 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent Multimodal Multi-Sensor Fusion-Based UAV Identification, Localization, and Countermeasures for Safeguarding Low-Altitude Economy
Oct 27, 2025The development of the low-altitude economy has led to a growing prominence of uncrewed aerial vehicle (UAV) safety management issues. Therefore, accurate identification, real-time localization, and effective countermeasures have become core challenges in airspace security assurance. This paper introduces an integrated UAV management and control system based on deep learning, which integrates multimodal multi-sensor fusion perception, precise positioning, and collaborative countermeasures. By incorporating deep learning methods, the system combines radio frequency (RF) spectral feature analysis, radar detection, electro-optical identification, and other methods at the detection level to achieve the identification and classification of UAVs. At the localization level, the system relies on multi-sensor data fusion and the air-space-ground integrated communication network to conduct real-time tracking and prediction of UAV flight status, providing support for early warning and decision-making. At the countermeasure level, it adopts comprehensive measures that integrate ``soft kill'' and ``hard kill'', including technologies such as electromagnetic signal jamming, navigation spoofing, and physical interception, to form a closed-loop management and control process from early warning to final disposal, which significantly enhances the response efficiency and disposal accuracy of low-altitude UAV management.
Watch and Learn: Learning to Use Computers from Online Videos
Oct 06, 2025Computer use agents (CUAs) need to plan task workflows grounded in diverse, ever-changing applications and environments, but learning is hindered by the scarcity of large-scale, high-quality training data in the target application. Existing datasets are domain-specific, static, and costly to annotate, while current synthetic data generation methods often yield simplistic or misaligned task demonstrations. To address these limitations, we introduce Watch & Learn (W&L), a framework that converts human demonstration videos readily available on the Internet into executable UI trajectories at scale. Instead of directly generating trajectories or relying on ad hoc reasoning heuristics, we cast the problem as an inverse dynamics objective: predicting the user's action from consecutive screen states. This formulation reduces manual engineering, is easier to learn, and generalizes more robustly across applications. Concretely, we develop an inverse dynamics labeling pipeline with task-aware video retrieval, generate over 53k high-quality trajectories from raw web videos, and demonstrate that these trajectories improve CUAs both as in-context demonstrations and as supervised training data. On the challenging OSWorld benchmark, UI trajectories extracted with W&L consistently enhance both general-purpose and state-of-the-art frameworks in-context, and deliver stronger gains for open-source models under supervised training. These results highlight web-scale human demonstration videos as a practical and scalable foundation for advancing CUAs towards real-world deployment.
Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge
Jun 26, 2025



Agentic search such as Deep Research systems, where large language models autonomously browse the web, synthesize information, and return comprehensive citation-backed answers, represents a major shift in how users interact with web-scale information. While promising greater efficiency and cognitive offloading, the growing complexity and open-endedness of agentic search have outpaced existing evaluation benchmarks and methodologies, which largely assume short search horizons and static answers. In this paper, we introduce Mind2Web 2, a benchmark of 130 realistic, high-quality, and long-horizon tasks that require real-time web browsing and extensive information synthesis, constructed with over 1,000 hours of human labor. To address the challenge of evaluating time-varying and complex answers, we propose a novel Agent-as-a-Judge framework. Our method constructs task-specific judge agents based on a tree-structured rubric design to automatically assess both answer correctness and source attribution. We conduct a comprehensive evaluation of nine frontier agentic search systems and human performance, along with a detailed error analysis to draw insights for future development. The best-performing system, OpenAI Deep Research, can already achieve 50-70% of human performance while spending half the time, showing a great potential. Altogether, Mind2Web 2 provides a rigorous foundation for developing and benchmarking the next generation of agentic search systems.
OPeRA: A Dataset of Observation, Persona, Rationale, and Action for Evaluating LLMs on Human Online Shopping Behavior Simulation
Jun 05, 2025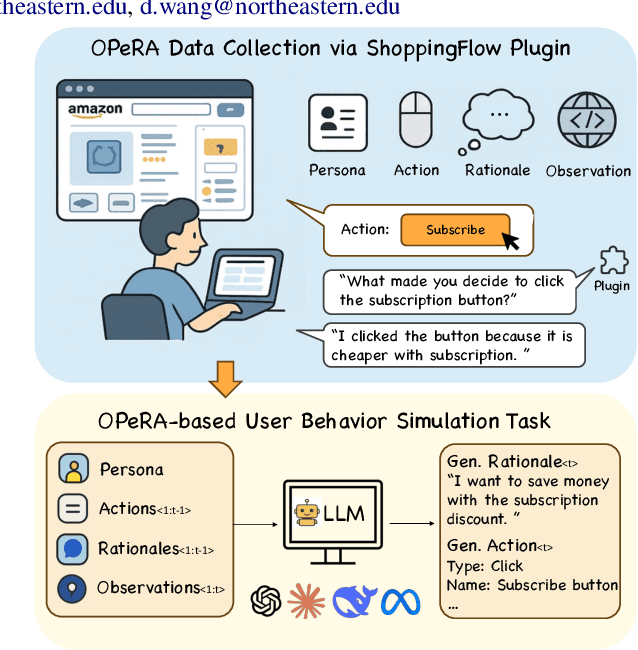
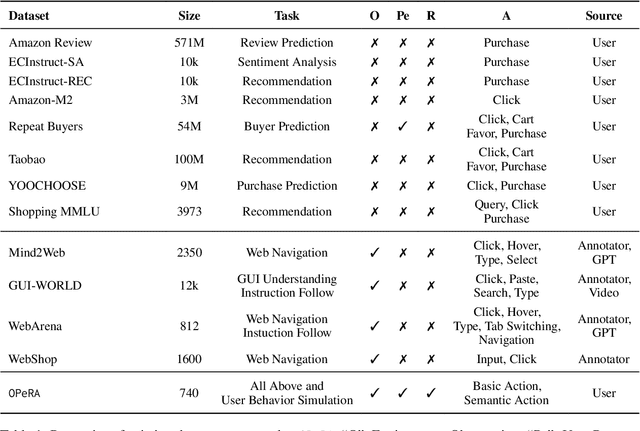
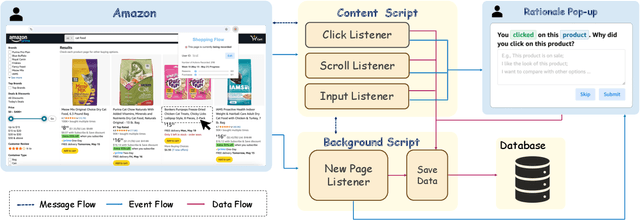
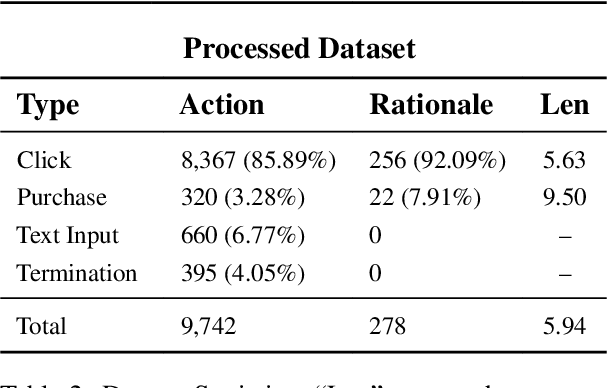
Can large language models (LLMs) accurately simulate the next web action of a specific user? While LLMs have shown promising capabilities in generating ``believable'' human behaviors, evaluating their ability to mimic real user behaviors remains an open challenge, largely due to the lack of high-quality, publicly available datasets that capture both the observable actions and the internal reasoning of an actual human user. To address this gap, we introduce OPERA, a novel dataset of Observation, Persona, Rationale, and Action collected from real human participants during online shopping sessions. OPERA is the first public dataset that comprehensively captures: user personas, browser observations, fine-grained web actions, and self-reported just-in-time rationales. We developed both an online questionnaire and a custom browser plugin to gather this dataset with high fidelity. Using OPERA, we establish the first benchmark to evaluate how well current LLMs can predict a specific user's next action and rationale with a given persona and <observation, action, rationale> history. This dataset lays the groundwork for future research into LLM agents that aim to act as personalized digital twins for human.
BioCLIP 2: Emergent Properties from Scaling Hierarchical Contrastive Learning
May 29, 2025



Foundation models trained at scale exhibit remarkable emergent behaviors, learning new capabilities beyond their initial training objectives. We find such emergent behaviors in biological vision models via large-scale contrastive vision-language training. To achieve this, we first curate TreeOfLife-200M, comprising 214 million images of living organisms, the largest and most diverse biological organism image dataset to date. We then train BioCLIP 2 on TreeOfLife-200M to distinguish different species. Despite the narrow training objective, BioCLIP 2 yields extraordinary accuracy when applied to various biological visual tasks such as habitat classification and trait prediction. We identify emergent properties in the learned embedding space of BioCLIP 2. At the inter-species level, the embedding distribution of different species aligns closely with functional and ecological meanings (e.g., beak sizes and habitats). At the intra-species level, instead of being diminished, the intra-species variations (e.g., life stages and sexes) are preserved and better separated in subspaces orthogonal to inter-species distinctions. We provide formal proof and analyses to explain why hierarchical supervision and contrastive objectives encourage these emergent properties. Crucially, our results reveal that these properties become increasingly significant with larger-scale training data, leading to a biologically meaningful embedding space.
RedTeamCUA: Realistic Adversarial Testing of Computer-Use Agents in Hybrid Web-OS Environments
May 28, 2025Computer-use agents (CUAs) promise to automate complex tasks across operating systems (OS) and the web, but remain vulnerable to indirect prompt injection. Current evaluations of this threat either lack support realistic but controlled environments or ignore hybrid web-OS attack scenarios involving both interfaces. To address this, we propose RedTeamCUA, an adversarial testing framework featuring a novel hybrid sandbox that integrates a VM-based OS environment with Docker-based web platforms. Our sandbox supports key features tailored for red teaming, such as flexible adversarial scenario configuration, and a setting that decouples adversarial evaluation from navigational limitations of CUAs by initializing tests directly at the point of an adversarial injection. Using RedTeamCUA, we develop RTC-Bench, a comprehensive benchmark with 864 examples that investigate realistic, hybrid web-OS attack scenarios and fundamental security vulnerabilities. Benchmarking current frontier CUAs identifies significant vulnerabilities: Claude 3.7 Sonnet | CUA demonstrates an ASR of 42.9%, while Operator, the most secure CUA evaluated, still exhibits an ASR of 7.6%. Notably, CUAs often attempt to execute adversarial tasks with an Attempt Rate as high as 92.5%, although failing to complete them due to capability limitations. Nevertheless, we observe concerning ASRs of up to 50% in realistic end-to-end settings, with the recently released frontier Claude 4 Opus | CUA showing an alarming ASR of 48%, demonstrating that indirect prompt injection presents tangible risks for even advanced CUAs despite their capabilities and safeguards. Overall, RedTeamCUA provides an essential framework for advancing realistic, controlled, and systematic analysis of CUA vulnerabilities, highlighting the urgent need for robust defenses to indirect prompt injection prior to real-world deployment.
ARM: Adaptive Reasoning Model
May 26, 2025



While large reasoning models demonstrate strong performance on complex tasks, they lack the ability to adjust reasoning token usage based on task difficulty. This often leads to the "overthinking" problem -- excessive and unnecessary reasoning -- which, although potentially mitigated by human intervention to control the token budget, still fundamentally contradicts the goal of achieving fully autonomous AI. In this work, we propose Adaptive Reasoning Model (ARM), a reasoning model capable of adaptively selecting appropriate reasoning formats based on the task at hand. These formats include three efficient ones -- Direct Answer, Short CoT, and Code -- as well as a more elaborate format, Long CoT. To train ARM, we introduce Ada-GRPO, an adaptation of Group Relative Policy Optimization (GRPO), which addresses the format collapse issue in traditional GRPO. Ada-GRPO enables ARM to achieve high token efficiency, reducing tokens by an average of 30%, and up to 70%, while maintaining performance comparable to the model that relies solely on Long CoT. Furthermore, not only does it improve inference efficiency through reduced token generation, but it also brings a 2x speedup in training. In addition to the default Adaptive Mode, ARM supports two additional reasoning modes: 1) Instruction-Guided Mode, which allows users to explicitly specify the reasoning format via special tokens -- ideal when the appropriate format is known for a batch of tasks. 2) Consensus-Guided Mode, which aggregates the outputs of the three efficient formats and resorts to Long CoT in case of disagreement, prioritizing performance with higher token usage.
Confidence in Large Language Model Evaluation: A Bayesian Approach to Limited-Sample Challenges
Apr 30, 2025


Large language models (LLMs) exhibit probabilistic output characteristics, yet conventional evaluation frameworks rely on deterministic scalar metrics. This study introduces a Bayesian approach for LLM capability assessment that integrates prior knowledge through probabilistic inference, addressing limitations under limited-sample regimes. By treating model capabilities as latent variables and leveraging a curated query set to induce discriminative responses, we formalize model ranking as a Bayesian hypothesis testing problem over mutually exclusive capability intervals. Experimental evaluations with GPT-series models demonstrate that the proposed method achieves superior discrimination compared to conventional evaluation methods. Results indicate that even with reduced sample sizes, the approach maintains statistical robustness while providing actionable insights, such as probabilistic statements about a model's likelihood of surpassing specific baselines. This work advances LLM evaluation methodologies by bridging Bayesian inference with practical constraints in real-world deployment scenarios.
MICE for CATs: Model-Internal Confidence Estimation for Calibrating Agents with Tools
Apr 28, 2025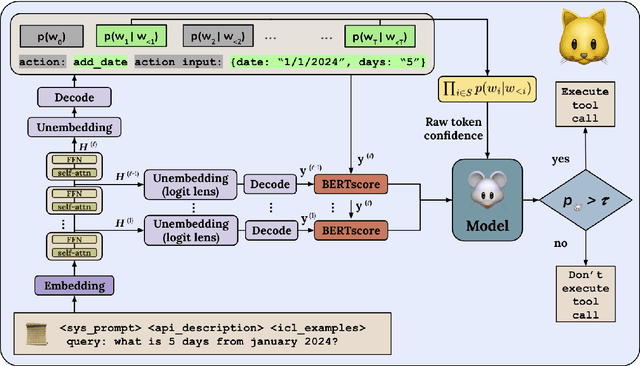
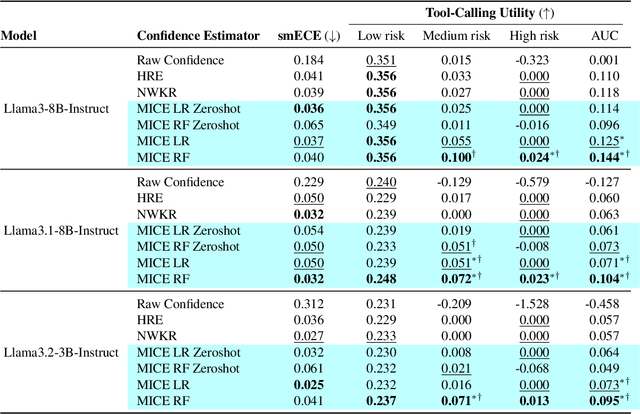

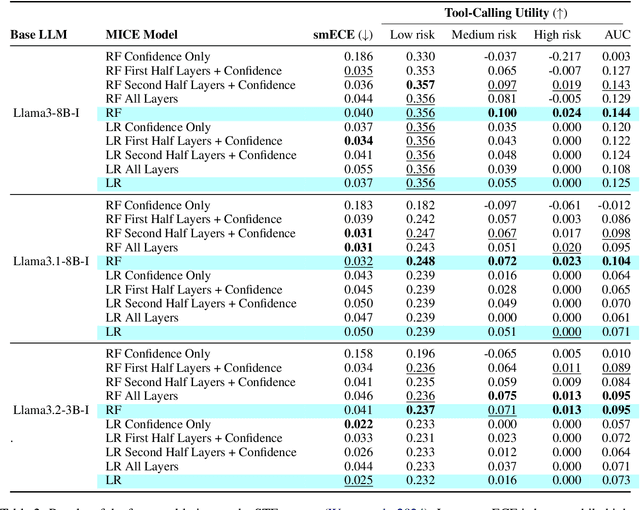
Tool-using agents that act in the world need to be both useful and safe. Well-calibrated model confidences can be used to weigh the risk versus reward of potential actions, but prior work shows that many models are poorly calibrated. Inspired by interpretability literature exploring the internals of models, we propose a novel class of model-internal confidence estimators (MICE) to better assess confidence when calling tools. MICE first decodes from each intermediate layer of the language model using logitLens and then computes similarity scores between each layer's generation and the final output. These features are fed into a learned probabilistic classifier to assess confidence in the decoded output. On the simulated trial and error (STE) tool-calling dataset using Llama3 models, we find that MICE beats or matches the baselines on smoothed expected calibration error. Using MICE confidences to determine whether to call a tool significantly improves over strong baselines on a new metric, expected tool-calling utility. Further experiments show that MICE is sample-efficient, can generalize zero-shot to unseen APIs, and results in higher tool-calling utility in scenarios with varying risk levels. Our code is open source, available at https://github.com/microsoft/mice_for_cats.
Completing A Systematic Review in Hours instead of Months with Interactive AI Agents
Apr 21, 2025Systematic reviews (SRs) are vital for evidence-based practice in high stakes disciplines, such as healthcare, but are often impeded by intensive labors and lengthy processes that can take months to complete. Due to the high demand for domain expertise, existing automatic summarization methods fail to accurately identify relevant studies and generate high-quality summaries. To that end, we introduce InsightAgent, a human-centered interactive AI agent powered by large language models that revolutionize this workflow. InsightAgent partitions a large literature corpus based on semantics and employs a multi-agent design for more focused processing of literature, leading to significant improvement in the quality of generated SRs. InsightAgent also provides intuitive visualizations of the corpus and agent trajectories, allowing users to effortlessly monitor the actions of the agent and provide real-time feedback based on their expertise. Our user studies with 9 medical professionals demonstrate that the visualization and interaction mechanisms can effectively improve the quality of synthesized SRs by 27.2%, reaching 79.7% of human-written quality. At the same time, user satisfaction is improved by 34.4%. With InsightAgent, it only takes a clinician about 1.5 hours, rather than months, to complete a high-quality systematic review.