 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Good Enough Is Optimal: Multiplication-Only Matrix Inversion Approximation for Quantized Gated DeltaNet
Jun 04, 2026Matrix inversion in chunk-wise parallel linear attention is a major bottleneck for long-context modeling, particularly on NPUs, where forward-substitution-based methods exhibit limited parallelism and poor hardware utilization. We propose a fast, Matrix Multiplication (MatMul)-based algorithm tailored for strictly lower-triangular matrices arising in chunk-wise linear attention. Motivated by the rapid growth of Neumann-series terms and the diagonal concentration of the inverse matrix, we employ a truncated Neumann expansion with structural masking and parallel residual correction to eliminate sequential dependencies. We further extend our method to low-bits INT by mitigating the dynamic range expansion arising from repeated matrix power operations, and adapt the approximation order and residual step to the chunk size to minimize computational cost while preserving the model's accuracy. Experiments on Qwen3.5-family models demonstrate up to 5$\times$ kernel-level speedup and a 20% reduction in decode-layer overhead, while preserving accuracy under both floating-point and low-precision inference. Our method offers an efficient and hardware-friendly solution for scalable linear attention.
Training a Student Expert via Semi-Supervised Foundation Model Distillation
Apr 04, 2026Foundation models deliver strong perception but are often too computationally heavy to deploy, and adapting them typically requires costly annotations. We introduce a semi-supervised knowledge distillation (SSKD) framework that compresses pre-trained vision foundation models (VFMs) into compact experts using limited labeled and abundant unlabeled data, and instantiate it for instance segmentation where per-pixel labels are particularly expensive. The framework unfolds in three stages: (1) domain adaptation of the VFM(s) via self-training with contrastive calibration, (2) knowledge transfer through a unified multi-objective loss, and (3) student refinement to mitigate residual pseudo-label bias. Central to our approach is an instance-aware pixel-wise contrastive loss that fuses mask and class scores to extract informative negatives and enforce clear inter-instance margins. By maintaining this contrastive signal across both adaptation and distillation, we align teacher and student embeddings and more effectively leverage unlabeled images. On Cityscapes and ADE20K, our $\approx 11\times$ smaller student improves over its zero-shot VFM teacher(s) by +11.9 and +8.6 AP, surpasses adapted teacher(s) by +3.4 and +1.5 AP, and outperforms state-of-the-art SSKD methods on benchmarks.
E-Navi: Environmental Adaptive Navigation for UAVs on Resource Constrained Platforms
Dec 16, 2025
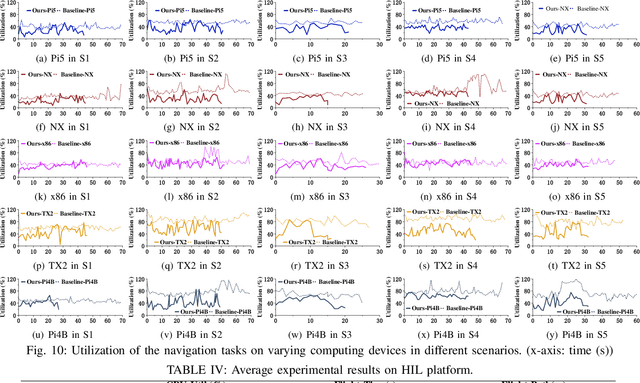
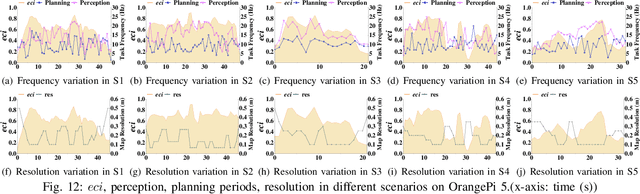
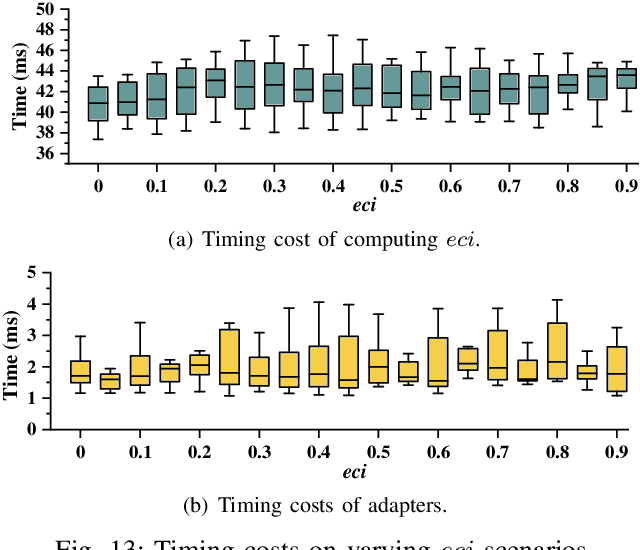
The ability to adapt to changing environments is crucial for the autonomous navigation systems of Unmanned Aerial Vehicles (UAVs). However, existing navigation systems adopt fixed execution configurations without considering environmental dynamics based on available computing resources, e.g., with a high execution frequency and task workload. This static approach causes rigid flight strategies and excessive computations, ultimately degrading flight performance or even leading to failures in UAVs. Despite the necessity for an adaptive system, dynamically adjusting workloads remains challenging, due to difficulties in quantifying environmental complexity and modeling the relationship between environment and system configuration. Aiming at adapting to dynamic environments, this paper proposes E-Navi, an environmental-adaptive navigation system for UAVs that dynamically adjusts task executions on the CPUs in response to environmental changes based on available computational resources. Specifically, the perception-planning pipeline of UAVs navigation system is redesigned through dynamic adaptation of mapping resolution and execution frequency, driven by the quantitative environmental complexity evaluations. In addition, E-Navi supports flexible deployment across hardware platforms with varying levels of computing capability. Extensive Hardware-In-the-Loop and real-world experiments demonstrate that the proposed system significantly outperforms the baseline method across various hardware platforms, achieving up to 53.9% navigation task workload reduction, up to 63.8% flight time savings, and delivering more stable velocity control.
Solving Semi-Supervised Few-Shot Learning from an Auto-Annotation Perspective
Dec 11, 2025



Semi-supervised few-shot learning (SSFSL) formulates real-world applications like ''auto-annotation'', as it aims to learn a model over a few labeled and abundant unlabeled examples to annotate the unlabeled ones. Despite the availability of powerful open-source Vision-Language Models (VLMs) and their pretraining data, the SSFSL literature largely neglects these open-source resources. In contrast, the related area few-shot learning (FSL) has already exploited them to boost performance. Arguably, to achieve auto-annotation in the real world, SSFSL should leverage such open-source resources. To this end, we start by applying established SSL methods to finetune a VLM. Counterintuitively, they significantly underperform FSL baselines. Our in-depth analysis reveals the root cause: VLMs produce rather ''flat'' distributions of softmax probabilities. This results in zero utilization of unlabeled data and weak supervision signals. We address this issue with embarrassingly simple techniques: classifier initialization and temperature tuning. They jointly increase the confidence scores of pseudo-labels, improving the utilization rate of unlabeled data, and strengthening supervision signals. Building on this, we propose: Stage-Wise Finetuning with Temperature Tuning (SWIFT), which enables existing SSL methods to effectively finetune a VLM on limited labeled data, abundant unlabeled data, and task-relevant but noisy data retrieved from the VLM's pretraining set. Extensive experiments on five SSFSL benchmarks show that SWIFT outperforms recent FSL and SSL methods by $\sim$5 accuracy points. SWIFT even rivals supervised learning, which finetunes VLMs with the unlabeled data being labeled with ground truth!
Surely Large Multimodal Models (Don't) Excel in Visual Species Recognition?
Dec 10, 2025



Visual Species Recognition (VSR) is pivotal to biodiversity assessment and conservation, evolution research, and ecology and ecosystem management. Training a machine-learned model for VSR typically requires vast amounts of annotated images. Yet, species-level annotation demands domain expertise, making it realistic for domain experts to annotate only a few examples. These limited labeled data motivate training an ''expert'' model via few-shot learning (FSL). Meanwhile, advanced Large Multimodal Models (LMMs) have demonstrated prominent performance on general recognition tasks. It is straightforward to ask whether LMMs excel in the highly specialized VSR task and whether they outshine FSL expert models. Somewhat surprisingly, we find that LMMs struggle in this task, despite using various established prompting techniques. LMMs even significantly underperform FSL expert models, which are as simple as finetuning a pretrained visual encoder on the few-shot images. However, our in-depth analysis reveals that LMMs can effectively post-hoc correct the expert models' incorrect predictions. Briefly, given a test image, when prompted with the top predictions from an FSL expert model, LMMs can recover the ground-truth label. Building on this insight, we derive a simple method called Post-hoc Correction (POC), which prompts an LMM to re-rank the expert model's top predictions using enriched prompts that include softmax confidence scores and few-shot visual examples. Across five challenging VSR benchmarks, POC outperforms prior art of FSL by +6.4% in accuracy without extra training, validation, or manual intervention. Importantly, POC generalizes to different pretrained backbones and LMMs, serving as a plug-and-play module to significantly enhance existing FSL methods.
Combining Reinforcement Learning and Behavior Trees for NPCs in Video Games with AMD Schola
Oct 15, 2025While the rapid advancements in the reinforcement learning (RL) research community have been remarkable, the adoption in commercial video games remains slow. In this paper, we outline common challenges the Game AI community faces when using RL-driven NPCs in practice, and highlight the intersection of RL with traditional behavior trees (BTs) as a crucial juncture to be explored further. Although the BT+RL intersection has been suggested in several research papers, its adoption is rare. We demonstrate the viability of this approach using AMD Schola -- a plugin for training RL agents in Unreal Engine -- by creating multi-task NPCs in a complex 3D environment inspired by the commercial video game ``The Last of Us". We provide detailed methodologies for jointly training RL models with BTs while showcasing various skills.
Hunyuan3D Studio: End-to-End AI Pipeline for Game-Ready 3D Asset Generation
Sep 16, 2025



The creation of high-quality 3D assets, a cornerstone of modern game development, has long been characterized by labor-intensive and specialized workflows. This paper presents Hunyuan3D Studio, an end-to-end AI-powered content creation platform designed to revolutionize the game production pipeline by automating and streamlining the generation of game-ready 3D assets. At its core, Hunyuan3D Studio integrates a suite of advanced neural modules (such as Part-level 3D Generation, Polygon Generation, Semantic UV, etc.) into a cohesive and user-friendly system. This unified framework allows for the rapid transformation of a single concept image or textual description into a fully-realized, production-quality 3D model complete with optimized geometry and high-fidelity PBR textures. We demonstrate that assets generated by Hunyuan3D Studio are not only visually compelling but also adhere to the stringent technical requirements of contemporary game engines, significantly reducing iteration time and lowering the barrier to entry for 3D content creation. By providing a seamless bridge from creative intent to technical asset, Hunyuan3D Studio represents a significant leap forward for AI-assisted workflows in game development and interactive media.
HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
Jul 29, 2025



Creating immersive and playable 3D worlds from texts or images remains a fundamental challenge in computer vision and graphics. Existing world generation approaches typically fall into two categories: video-based methods that offer rich diversity but lack 3D consistency and rendering efficiency, and 3D-based methods that provide geometric consistency but struggle with limited training data and memory-inefficient representations. To address these limitations, we present HunyuanWorld 1.0, a novel framework that combines the best of both worlds for generating immersive, explorable, and interactive 3D scenes from text and image conditions. Our approach features three key advantages: 1) 360{\deg} immersive experiences via panoramic world proxies; 2) mesh export capabilities for seamless compatibility with existing computer graphics pipelines; 3) disentangled object representations for augmented interactivity. The core of our framework is a semantically layered 3D mesh representation that leverages panoramic images as 360{\deg} world proxies for semantic-aware world decomposition and reconstruction, enabling the generation of diverse 3D worlds. Extensive experiments demonstrate that our method achieves state-of-the-art performance in generating coherent, explorable, and interactive 3D worlds while enabling versatile applications in virtual reality, physical simulation, game development, and interactive content creation.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.
Robust Few-Shot Vision-Language Model Adaptation
Jun 05, 2025Pretrained VLMs achieve strong performance on downstream tasks when adapted with just a few labeled examples. As the adapted models inevitably encounter out-of-distribution (OOD) test data that deviates from the in-distribution (ID) task-specific training data, enhancing OOD generalization in few-shot adaptation is critically important. We study robust few-shot VLM adaptation, aiming to increase both ID and OOD accuracy. By comparing different adaptation methods (e.g., prompt tuning, linear probing, contrastive finetuning, and full finetuning), we uncover three key findings: (1) finetuning with proper hyperparameters significantly outperforms the popular VLM adaptation methods prompt tuning and linear probing; (2) visual encoder-only finetuning achieves better efficiency and accuracy than contrastively finetuning both visual and textual encoders; (3) finetuning the top layers of the visual encoder provides the best balance between ID and OOD accuracy. Building on these findings, we propose partial finetuning of the visual encoder empowered with two simple augmentation techniques: (1) retrieval augmentation which retrieves task-relevant data from the VLM's pretraining dataset to enhance adaptation, and (2) adversarial perturbation which promotes robustness during finetuning. Results show that the former/latter boosts OOD/ID accuracy while slightly sacrificing the ID/OOD accuracy. Yet, perhaps understandably, naively combining the two does not maintain their best OOD/ID accuracy. We address this dilemma with the developed SRAPF, Stage-wise Retrieval Augmentation-based Adversarial Partial Finetuning. SRAPF consists of two stages: (1) partial finetuning the visual encoder using both ID and retrieved data, and (2) adversarial partial finetuning with few-shot ID data. Extensive experiments demonstrate that SRAPF achieves the state-of-the-art ID and OOD accuracy on the ImageNet OOD benchmarks.