a new benchmark for zero-shot instance segmentation based on the MS-COCO dataset. The extensive empirical results in this benchmark show that our method not only surpasses the state-of-the-art results in zero-shot object detection task but also achieves promising performance on ZSI. Our approach will serve as a solid baseline and facilitate future research in zero-shot instance segmentation.
Deep Learning in the Era of Edge Computing: Challenges and Opportunities
Oct 17, 2020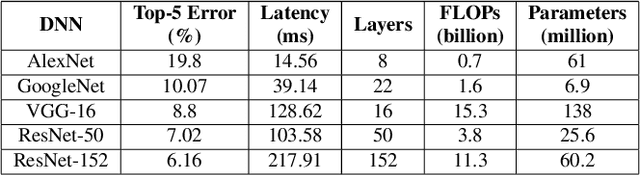

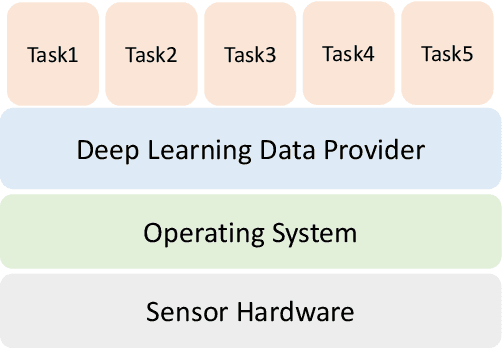
The era of edge computing has arrived. Although the Internet is the backbone of edge computing, its true value lies at the intersection of gathering data from sensors and extracting meaningful information from the sensor data. We envision that in the near future, majority of edge devices will be equipped with machine intelligence powered by deep learning. However, deep learning-based approaches require a large volume of high-quality data to train and are very expensive in terms of computation, memory, and power consumption. In this chapter, we describe eight research challenges and promising opportunities at the intersection of computer systems, networking, and machine learning. Solving those challenges will enable resource-limited edge devices to leverage the amazing capability of deep learning. We hope this chapter could inspire new research that will eventually lead to the realization of the vision of intelligent edge.
AinnoSeg: Panoramic Segmentation with High Perfomance
Jul 21, 2020
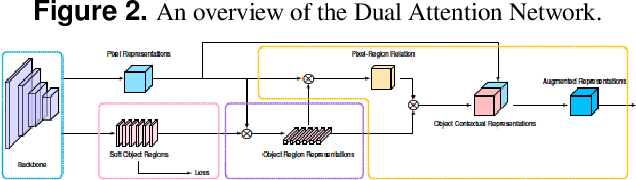

Panoramic segmentation is a scene where image segmentation tasks is more difficult. With the development of CNN networks, panoramic segmentation tasks have been sufficiently developed.However, the current panoramic segmentation algorithms are more concerned with context semantics, but the details of image are not processed enough. Moreover, they cannot solve the problems which contains the accuracy of occluded object segmentation,little object segmentation,boundary pixel in object segmentation etc. Aiming to address these issues, this paper presents some useful tricks. (a) By changing the basic segmentation model, the model can take into account the large objects and the boundary pixel classification of image details. (b) Modify the loss function so that it can take into account the boundary pixels of multiple objects in the image. (c) Use a semi-supervised approach to regain control of the training process. (d) Using multi-scale training and reasoning. All these operations named AinnoSeg, AinnoSeg can achieve state-of-art performance on the well-known dataset ADE20K.
Dynamic Connected Neural Decision Classifier and Regressor with Dynamic Softing Pruning
Nov 20, 2019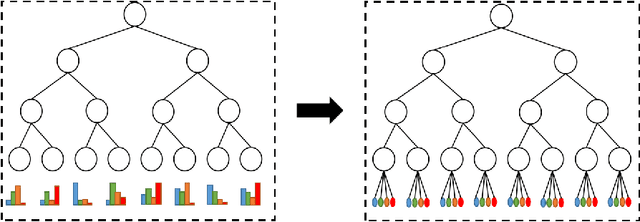
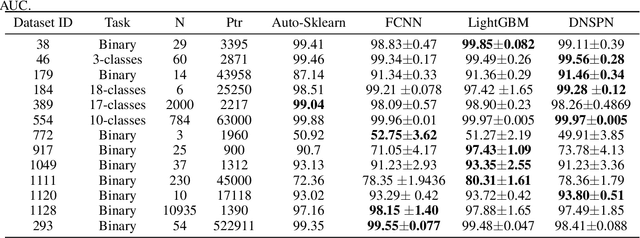
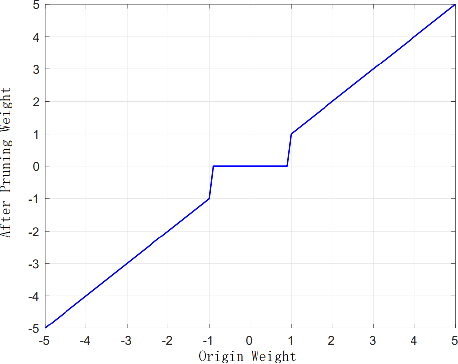
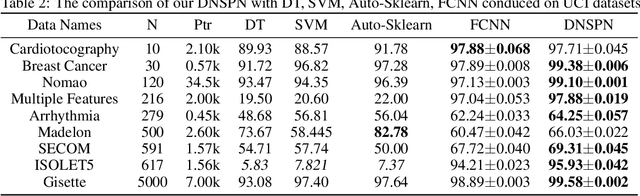
To deal with datasets of different complexity, this paper presents an efficient learning model that combines the proposed Dynamic Connected Neural Decision Networks (DNDN) and a new pruning method--Dynamic Soft Pruning (DSP). DNDN is a combination of random forests and deep neural networks thereby it enjoys both the properties of powerful classification capability and representation learning functionality. Different from Deep Neural Decision Forests (DNDF), this paper adopts an end-to-end training approach by representing the classification distribution with multiple randomly initialized softmax layers, which enables the placement of the forest trees after each layer in the neural network and greatly improves the training speed and stability. Furthermore, DSP is proposed to reduce the redundant connections of the network in a soft fashion which has high flexibility but demonstrates no performance loss compared with previous approaches. Extensive experiments on different datasets demonstrate the superiority of the proposed model over other popular algorithms in solving classification tasks.
Regression via Arbitrary Quantile Modeling
Nov 13, 2019
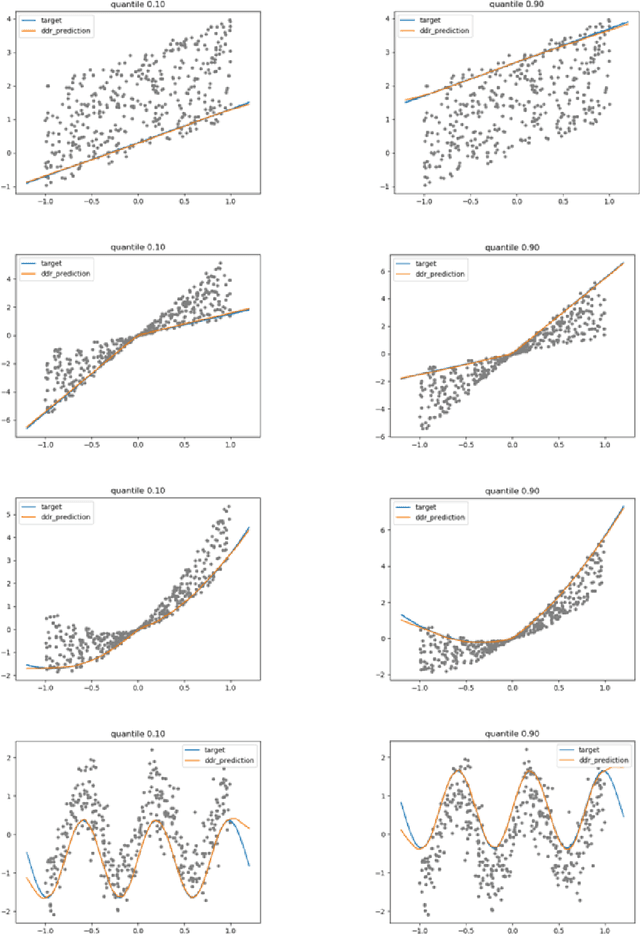
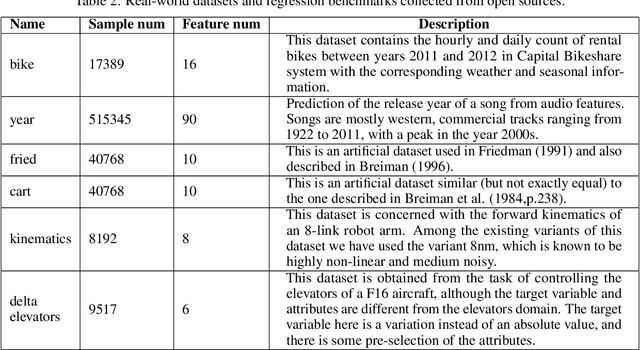

In the regression problem, L1 and L2 are the most commonly used loss functions, which produce mean predictions with different biases. However, the predictions are neither robust nor adequate enough since they only capture a few conditional distributions instead of the whole distribution, especially for small datasets. To address this problem, we proposed arbitrary quantile modeling to regulate the prediction, which achieved better performance compared to traditional loss functions. More specifically, a new distribution regression method, Deep Distribution Regression (DDR), is proposed to estimate arbitrary quantiles of the response variable. Our DDR method consists of two models: a Q model, which predicts the corresponding value for arbitrary quantile, and an F model, which predicts the corresponding quantile for arbitrary value. Furthermore, the duality between Q and F models enables us to design a novel loss function for joint training and perform a dual inference mechanism. Our experiments demonstrate that our DDR-joint and DDR-disjoint methods outperform previous methods such as AdaBoost, random forest, LightGBM, and neural networks both in terms of mean and quantile prediction.