 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Far Looks Up: Probing Spatial Representation in Vision-Language Models
May 28, 2026Vision-language models (VLMs) achieve strong performance on spatial reasoning benchmarks, yet it remains unclear whether this reflects structured 3D understanding or reliance on statistical shortcuts in natural images. We introduce a representation-level analysis framework that constructs minimal contrastive pairs to measure how spatial axes are organized and disentangled within VLM embeddings. Our analysis across multiple model families reveals a consistent vertical-distance entanglement: models conflate vertical image position with distance, mirroring the perspective bias of natural photographs. This bias produces a significant accuracy gap between perspective-consistent and counter-heuristic examples, and intensifies under data scaling even as overall benchmark accuracy improves. We further show that models with similar benchmark scores can exhibit different internal representations, and that these differences predict accuracy and robustness across diverse spatial reasoning benchmarks. To isolate this bias from evaluation-set skew, we introduce SpatialTunnel, a synthetic benchmark designed to expose spatial shortcut biases by removing common correlations present in natural images. Experiments confirm that the entanglement is model-intrinsic, and that models with well-separated spatial axes exhibit greater robustness, suggesting that well-structured spatial representations lead to more reliable spatial reasoning across diverse benchmarks. Code and benchmark are available on the project page: https://cheolhong0916.github.io/whyfarlooksup.github.io/.
WebGraphEval: Multi-Turn Trajectory Evaluation for Web Agents using Graph Representation
Oct 22, 2025Current evaluation of web agents largely reduces to binary success metrics or conformity to a single reference trajectory, ignoring the structural diversity present in benchmark datasets. We present WebGraphEval, a framework that abstracts trajectories from multiple agents into a unified, weighted action graph. This representation is directly compatible with benchmarks such as WebArena, leveraging leaderboard runs and newly collected trajectories without modifying environments. The framework canonically encodes actions, merges recurring behaviors, and applies structural analyses including reward propagation and success-weighted edge statistics. Evaluations across thousands of trajectories from six web agents show that the graph abstraction captures cross-model regularities, highlights redundancy and inefficiency, and identifies critical decision points overlooked by outcome-based metrics. By framing web interaction as graph-structured data, WebGraphEval establishes a general methodology for multi-path, cross-agent, and efficiency-aware evaluation of web agents.
Watch and Learn: Learning to Use Computers from Online Videos
Oct 06, 2025Computer use agents (CUAs) need to plan task workflows grounded in diverse, ever-changing applications and environments, but learning is hindered by the scarcity of large-scale, high-quality training data in the target application. Existing datasets are domain-specific, static, and costly to annotate, while current synthetic data generation methods often yield simplistic or misaligned task demonstrations. To address these limitations, we introduce Watch & Learn (W&L), a framework that converts human demonstration videos readily available on the Internet into executable UI trajectories at scale. Instead of directly generating trajectories or relying on ad hoc reasoning heuristics, we cast the problem as an inverse dynamics objective: predicting the user's action from consecutive screen states. This formulation reduces manual engineering, is easier to learn, and generalizes more robustly across applications. Concretely, we develop an inverse dynamics labeling pipeline with task-aware video retrieval, generate over 53k high-quality trajectories from raw web videos, and demonstrate that these trajectories improve CUAs both as in-context demonstrations and as supervised training data. On the challenging OSWorld benchmark, UI trajectories extracted with W&L consistently enhance both general-purpose and state-of-the-art frameworks in-context, and deliver stronger gains for open-source models under supervised training. These results highlight web-scale human demonstration videos as a practical and scalable foundation for advancing CUAs towards real-world deployment.
Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge
Jun 26, 2025



Agentic search such as Deep Research systems, where large language models autonomously browse the web, synthesize information, and return comprehensive citation-backed answers, represents a major shift in how users interact with web-scale information. While promising greater efficiency and cognitive offloading, the growing complexity and open-endedness of agentic search have outpaced existing evaluation benchmarks and methodologies, which largely assume short search horizons and static answers. In this paper, we introduce Mind2Web 2, a benchmark of 130 realistic, high-quality, and long-horizon tasks that require real-time web browsing and extensive information synthesis, constructed with over 1,000 hours of human labor. To address the challenge of evaluating time-varying and complex answers, we propose a novel Agent-as-a-Judge framework. Our method constructs task-specific judge agents based on a tree-structured rubric design to automatically assess both answer correctness and source attribution. We conduct a comprehensive evaluation of nine frontier agentic search systems and human performance, along with a detailed error analysis to draw insights for future development. The best-performing system, OpenAI Deep Research, can already achieve 50-70% of human performance while spending half the time, showing a great potential. Altogether, Mind2Web 2 provides a rigorous foundation for developing and benchmarking the next generation of agentic search systems.
An Illusion of Progress? Assessing the Current State of Web Agents
Apr 02, 2025
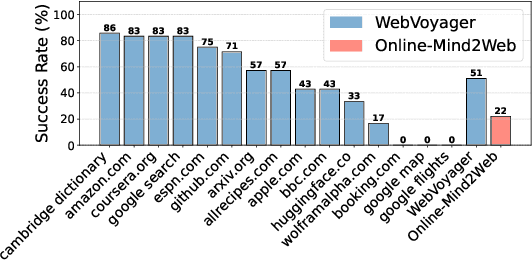

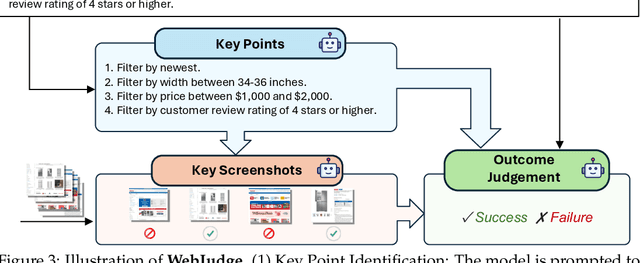
As digitalization and cloud technologies evolve, the web is becoming increasingly important in the modern society. Autonomous web agents based on large language models (LLMs) hold a great potential in work automation. It is therefore important to accurately measure and monitor the progression of their capabilities. In this work, we conduct a comprehensive and rigorous assessment of the current state of web agents. Our results depict a very different picture of the competency of current agents, suggesting over-optimism in previously reported results. This gap can be attributed to shortcomings in existing benchmarks. We introduce Online-Mind2Web, an online evaluation benchmark consisting of 300 diverse and realistic tasks spanning 136 websites. It enables us to evaluate web agents under a setting that approximates how real users use these agents. To facilitate more scalable evaluation and development, we also develop a novel LLM-as-a-Judge automatic evaluation method and show that it can achieve around 85% agreement with human judgment, substantially higher than existing methods. Finally, we present the first comprehensive comparative analysis of current web agents, highlighting both their strengths and limitations to inspire future research.
RoboSpatial: Teaching Spatial Understanding to 2D and 3D Vision-Language Models for Robotics
Nov 25, 2024



Spatial understanding is a crucial capability for robots to make grounded decisions based on their environment. This foundational skill enables robots not only to perceive their surroundings but also to reason about and interact meaningfully within the world. In modern robotics, these capabilities are taken on by visual language models, and they face significant challenges when applied to spatial reasoning context due to their training data sources. These sources utilize general-purpose image datasets, and they often lack sophisticated spatial scene understanding capabilities. For example, the datasets do not address reference frame comprehension - spatial relationships require clear contextual understanding, whether from an ego-centric, object-centric, or world-centric perspective, which allow for effective real-world interaction. To address this issue, we introduce RoboSpatial, a large-scale spatial understanding dataset consisting of real indoor and tabletop scenes captured as 3D scans and egocentric images, annotated with rich spatial information relevant to robotics. The dataset includes 1M images, 5K 3D scans, and 3M annotated spatial relationships, with paired 2D egocentric images and 3D scans to make it both 2D and 3D ready. Our experiments show that models trained with RoboSpatial outperform baselines on downstream tasks such as spatial affordance prediction, spatial relationship prediction, and robotics manipulation.
VisualAgentBench: Towards Large Multimodal Models as Visual Foundation Agents
Aug 12, 2024



Large Multimodal Models (LMMs) have ushered in a new era in artificial intelligence, merging capabilities in both language and vision to form highly capable Visual Foundation Agents. These agents are postulated to excel across a myriad of tasks, potentially approaching general artificial intelligence. However, existing benchmarks fail to sufficiently challenge or showcase the full potential of LMMs in complex, real-world environments. To address this gap, we introduce VisualAgentBench (VAB), a comprehensive and pioneering benchmark specifically designed to train and evaluate LMMs as visual foundation agents across diverse scenarios, including Embodied, Graphical User Interface, and Visual Design, with tasks formulated to probe the depth of LMMs' understanding and interaction capabilities. Through rigorous testing across nine proprietary LMM APIs and eight open models, we demonstrate the considerable yet still developing agent capabilities of these models. Additionally, VAB constructs a trajectory training set constructed through hybrid methods including Program-based Solvers, LMM Agent Bootstrapping, and Human Demonstrations, promoting substantial performance improvements in LMMs through behavior cloning. Our work not only aims to benchmark existing models but also provides a solid foundation for future development into visual foundation agents. Code, train \& test data, and part of fine-tuned open LMMs are available at \url{https://github.com/THUDM/VisualAgentBench}.
Dual-View Visual Contextualization for Web Navigation
Feb 06, 2024



Automatic web navigation aims to build a web agent that can follow language instructions to execute complex and diverse tasks on real-world websites. Existing work primarily takes HTML documents as input, which define the contents and action spaces (i.e., actionable elements and operations) of webpages. Nevertheless, HTML documents may not provide a clear task-related context for each element, making it hard to select the right (sequence of) actions. In this paper, we propose to contextualize HTML elements through their "dual views" in webpage screenshots: each HTML element has its corresponding bounding box and visual content in the screenshot. We build upon the insight -- web developers tend to arrange task-related elements nearby on webpages to enhance user experiences -- and propose to contextualize each element with its neighbor elements, using both textual and visual features. The resulting representations of HTML elements are more informative for the agent to take action. We validate our method on the recently released Mind2Web dataset, which features diverse navigation domains and tasks on real-world websites. Our method consistently outperforms the baseline in all the scenarios, including cross-task, cross-website, and cross-domain ones.
BioCLIP: A Vision Foundation Model for the Tree of Life
Dec 04, 2023



Images of the natural world, collected by a variety of cameras, from drones to individual phones, are increasingly abundant sources of biological information. There is an explosion of computational methods and tools, particularly computer vision, for extracting biologically relevant information from images for science and conservation. Yet most of these are bespoke approaches designed for a specific task and are not easily adaptable or extendable to new questions, contexts, and datasets. A vision model for general organismal biology questions on images is of timely need. To approach this, we curate and release TreeOfLife-10M, the largest and most diverse ML-ready dataset of biology images. We then develop BioCLIP, a foundation model for the tree of life, leveraging the unique properties of biology captured by TreeOfLife-10M, namely the abundance and variety of images of plants, animals, and fungi, together with the availability of rich structured biological knowledge. We rigorously benchmark our approach on diverse fine-grained biology classification tasks, and find that BioCLIP consistently and substantially outperforms existing baselines (by 17% to 20% absolute). Intrinsic evaluation reveals that BioCLIP has learned a hierarchical representation conforming to the tree of life, shedding light on its strong generalizability. Our code, models and data will be made available at https://github.com/Imageomics/bioclip.
LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models
Dec 08, 2022



This study focuses on embodied agents that can follow natural language instructions to complete complex tasks in a visually-perceived environment. Existing methods rely on a large amount of (instruction, gold trajectory) pairs to learn a good policy. The high data cost and poor sample efficiency prevents the development of versatile agents that are capable of many tasks and can learn new tasks quickly. In this work, we propose a novel method, LLM-Planner, that harnesses the power of large language models (LLMs) such as GPT-3 to do few-shot planning for embodied agents. We further propose a simple but effective way to enhance LLMs with physical grounding to generate plans that are grounded in the current environment. Experiments on the ALFRED dataset show that our method can achieve very competitive few-shot performance, even outperforming several recent baselines that are trained using the full training data despite using less than 0.5% of paired training data. Existing methods can barely complete any task successfully under the same few-shot setting. Our work opens the door for developing versatile and sample-efficient embodied agents that can quickly learn many tasks.